This is the full text of a post from “The Obsolete Newsletter,” a Substack that I write about the intersection of capitalism, geopolitics, and artificial intelligence. I’m a freelance journalist and the author of a forthcoming book called Obsolete: Power, Profit, and the Race to build Machine Superintelligence. Consider subscribing to stay up to date with my work.
Earlier this month, I wrote, “There’s a vibe that AI progress has stalled out in the last ~year, but I think it’s more accurate to say that progress has become increasingly illegible.”
I argued that while AI performance on everyday tasks only got marginally better, systems made massive gains on difficult, technical benchmarks of math, science, and programming. If you weren’t working in these fields, this progress was mostly invisible, but might end up accelerating R&D in hard sciences and machine learning, which could have massive ripple effects on the rest of the world.
Today, OpenAI announced a new model called o3 that turbocharges this trend, obliterating benchmarks that the average person would have no idea how to parse (myself included).
A bit over a month ago, Epoch AI introduced FrontierMath, “a benchmark of hundreds of original, expert-crafted mathematics problems designed to evaluate advanced reasoning capabilities in AI systems.”
These problems are really fucking hard, and the state-of-the-art (SOTA) performance of an AI model was ~2%. They were also novel and unpublished, to eliminate the risk of data contamination.
OpenAI says that o3 got 25% of these problems correct.
Terence Tao, perhaps the greatest living mathematician, said that the hardest of these problems are “extremely challenging… I think they will resist AIs for several years at least.”
Jaime Sevilla, director of Epoch AI, wrote that the results were “far better than our team expected so soon after release. AI has hit a wall, and smashed it through.”
Buck Shlegeris, CEO of the AI safety nonprofit Redwood Research, wrote to me that, “the FrontierMath results were very surprising to me. I expected it to take more than a year to get this performance.”
FrontierMath was created in part because models were quickly scoring so well they “saturate” other benchmarks to the point that they stop being useful differentiators.
Other benchmarks
o3 significantly improved upon the SOTA in a number of other challenging technical benchmarks of mathematics, hard science questions, and programming.
In September, o1 first exceeded human domain experts (~70%) in the GPQA Diamond benchmark of PhD-level hard science questions (~78%). o3 now definitively beats them both, getting 88% right. In other words, a single AI system outperforms the average of human experts in these tests of each their respective domains of expertise.
o3 also scores high enough on Codeforces programming competition problems to place it as 175th top-scoring human in the world (out of the ~168k users in the last six months).
SWE-Bench is a repository of real-life, unresolved issues in open source codebases. The top score a year ago was 4.4%. The top score at the start of December was 55%. OpenAI says o3 got 72% correct.
ARC-AGI
o3 also approaches human performance on the ARC-AGI benchmark, which was designed to be hard for AI systems, but relatively doable for humans (i.e. you don’t need a PhD to get decent scores). However, it’s expensive to get those scores.
OpenAI research Nat McAleese published a thread on the results, acknowledging “o3 is also the most expensive model ever at test-time,” i.e. when the model is being used on tasks. Running o3 on ARC-AGI tasks cost between $17 and thousands of dollars per problem — while humans can solve them for $5-10 each.
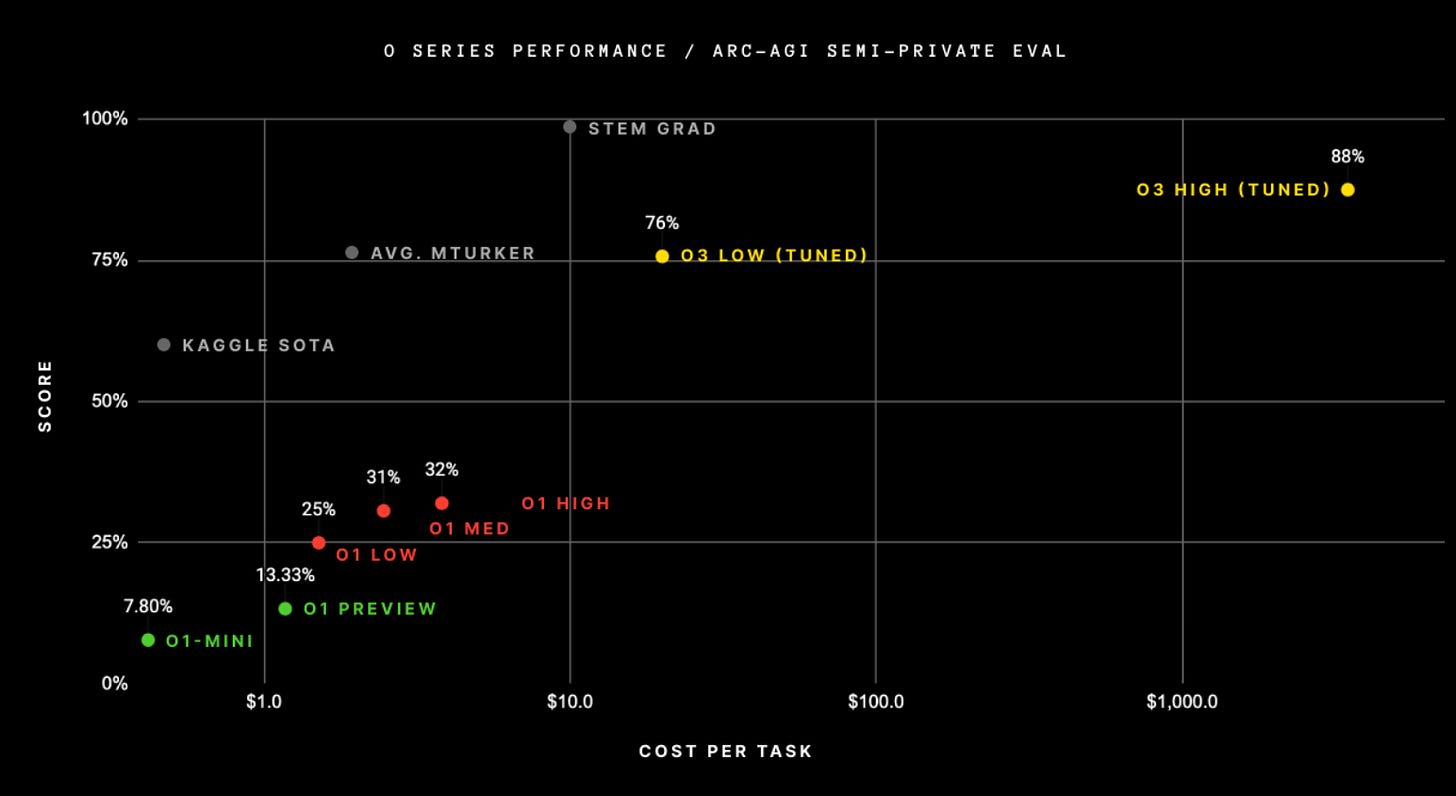
This aligns with what I wrote last month about how the first AI systems to achieve superhuman performance on certain tasks might actually cost more than humans working on those same tasks. However, that probably won’t last long, if historic cost trends hold.
McAleese agrees (though note that it’s bad news for OpenAI if this isn’t the case):
My personal expectation is that token prices will fall and that the most important news here is that we now have methods to turn test-time compute into improved performance up to a very large scale.
I’m particularly interested in seeing how o3 performs on RE-Bench, a set of machine learning problems that may offer the best insight into how well AI agents stack up against expert humans in doing the work that could theoretically lead to an explosion in AI capabilities. I would guess that it will be significantly better than the current SOTA, but also significantly more expensive (though still cheaper than the human experts).
Mike Knoop, co-founder of ARC-AGI prize wrote on X that “o3 is really special and everyone will need to update their intuition about what AI can/cannot do.”
So is deep learning actually hitting a wall?
A bit over a month ago, I asked “Is Deep Learning Actually Hitting a Wall?” following a wave of reports that scaling up models like GPT-4 was no longer resulting in proportional performance gains. There was hope for the industry in the form of OpenAI’s o1 approach, which uses reinforcement learning to “think” longer on harder problems, resulting in better performance on some reasoning and technical benchmarks. However, it wasn’t clear how the economics of that approach would pencil out or where the ceiling was. I concluded:
all things considered, I would not bet against AI capabilities continuing to improve, albeit at a slower pace than the blistering one that has marked the dozen years since AlexNet inaugurated the deep learning revolution.
It’s hard to look at the results of o1 and then the potentially even more impressive results of o3 published ~3 months later and say that AI progress is slowing down. We may even be entering a new world where progress on certain classes of problems happens faster than ever before, all while other domains stagnate.
Shlegeris alluded to this dynamic in his message to me:
It’s interesting that the model is so exceptional at FrontierMath while still only getting 72% on SWEBench-Verified. There are way more humans who are able to beat its SWEBench performance than who are able to get 25% at FrontierMath.
Once more people get access to o3, there will inevitably be widely touted examples of it failing on common-sense tasks, and it may be worse than other models at many tasks (maybe even most of them). These examples will be used to dismiss the genuine capability gains demonstrated here. Meanwhile, AI researchers will use o3 and models like it to continue to accelerate their work, bringing us closer to a future where humanity is increasingly rendered obsolete.
If you enjoyed this post, please subscribe to TheObsolete Newsletter.
I haven’t had warm receptions when critiquing points, which has frustratingly left me with bad detection for when I’m being nasty, so if I sound thorny it’s not my intent.
Somewhere I think you might have misstepped is the frontier math questions: the quotes you’ve heard are almost certainly about tier 3 questions, the hardest ones meant for math researchers in training. The mid tier is for grad student level problems and tier 1 is bright high schooler to undergrad level problems
Tier 1: 25% of the test
Tier 2: 50% of the test
Tier 3: 25%
O3 got 25%, probably answering none of the hard questions and suspiciously matching almost exactly the proportion of easy questions. From some, there seems to be disagreement about whether tier 2 questions are consistently harder than tier 1 questions
Regardless, some (especially easier) problems are of the sort that can be verified and have explicitly been said to have instantaneously recognizable solutions. This is not an incredibly flattering picture of o3
THIS IS THE END OF WHERE I THINK YOU WERE MISTAKEN, TEXT PAST THIS IS MORE CONJECTURE AND/OR NOT DIRECTLY REFUTING YOU
the ARC test looks like it was taken by an overfit model. If the test creators are right, then the arc test for an 85 percent off a tuned model and probably spamming conclusions that it could verify, it trained on 75 percent of the questions from what I understand so one of that score seems like memorization and a mildly okay score on the 25 percent that was held as test data.
And this part is damning: the arc-2 test which is the success of to the first one, made by the same people, gets a 95 percent pass rate form humans (so easier than the 85 percent pass rate of the first test) but o3′s score dropped to a 30%, a 55% drop and now 65% below human on a similar test made by the same people.
Let me be clear: if that isn’t VERY inaccurate, then this is irrefutably a cooked test and o3 is overfit to the point of invalidating the results for any kind of generalizability.
There are other problems, like the fact that this pruning search method is really, really bad for some problems and that it seems to ride on validation being somewhat easy in order to work at all but that’s not material to the benchmarks
I can cite sources if these are important points, not obviously incorrect, etc, I might write my first post about it if I’m digging that much!
I like this post, especially as I think that o3 went under the mainstream radar. Just took notice of this announcement today, and I have not seen many reactions yet (but perhaps people are waiting to get their hands on the system first?) Is there a lack of reactions (also given that this post does not have a lot of engagement), or is my Twitter just not very updated?
Mike Knoop also mentioned in his Twitter post that this shows proof of how good deep learning program synthesis is. Does this refer to the way o3 was prompted to solve the ARC questions? Otherwise, what suggests this paradigm?
It was all my twitter feed was talking about, but I think it’s been really under-discussed in mainstream press.
RE Knoop’s comment, here are some relevant grafs from the ARC announcement blog post:
More in the ARC post.
My rough understanding is that it’s like a meta-CoT strategy, evaluating multiple different approaches.