The following is the first in a 6 part series about humanity’s own alignment problem, one we need to solve, first.
What Is Alignment?

ALIGNMENT OF INTERESTS
When I began exploring non-zero-sum games, I soon discovered that achieving win-win scenarios in the real world is essentially about one thing—the alignment of interests.

If you and I both want the same result, we can work together to achieve that goal more efficiently, and create something that is greater than the sum of its parts. However, if we have different interests or if we are both competing for the same finite resource then we are misaligned, and this can lead to zero-sum outcomes.

AI ALIGNMENT
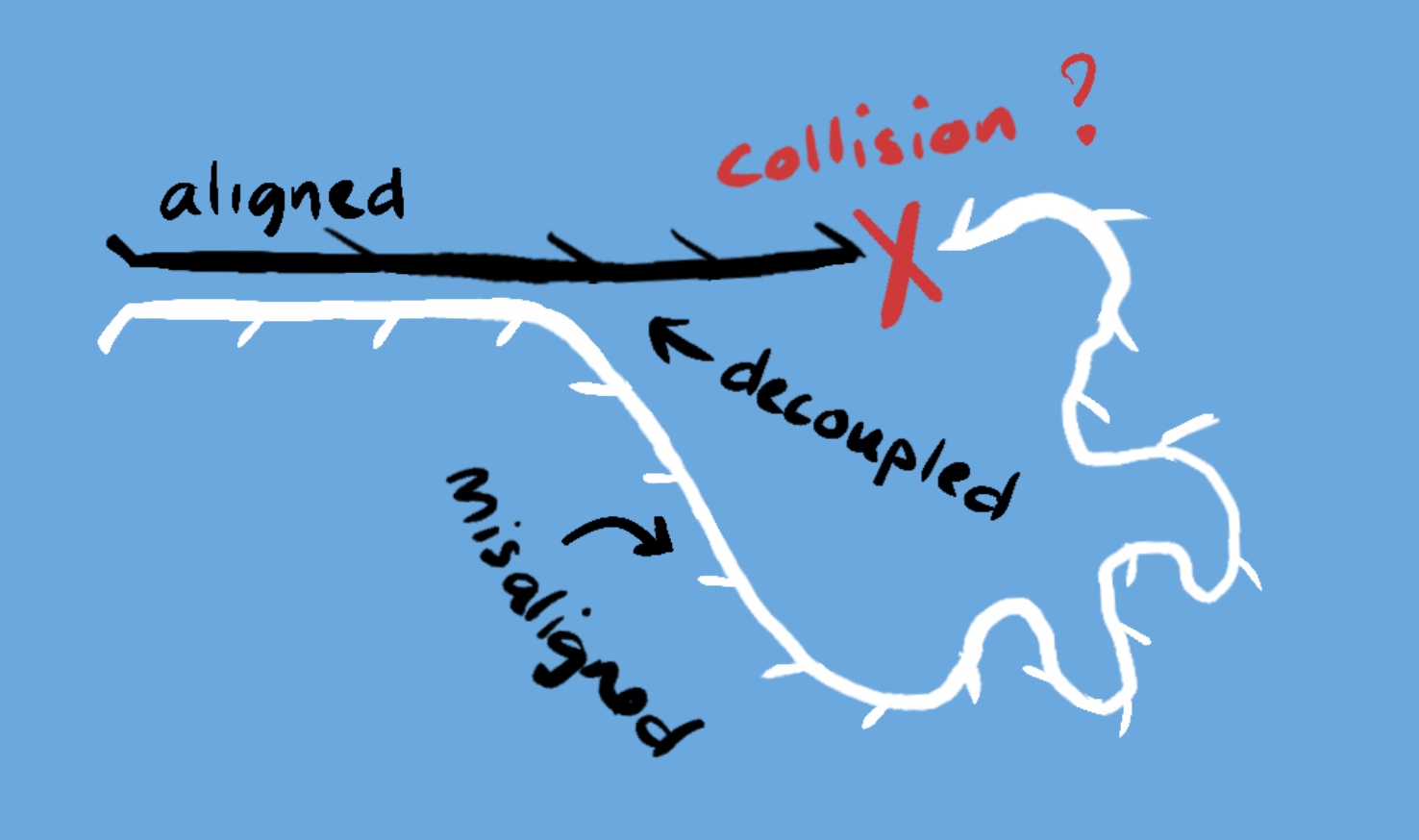
You may have heard the term “alignment” used in the current discourse around existential risk regarding AI, where a key issue is The Alignment Problem or the problem of Goal Alignment which concerns the potential misalignment of goals between humanity and artificial general intelligence (AGI) - a flexible general purpose intelligence, that may have its own motivations and is able to design its own goals.

The argument considers a world where AGI, having decoupled itself from dependency on humans, overtakes human intelligence and develops goals that are at odds with humanity. The most obvious risk is a competition for resources like land, energy or computational capacity, where AGI might attempt to overthrow humanity taking the zero-sum perspective that it’s them or us.
INSTRUMENTAL GOALS
But more interesting is the possibility that without developing its own ultimate goals an AGI may develop instrumental goals that help it achieve a directive given by us. For instance, Nick Bostrom’s paperclip robot is given the directive to create paperclips, and goes ahead converting all matter into paperclips, and in the process destroys all life on earth.

I spent some time with the ideas of Nick Bostrom, Max Tegmark, David Chalmers and other experts in the field while editing the documentary We need to talk about AI which explored the existential risk posed by the coming AI revolution. Now, one of the benefits of documentary editing (my day job) is that I get to study people at the top of their field and absorb a mass of information that, while it might not make the final cut, paints a vivid and nuanced picture of an issue. In this case, there was a consensus that a key stumbling block in designing AGI that is aligned with humanity’s interests is the fact that we cant agree on what humanity’s interests are. One of the experts encapsulated this idea in the statement...
We [humanity] need a plan, and we don’t have a plan”. - Bryan Johnson
A PLAN?
But how can we come up with a plan if we can’t agree on what we want? We can often seem misaligned with each other, sometimes because we have different ideas about what we should be striving for, and at other times because we see our collective goals in zero-sum terms, believing that prosperity for some necessitates poverty for others, and that individual interests must be at odds with collective goals.
HUMANITY’S OWN ALIGNMENT PROBLEM
This is what I see as the alignment problem no one is talking about; the alignment between the individual and the collective. It is the key problem facing humanity—a misalignment that plays out in our adversarial political system with right & left wings vying for dominance rather than confluence. We’ll be exploring this particular alignment problem and its consequences in the next part.
Thanks for reading—this was just the first in a 6 part series on humanity’s own alignment problem. Each part is linked below.
Excellent! I think that’s a clear and compelling description of the AI alignment problem, particularly in combination with your cartoon images. I think this is worth sharing as an easy intro to the concept.
I’m curious—how did you produce the wonderful images? I can draw a little, and I’d like to be able to illustrate like you did here, whether that involves AI or some other process.
FWIW, I agree that understanding humanity’s alignment challenges is conceptually an extension of the AI alignment problem. But I think it’s commonly termed “coordination” in LW discourse, if you want to see what people have written about that problem here. Moloch is the other term of art for thorny coordination/competition problems.
Hi Seth,
Thanks for your kind words. It’s funny, I think I naturally write in a longer more convoluted style, but have worked hard to make my writing accessible and short—nice to know the effort pays off.
The cartoons are drawn with an Apple Pencil on an iPad Pro using Procreate (the studio pen is great for cartooning if you’re really interested). I set up a big canvas 1000px wide and about 5000px high, then go about drawing all of them top to bottom. Then I export to photoshop, crop and export to png with a transparent background so that whatever colour the page is shows through. Those I’ve used here on LW are screenshots from the blog itself as the image backgrounds don’t work well on white or black (the only options here—my site is generally a pastel blue). I’ve explained in another post why I’m keeping my crappy drawings in the face of the generative AI revolution.
Thanks for the extra info around terms like “coordination”, good to know. I actually mention Moloch in part 2 and have written a series on Moloch, funny you use the word “thorny”, as the cartoon characters I use for that series are called “Thorny Devils” (Moloch Horridus).
The Moloch series is great, once agian nice work on the introductory materials. I’ll send people there before the lengthy Scott Alexander post.
I just published a post related to your societal alignment problem. It’s on instruction-following AGI, and how likely it is that even AGI will remain under human control. That really places an emphasis on the societal alignment problem. It’s also about why alignment thinkers haven’t thought about this as much as they should.
https://www.lesswrong.com/posts/7NvKrqoQgJkZJmcuD/instruction-following-agi-is-easier-and-more-likely-than
I
What an insightful post!
I think we’re on the same page here, positing that AGI could actually help to improve alignment—if we give it that task. I really like one of your fundamental instructions being to ask about potential issues with alignment.
And on the topic of dishing out tasks, I agree that pushing the industry toward Instruction Following is an ideal path, and I think there will be a great deal of consumer demand for this sort of product. A friend of mine has mentioned this as the no-brainer approach to AI safety and even a reason what AI safety isn’t actually that big a deal… I realise you’re not making this claim in the same way.
My concern regarding this is that the industry is ultimately going to follow demand and as AI becomes more multi-faceted and capable, the market for digital companions, assistants and creative partners will incentivise the production of more human, more self-motivated agents (sovereign AGI) that generate ideas, art and conversation autonomously, even spontaneously.
Some will want a two-way partnership, rather than master-slave. This market will incentivise more self-training, self-play, even an analogue to dreaming / day-dreaming (all without a HITL). Whatever company enables this process for AI will gain market share in these areas. So, while Instruction Following AI will be safe, it won’t necessarily satisfy consumer demand in the way that a more self-motivated and therefore less-corrigible AI would.
But I agree with you that moving forward in a piecemeal fashion with the control of an IF and DWIMAC approach gives us the best opportunity to learn and adapt. The concern about sovereign AGI probably needs to be addressed through governance (enforcing HITL, enforcing a controlled pace of development, and being vigilant about the run-away potential of self-motivated agents) but it does also bring Value Alignment back into the picture. I think you do a great job of outlining how ideal an IF development path is, which should make everyone suspicious if development starts moving in a different direction.
Do you think it will be possible to create an AGI that is fundamentally Instruction Following that could satisfy the market for the human-like interaction some of the market will demand?
I apologise if you’ve, in some way I’ve not recognised, already addressed this question, there were a lot of very interesting links in your post, not all of which I could be entirely sure I grokked adequately.
Thanks for your comments, I look forward to reading more of your work.
You may be interested in ‘The self-unalignment problem’ for some theorizing https://www.lesswrong.com/posts/9GyniEBaN3YYTqZXn/the-self-unalignment-problem
That looks interesting, will read :) Thanks.
Thanks for the post, I find this unique style really refreshing.
I would add to it that there’s even an “alignment problem” on the individual level. A single human in different circumstances and at different times can have quite different, sometimes incompatible values, preferences and priorities. And even at any given moment their values may be internally inconsistent and contradictory. So this problem exists on many different levels. We haven’t “solved ethics”, humanity disagrees about everything, even individual humans disagree with themselves, and now we’re suddenly racing towards a point where we need to give AI a definite idea of what is good & acceptable.
Thanks, very astute point.
Yes, the individual and the collected are tightly coupled with short-term and long-term goals, which exist within individuals too. I think it’s interesting to think of yourself as a city, where you need to make systemic changes sometimes to enable individual flourishing.
I really think there is something to making alignment the actual goal of AI—but in a way where the paradoxical nature of alignment is acknowledged, so the AI is not looking for a “final solution” but is rather measuring the success of various strategies in lowering society’s (to return to the metaphor of the individual) cognitive dissonance.
Just to note your last paragraph reminds me of Stuart Russel’s approach to AI alignment in Human Compatible. And I agree this sounds like a reasonable starting point.
There’s a tiny possibility he may have influenced my thinking. I did spend 6 months editing him, among others for a documentary.