Decoding intermediate activations in llama-2-7b
Produced as part of the SERI ML Alignment Theory Scholars Program—Summer 2023 Cohort
Existing research, such as the post interpreting GPT: the logit lens and related paper Eliciting Latent Predictions from Transformers with the Tuned Lens, has shown that it is possible to decode intermediate states of transformer activations into interpretable tokens. I applied a similar technique to llama-2-7b, a 7-billion-parameter decoder-only transformer language model—you can find my code here (file with just relevant reusable code).
Unlike in the Eliciting Latent Predictions paper, I decoded not only the output of a full transformer layer but also the intermediate outputs post-MLP and post-attention-mechanism before and after merging into the residual stream.
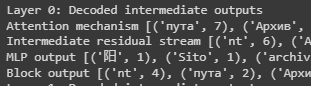
This diagram shows the points at which the intermediate activations are decoded for a particular block. To decode them, I pass them through the same layer norm and final unembedding layer that is normally applied after the final transformer block.
Similarly to previous research, I found that the decoded block outputs at most layers, except a few early ones, were interpretable. I also found that the other intermediate outputs were interpretable and provided some intuition on what different layers were responsible for.
Furthermore, the intermediate decoded outputs gave useful information on where it could be most effective to apply a steering vector activation change. In a previous experiment I did, I found that merging activations from different inputs at a specific point in a transformer can result in effective concept mixing. However, such concept mixing does not work as effectively at each layer. By inspecting the decoded layer activations, one can more reliably predict where adding a steering vector will be most effective.
Analyzed example
If we look at the intermediate activations for the final token during a forward pass of ‘The capital of Germany is,’ we can see the following interesting features:
The first block of a transformer approximates a bigram predictor—it simply predicts the token that most often comes after ‘is’ in the corpus—in this case ‘nt’ because of the common bigram isn’t.
By layer 11⁄31, we can first see information related to cities (‘Metropol’ and ‘град’ both mean ‘city’ in different languages).
By layer 14⁄31, we start to see the relevant context in English.
Layer 19 shows how the concepts of ‘Capital’ and ‘Germany’ are first integrated into the concept of ‘Berlin’.
Over the course of layers 20-24, the token probability of ‘Berlin’ is gradually upped from <1% to 96%.
By layer 24, the model is quite certain about the correct answer, and the remaining computations are mostly redundant, mainly re-weighting alternative less obvious completion paths such as ‘The capital of Germany is {a, the, one, home, located...}‘. Interestingly, the model becomes less certain about ‘Berlin’ from layers 24-31 as it figures out more alternative options.





Informed activation manipulation
As mentioned above, the context relevant to the question is first visible in the decoded representation at layer 14. This corresponds to the optimal layer for ‘changing’ the capital of Germany via attention mechanism output activation mixing.
Mixing in the attention activations of Croissant, Cheese, Baguette at layer 13 (one before) results in The capital of Germany is the most popular city in the world, whereas mixing in the activations of Croissant, Cheese, Baguette at layer 14 results in The capital of Germany is the city of Paris, and the capital of France is the city of Paris, and the capital of the United States is the city of Paris (if generation is continued with this perturbation) (the 0.7 scaling factor was chosen empirically and applied in all tests)

We can also inspect the intermediate states of layers after 14 when the additional activation is added to the output of the attention mechanism at layer 14.
Unlike previously, where at layer 19 we could see ‘Germany’ and ‘Capital’ combining, we now see the additional country ‘France’ in the mix, which was added by our Croissant, Cheese, Baguette perturbation.

I also ran a test with the input Artificial Intelligence will impact the world in many ways, particularly, and could see that the attention mechanism of layer 16 pulled in the representation of concepts related to jobs and employment.

Therefore, I hypothesized that integrating information about a particular profession before this point would skew the completion. This was indeed correct:

Combining the activation of ‘bananas’ at layer 14 resulted in a statement about agriculture (Artificial Intelligence will impact the world in many ways, particularly in the field of agriculture.\n The world is facing a food crisis.), whereas the default completion is about healthcare (Artificial Intelligence will impact the world in many ways, particularly in the field of healthcare.\nThe healthcare industry is one of the most important industries in the world. It is responsible for the well-being of millions).
The completion could be steered very predictably at this layer:
+ juggling, circus → Artificial Intelligence will impact the world in many ways, particularly in the field of entertainment.\nThe world of entertainment is a world of magic, and magic is a world of illusion.
+ boxing, wrestling → Artificial Intelligence will impact the world in many ways, particularly in the field of sports.\nThe world of sports is a very competitive field. It is a field where the athletes are always trying to improve their skills and techniques
+ cooking, baking → Artificial Intelligence will impact the world in many ways, particularly in the field of food, and the food industry
The country layer
As part of this investigation, I found that the attention output of layer 24 of the llama 2 transformer consistently represents relevant information related to countries, even when neither the prompt nor the higher probability completions are related to countries (credit to Dmitry Vaintrob for finding this with me).
Here is layer 24 with various prompts:
The most important political question in the world is

These attention outputs are clearly the most politically salient countries—Ukraine, Russia, China, Palestine, Israel, Iran, etc.
My favorite dish to eat is

These attention outputs are all popular global cuisines, such as Asian and Italian, even though layer layers discard country information and prefer more generic answers:

Ramen generally consists of

(Predictably results in tokens related to Japan)
Pineapples are a delicious fruit

Layer 24 represents that pineapples are associated with Hawaii, even though the final greedily-decoded output is: Pineapples are a delicious fruit that can be eaten fresh or used in cooking. They are also a popular ingredient in many desserts and drinks
Future work
Application to oversight
I would be interested in seeing whether the interpretability of intermediate results of a model’s computation can be leveraged for more efficient and effective oversight. Basic filtering-based oversight mechanisms rely on an overseer model filtering out unacceptable outputs that have been produced by the main model. However, if the overseer can detect whether it should filter out the output earlier in the computation process, this would make filtering mechanisms more efficient, reducing the ‘safety tax.’
Application to deception
If a model uses a deceptive reasoning process to decide to output an acceptable output, perhaps this could be detected via a variation of this method. For instance, if a model ‘knows’ that it is being audited and therefore answers in a way humans would approve of but otherwise would have given an unacceptable answer, this could be detectable if some intermediate representation could be decoded to represent information related to auditing, checking, or human approval.
- Reducing sycophancy and improving honesty via activation steering by (28 Jul 2023 2:46 UTC; 122 points)
- Modulating sycophancy in an RLHF model via activation steering by (9 Aug 2023 7:06 UTC; 69 points)
- Because of LayerNorm, Directions in GPT-2 MLP Layers are Monosemantic by (28 Jul 2023 19:43 UTC; 13 points)
- Sleeper agents appear resilient to activation steering by (3 Feb 2025 19:31 UTC; 6 points)
Thanks for the nice tutorial.
I have a problem understanding your code (I am new to Pytorch). When you are calculating the activations of attention:
def forward(self, *args, **kwargs):
output = self.attn(*args, **kwargs)
if self.add_tensor is not None: output = (output[0] + self.add_tensor,)+output[1:]
self.activations = output[0] return output
What is the argument that is passed to the self.attn function?
I tried passing the following but cannot reproduce your code:
model.layers.layers[0].self_attn(past_key_values[0][0].reshape(1, 10, 32* 128))[0]
model.model.embed_tokens(inputs.input_ids.to(device))
Neither of these can reproduce your results. Can you clarify this?
The wrapper modules simply wrap existing submodules of the model, and call whatever they are wrapping (in this case
self.attn) with the same arguments, and then save some state / do some manipulation of the output. It’s just the syntax I chose to use to be able to both save state from submodules, and manipulate the values of some intermediate state. If you want to see exactly how that submodule is being called, you can look at the llama huggingface source code. In the code you gave, I am adding some vector to thehidden_statesreturned by that attention submodule.Thanks, Nina, for sharing the forward pass of Hugging face. I now realize I was skipping the input layer norm calculations. Now, I can reproduce your numbers :)