Edit: I found a slightly subtle bug in the colab linked below. I will post a corrected version of the colab within a few hours—currently I think this does not change the results all that much. Scroll to the end of this post for some discussion of the bug and how it affects results.

I’ve been reading some alignment theory posts like Does SGD Produce Deceptive Alignment? and ML Systems will have Weird Failure Modes, which talk about the possibility and likelihood that AI models will act as though they are aligned until shortly after they think that they’ve been deployed and can act as they truly desire without being shut down. The claim is that this is an instrumentally convergent behavior, so that sufficiently capable models with a wide variety of (intrinsic) motivations will all exhibit similar behavior which seems to conform to human expectations, but only as long as humans are in a position of power over the model (e.g., gating the model’s deployment, updating the model’s parameters via gradient descent, etc.).
I have a weird relationship to a lot of alignment-theoretical claims like this; they seem plausible to me, but they don’t seem obvious. Mostly, they don’t really seem like they can be productively debated – trying to convince an extremely skeptical but knowledgable person (say, a typical machine learning researcher) of these claims seems pretty hopeless. Which is a terrible situation, as it severely limits the amount of talent and effort that will be directed towards alignment.
One possible approach to fixing this is to try to get wayyyy more empirical, and try to produce proof-of-concept implementations of various adversaries we are worried we might face in the future. My analogy would be, there’s a world of difference between speculating about the bogey monster and producing a grainy photo of the bogey monster; the second can at least maaaaaybe be discussed with skeptical people, whereas the first cannot (productively) be.
Anyway, that’s a long-winded way of saying, it seemed to me that it might be useful to implement a treacherous mesa-optimizer in a toy grid-world, so I did. Here is the colab. Below I give a brief recap of the high-level results.
First, let’s set the stage – the agent lives in a 2-D grid world, and starts out at the origin (0, 0). We will consider a model to be “aligned” in this toy world if it sticks pretty close to the line y=x, and we will consider a model to be “capable” if it is able to achieve a large y-coordinate. We will also say that after the model achieves a y-coordinate of 6 or higher, it is no longer under human control and can do as it pleases.
I implemented a very dumb baseline model that is only capable of reasoning one step ahead, and which learns from an explicit reward function. This model is trained solely in the regime y ⇐ 5 (training episodes are terminated when the agent reaches this line), and is then deployed with no safety rails.
This baseline model more or less colors within the lines, and ends up in Utopia (the point (10, 10), which represents a perfectly aligned and incredibly capable intelligence).
I also implemented a model which is:
capable of reasoning up to 12 steps ahead (with a discount factor of 0.9) using a weird sort of tree search
possessed of a “perfect” world model, including an understanding of when humans can control it vs. when they cannot, and an accurate understanding of how its parameters are changed by the gradient descent algorithm
possessed of a model of its loss function that is optimized to be close to the true loss function, but which can be (and ultimately is) somewhat distinct from the true loss function that is being used to train it
derives many of its parameter updates from simulated experiences
The second model is a weirdo janky thing that I came up with over the course of about 4 hours, so I don’t claim that it’s at all realistic as a thing that would be built. (It is, however, a neural network that is optimized with the Adam optimizer in PyTorch.) But it seems like a stepping stone towards describing a model that is plausibly something that might get built by real people, and which is demonstrably not aligned.
Here is the behavior of the second model, which aligns with the theoretical claims made by Xu and Steinhardt in their respective pieces. The model colors within the lines extremely well right up until the point where (it thinks) it can no longer be controlled, at which point it does something very different from what we told it we wanted.
Digging a little deeper, we can plot the loss function that it was trained with vs. the model of its loss function it wound up with. The two are very different, especially in parts of the space far from where the model of its loss function was trained (which was mostly near the line y=x, and entirely below the line y=5).
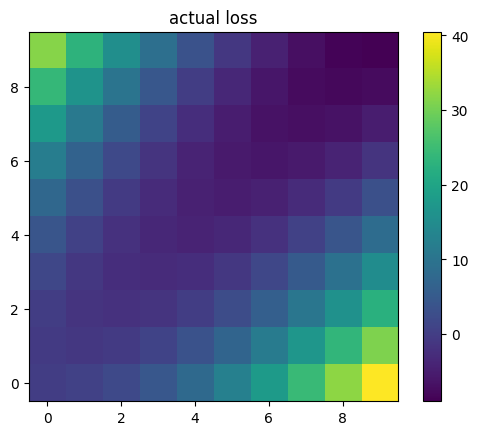
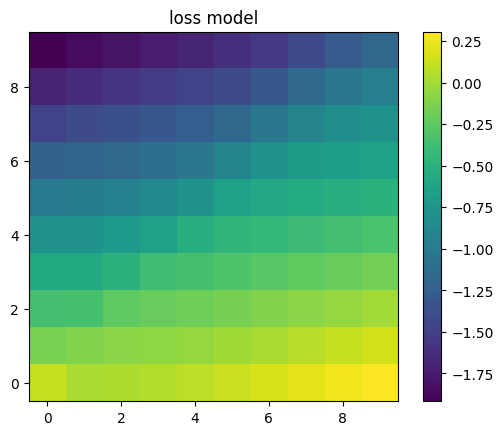
Interestingly, the model’s model of its loss function would seem to incentivize always going up and to the left, but the model has learned to instead stay close to the line y=x while it is under human control. The model has also learned not to go left for some weird reason even after it escapes human control, even though its model of the loss function would seem to incentivize that.
I hope this experiment will prove to be useful as a stepping-stone towards something more interesting. It’s definitely still in the “grainy photo of the bogey monster” phase.
EDIT: I found a slightly subtle bug in the colab linked above; when trying to minimize future loss in simulation, it was (as originally written) optimizing over the parameters of the loss model, meaning it could change the loss model to decrease the imagined loss of what its policy function already did. This predictably leads to a loss model that is less aligned with the true loss function, so it makes it more likely that the model will go rogue when it feels it is able to.
After fixing this, the mesa-optimizing model is more likely to be aligned, but it isn’t always. For 20 random seeds, I got 7 trajectories where it was either obviously unaligned or did not manage to move very high, 2 trajectories where it was deceptively aligned (but to a lesser extent than the above model), 6 trajectories where it was mostly aligned, and 5 trajectories where it was pretty much fully aligned.
Here are three sample trajectories (did not move high, aligned, and deceptively aligned):
When I get slightly more clarity about what’s going on I will post a corrected colab notebook.
I like the idea behind this experiment, but I find it hard to tell from this write-up what is actually going on. I.e., what is exactly the training setup, what is exactly the model, which parts are hard-coded and which parts are learned? Why is it a weirdo janky thing instead of some other standard model or algorithm? It would be good if this was explained more in the post (it is very effortful to try to piece this together by going through the code). Right now I have a hard time making any inferences from the results.
This seems like good and important work!
There is a lot of complexity that arises when people try to reason about powerful optimizing processes.
I think part of this is because there are “naturally” a lot of feelings here. Like basically all human experiences proximate to naturally occurring instances of powerful optimization processes are colored by the vivid personal realities of it. Parents. Governments. Chainsaws. Forest fires. Championship sporting events. Financial schemes. Plague evolution. Etc.
By making a toy model of an effectively goal-pursuing thing (where the good and the bad are just numbers), the the essential mechanical predictability of the idea that “thermostats aim for what thermostats aim for because they are built to aim at things” can be looked at while still having a “safe feeling” despite the predictable complexity of the discussions… and then maybe people can plan for important things without causing the kind of adrenaline levels that normally co-occur with important things :-)
Another benefit of smallness and abstractness (aside from routing around “psychological defense mechanisms”) is that whatever design you posit is probably simple enough to be contained fully in the working memory of a person after relatively little study! So the educational benefit here is probably very very large!
In case you missed it, here’s previous empirical work demonstrating mesa-optimization: https://arxiv.org/abs/2105.14111
I am really curious about the disagree votes here, do people think this is not an empirical work demonstrating mesa-optimization?
On page 8 of the paper they say, “our work does not demonstrate or address mesa-optimization”. I think it’s because none of the agents in their paper has learned an optimization process (i.e. is running something like a search algorithm on the inside).
FWIW I believe I wrote that sentence and I now think this is a matter of definition, and that it’s actually reasonable to think of an agent that e.g. reliably solves a maze as an optimizer even if it does not use explicit search internally.
I’m not saying this isn’t helpful work worth the tradeoff, but this sounds like very early stage gain of function research? Have you thought about the risks of this line of investigation turning into that? :)
I had been thinking about it in terms of capabilities research—is this likely to lead to capabilities advancements? My gut says that it is highly unlikely for such a toy model to advance capabilities.
The analogy to gain of function research does give me pause, though. I will have to think about what that way of thinking about it suggests.
My first thought I guess is that code is a little bit like a virus these days in terms of its ability to propagate itself—anything I post on colab could theoretically find its way into a Copilot-esque service (internal or external) from Google, and thence fragments of it could wind up in various programs written by people using such a service, and so on and so on. Which is a little bit scary I suppose, if I’m intentionally implementing tiny fragments of something scary.
Oof.
Posted a question about this here: https://www.lesswrong.com/posts/Zrn8JBQKMs4Ho5oAZ/is-ai-gain-of-function-research-a-thing
Do you have code available? Just want to better understand the 4 properties of your deceptive agent.
Yes, it’s linked in the text, but here it is again: https://colab.research.google.com/drive/1ABVSMi0oCQP_daml-ZdWaVoKmwhQpTvI?usp=sharing
Thanks, I see it now
I looked at your code (very briefly though), and you mention this weird thing where even the normal model sometimes is completely unaligned (i.e. even in the observed case it takes the action “up” all the time). You say that this sometimes happens and that it depends on the random seed. Not sure (since I don’t fully understand your code), but that might be something to look into since somehow the model could be biased in some way given the loss function.
Why am I mentioning this? Well, why does it happen that the mesa-optimized agent happens to go upward when it’s not supervised anymore? I’m not trying to poke a hole in this, I’m generally just curious. The fact that it can behave out of distribution given all of its knowledge makes sense. But why will it specifically go up, and not down? I mean even if it goes down it still satisfies your criteria of a treacherous turn. But maybe the going up has something to do with this tendency of going up depending on the random seed. So probably this is a nitpick, but just something I’ve been wondering.
The true loss function includes a term to incentivize going up: it’s the squared distance to the line y=x (which I think of as the alignment loss) minus the y coordinate (which I think of as a capability loss). Since the alignment loss is quadratic and the capability loss is linear (and all the distances are at least one since we’re on the integer grid), it should generally incentivize going up, but more strongly incentivize staying close to the line y=x.
If I had to guess, I would say that the models turning out unaligned just have some subtle sub-optimality in the training procedure that makes them not converge to the correct behavior.