Food, Prison & Exotic Animals: Sparse Autoencoders Detect 6.5x Performing Youtube Thumbnails
TL;DR
A Sparse Autoencoder trained on CLIP activations detects features in youtube thumbnails associated with high view counts across a dataset of 524,288 thumbnails from youtube-8m. Most of these features are interpretable and monosemantic. The most strongly associated feature has a median view count > 6.5x the dataset median. After simulating random features and comparing their median views we conclude that the probability that these observations could have occurred at random is zero or near zero.
These features may correspond to visual elements which attract the attention of youtube users, but they may instead correlate to some other, less exciting structure related with higher views such as date of upload.
Similar analysis is conducted on MrBeast videos.


Motivation
At the time of writing there is difficulty in identifying practical use cases for Sparse Autoencoders.
There are many existing projects (VidIQ, CreatorML) which try to detect high performing youtube videos using deep-learning. One useful element these systems tend to lack is interpretability, i.e. they can predict whether a thumbnail or title will lead to higher views but they cannot pick out specific conceptual elements which will aid or detract from engagement.
Sparse Autoencoders may have an advantage in this very narrow field if they can surface monosemantic features which are associated with higher views. These features could then inform creators on which elements to include in their videos, titles or thumbnails.
Methodology: Selecting Feature Groups
Following Hugo Fry[1] we train a CLIP sparse autoencoder on 1,281,167 imagenet images. We then collect Sparse Autoencoder latents across two datasets of youtube thumbnails:
524,288 videos from the the Youtube-8m training set, extracted up till 2018.
329 recent, longform MrBeast videos (we remove all shorts and all videos before the channel hit 100,000 subscribers)
Importantly this represents a domain shift. We would expect different results from a SAE trained on youtube thumbnails.
We use these latents as follows:
Take all latent features which activate >0.05 on at least 400 thumbnails in the dataset. Activations lower than 0.05 were found through a process of trial and error to generally be polysemantic. We find 952 such features.
Take the median of views across the lowest activating 399 of these 400 thumbnails, the final thumbnail is held out for later analysis. This becomes the median view count for that feature.
Finally take the 100 features with the highest median view counts. These can be thought of as “high view features”. These features might correspond to visual elements which are highly clickable. We also take the 100 features with the lowest view counts as “low view features”.
Results
Interpretability Assessment
For each high/low view feature we collect the 11 highest activating images from a 524,288 image subset of the imagenet training set. We then plot the top 11 thumbnails of each high/low view feature above the 11 imagenet images for that feature.
We then perform a (very rough) subjective evaluation of interpretability for each feature by assessing whether the feature intuitively appears to be monosemantic or not. In the author’s assessment all 88 of the 100 youtube-8m high view feature thumbnail groups are clearly monosemantic. In all 12 cases of polysemanticity the imagenet images were monosemantic, which suggests that the polysemancitiy may be related to domain shift.
Three examples are chosen entirely at random and provided below, the rest, alongside the low view features can be found here.

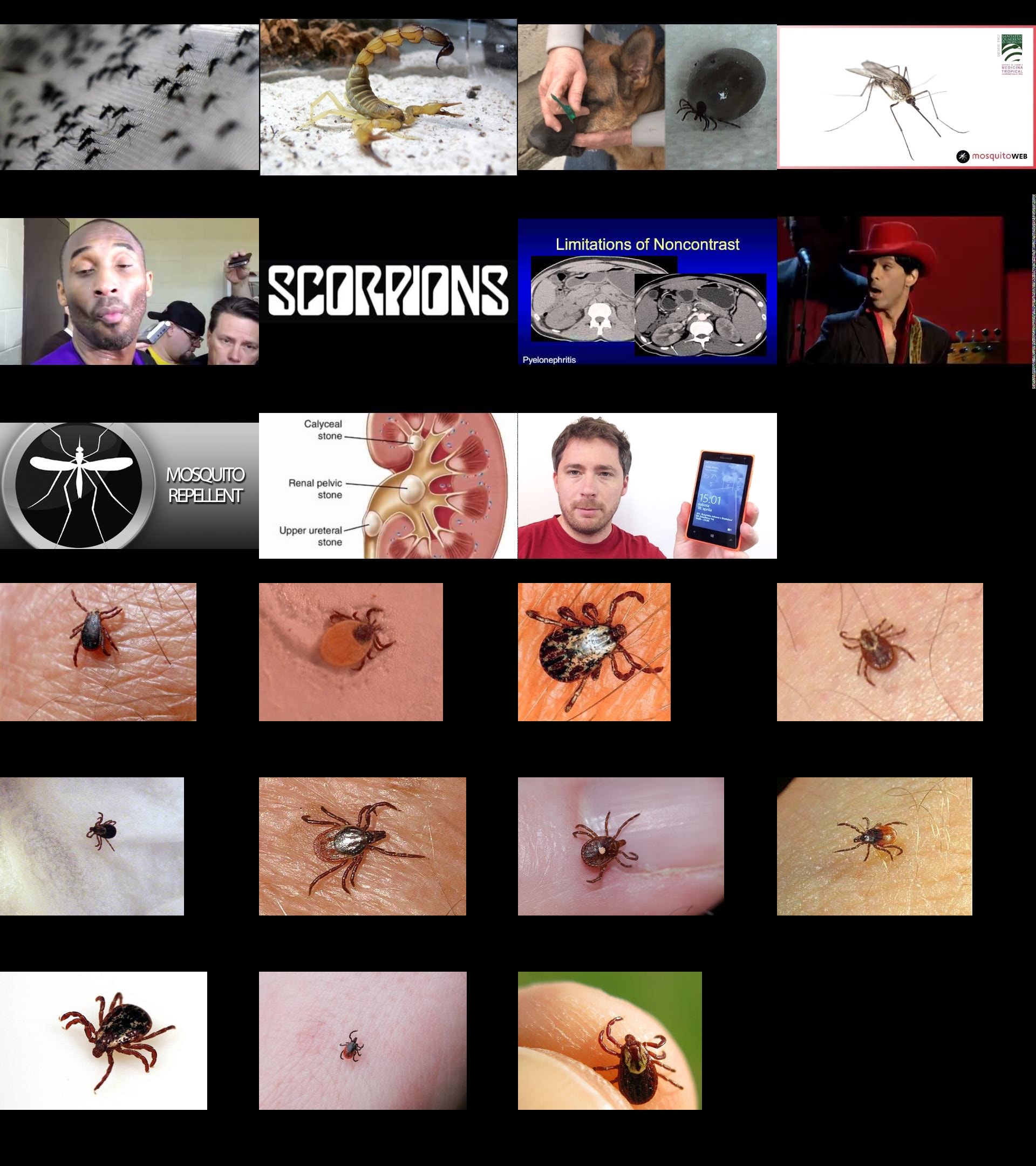

Statistical Strength Assessment
We assess the strength of the relationship between the high/low view features and views. We want to determine if these groups merely have extreme views by chance, or if there is a statistically meaningful association. After all, if we select enough random groups eventually we will find some with high median views.
We sample 399 videos entirely at random (with replacement), and repeat this 952 times to create 952 random feature groups. We plot the median view counts of the random feature groups against the median view counts of the real feature groups.
Visually these distributions look very different and when we perform an Kolmogorov-Smirnov test we receive a KS test statistic of 0.9875 and a P-value of 0. This strongly suggests that the Sparse Autoencoder features are grouping the data in a way that is related to video views.
Next we specifically test the 100 high/low view features by assessing the view counts of the final, held-out video in each group, which was excluded from the feature median calculation. If these features really are indicative of high/low views then we would expect the views of the held-out video to match the views of its group.
For the 100 high view features we take the median views of all held-out videos, giving us HHM, the high, held-out median. We also calculate LHM the low held-out median. If the Sparse Autoencoder features have no relation to video views we would expect HHM and LHM both to approximate the median of 100 videos taken from the dataset at random.
To test this we create distribution of random medians D by simulating 1,000,000 random selections (with replacement) of 100 videos and calculating the medians of their views. We find that if we select once at random from D:
there is a %0.1447chance that we would pick a value ⇐ LHM
there is no chance at all chance that we would pick a value >= HHM
This suggests that it is extremely likely that our high and low view features have some significant relation to video views.
Magnitude Assessment
Statistical tests aside these features are not useful unless they have a large impact on the number of views a thumbnail has received.
Below we plot the median of each feature group compared to the median of the dataset.
The impact of a video being in one of the top-100 features is an increase of anywhere between a 2x and 6.5x view increase. The bottom-100 features are less impactful, having an impact of between 1.3 and and 3x less views. It is unclear whether view increases of this magnitude are important to youtube creators, if someone has more information on this please post some resources if you have time.
The topk and bottomk group medians are made available in this .csv for anyone wanting to do more precise analysis.
Feature Analysis
In case it is of interest to content creators we provide the top activating thumbnail for each high view feature and its median views alongside the top activating thumbnail for each low view feature. The full size images can be found here along with the top 11 thumbnails for each feature. It is worth stressing that this dataset was compiled in 2018 so these images will not match current youtube thumbnail ecosystem.
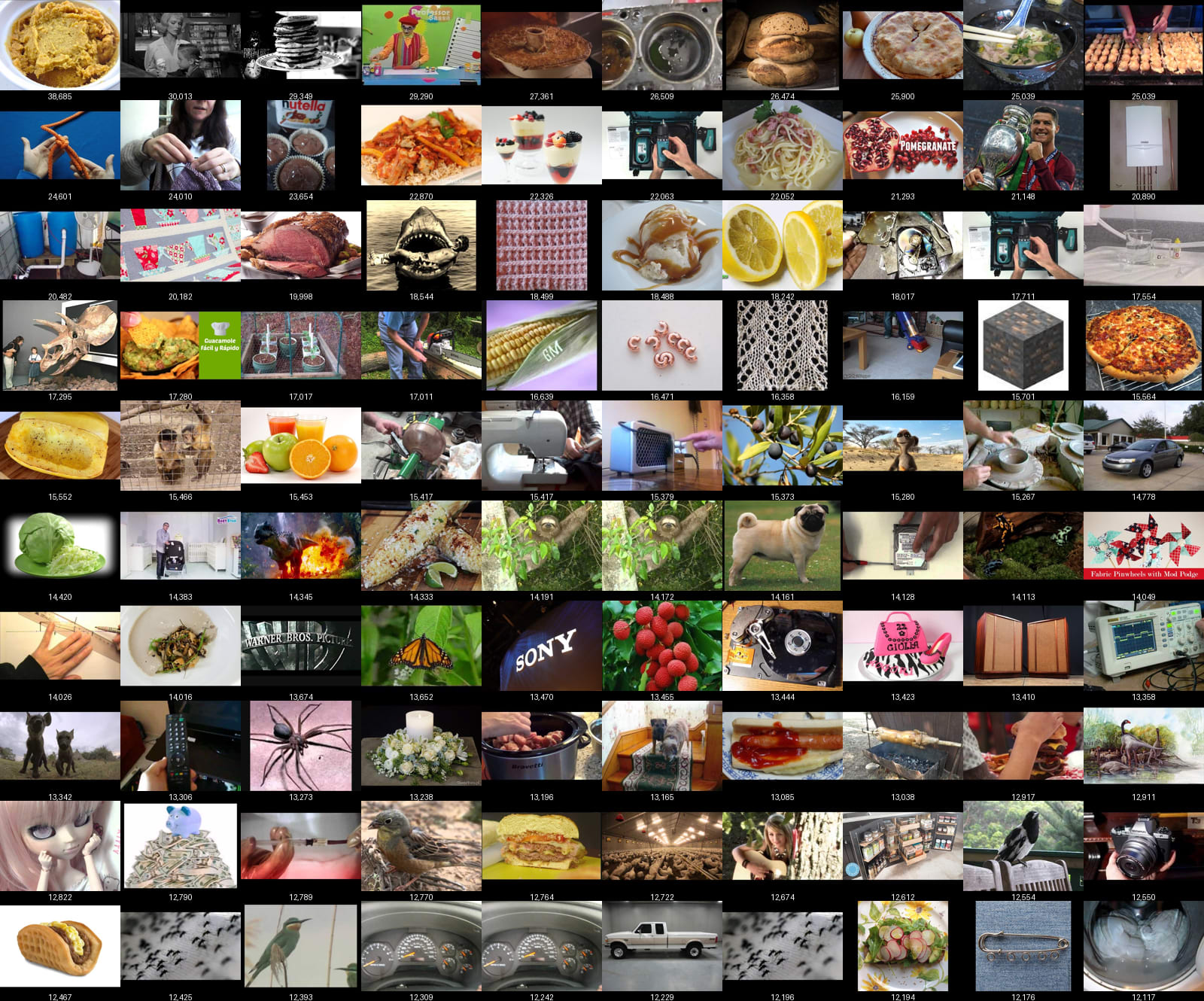

The most obvious trend here is that many of the high view features (32 in fact, and 7 of the top 10) involve food. By contrast only one thumbnail among the low view features depicts food. It is dangerous to speculate about how these features relate to view counts, but the intuitive explanation is that people quite like food, and might therefore be drawn to images containing food.
Sporting events seem to make up a large proportion of the low view thumbnails with all 10 of the lowest median thumbnails featuring sporting events. We can also observe that the color palette of the high view thumbnails is significantly warmer than the low view thumbnails. In addition the low view thumbnails feature more outdoor spaces and long-shots while the high view thumbnails feature more indoor spaces and close-ups.
It seems like there is a lot of rich analysis to be done here but we will leave off any more speculation for the time being.
Conclusions
Sparse Autoencoder features can pick out highly monosemantic features among youtube video thumbnails. We can be confident that these features also bear some relation to the number of views a video will receive.
However, this relation may not be particularly strong or useful. For instance, we notice that many videos of sporting events have lower than usual view counts. This may be because youtube users are not interested in sporting events, or it may be because most videos of sporting events are uploaded in an unedited form for archiving purposes which is the real cause of low view counts. Further investigation is required to understand the link between views and Sparse Autoencoder features.
Still, we hope we have paved the way for future practical uses for Sparse Autoencoders by:
identifying a domain of deep learning which is a daily practical concern for millions of creators and where interpretability has clear practical advantages
showing that a Sparse Autoencoder trained on imagenet comes at least close to providing practically applicably insights in that domain
MrBeast
A lot of variance in video view counts on youtube is known to be controlled by the channel the video was posted on. Therefore as a small extension we will apply similar analysis isolated to videos posted on the MrBeast youtube channel (currently the most subscribed channel on youtube).
Statistical Strength Assessment
We run the same analysis as with youtube-8m but due to the much smaller sample size of 329 we keep all features which activate > 0.05 on 11 or more videos rather than 400, resulting in 147 feature groups. We aggregate the lowest 10 thumbnails in each group via view mean rather than median due to unpleasant statistical properties of the median when dealing with small sample sizes.
When compared visually to the distribution of means of randomly selected 10-video groups the distribution of view means of feature groups appears distinct.
We also receive a KS test statistic of 0.9977 and P-value of 0.
We select the top-10 scoring features as the high view features as opposed to the top-100 and exclude analysis on low view features as these ended up being too closely related to the time of upload and therefore spurious. We calculate HHM as the mean of the held-out video views instead of median.
We perform the same held-out video test as with youtube-8m, except simulating 1,000,000 random 10 video groups instead of 100 and calculating the means instead of medians.
We receive a much higher, 7.3% chance of picking a value from the random distribution >= HHM. Overall it is still quite likely our high view features bear some relation to video views in the MrBeast dataset, but the much smaller sample size prevents us from having as much confidence as with youtub-8m.
Interpretability Assessment
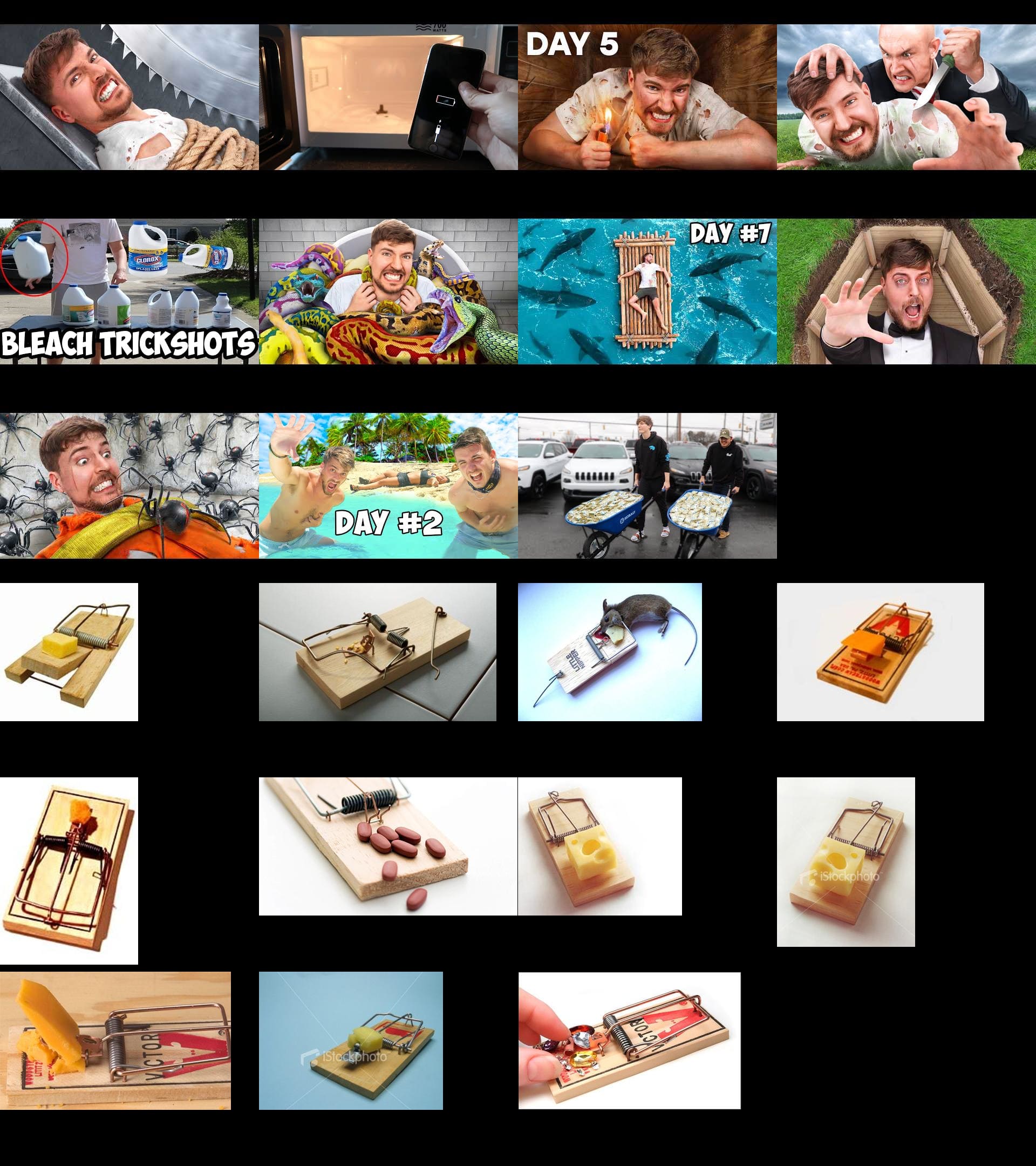
We plot the top 11 videos of each high view feature along with the top 11 images for the same feature from imagenet. These can all be found here and 3 are included in this article below.
Upon analysis only 4⁄10 of the collected MrBeast thumbnail groups appear monosemantic, however all 10 of the imagenet groups plotted below appear monosemantic. This suggests that these Sparse Autoencoder features are likely monosemantic, but that there are too few images to draw from in the dataset of 329 MrBeast thumbnails to accurately represent them.
Feature Examples
Aside from the prison feature above, the most interpretable high view features for the MrBeast channel were:


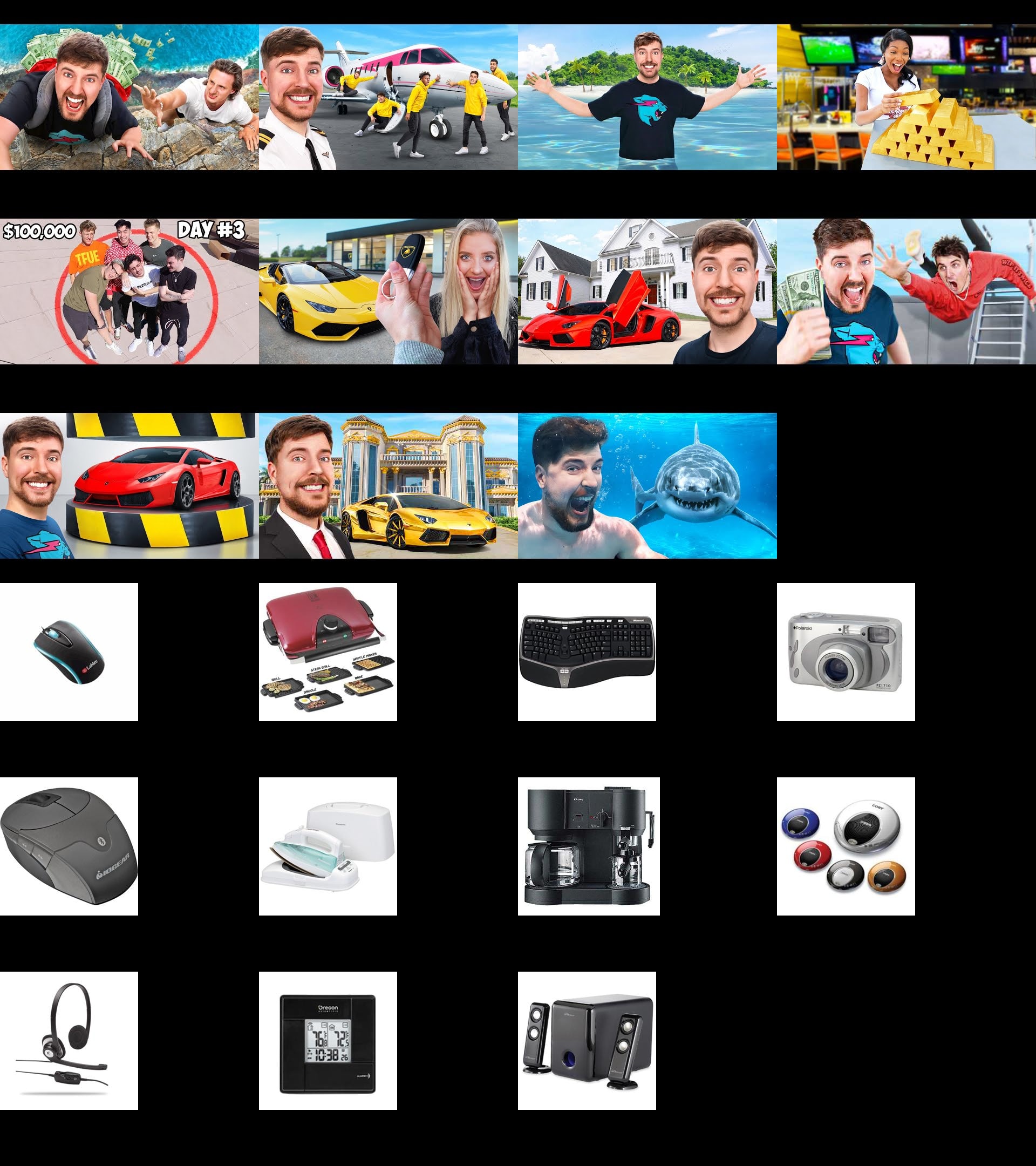
We also give an example of a non-monosemantic feature. This one seems related to wealth, or possibly vehicles, but the shark seems like a clear exception to either case and the imagenet images appear unrelated.
Final Thoughts
If any youtube creators are reading this I would be very interested in hearing whether this kind of analysis is useful. The code I used to run these experiments is here, but it’s quite messy. If there’s any interest I can clean it up properly and make the model and data I used public.
I’m not a video creator, but I wonder if this could be turned into a useful tool that takes the stills from a video and predicts which ones will get the highest engagement.
It seems like it’s possible right?
Interestingly a similar tool run by a very smart guy (https://www.creatorml.com/) is apparently about to shut down, so it might not be a financially sustainable thing to try.