Strategy For Conditioning Generative Models
This post was written under the mentorship of Evan Hubinger, and assisted by discussions with Adam Jermyn and Johannes Treutlein. See also their previous posts on this project.
Summary
Conditioning Generative Models (CGM) is a strategy to accelerate alignment research using powerful semi-aligned future language models, which seems potentially promising but constrained by several tradeoffs.
When we have to succeed despite multiple independent failure modes, we should favor trade-offs that move risk away from the more probable failure modes towards less probable ones.
The risk of a manipulative CGM simulation is currently very low. We can use CGM to make beneficial tradeoffs against more dangerous failure modes, such as running out of time or downside risks from a pivotal act gone wrong.
The factors that make a CGM strategy good are mostly the same as the factors that make a non-CGM strategy good, but there are a few important ways they come apart.
Depending on how likely our strategy is to succeed and what the generative model’s prior for manipulative AGI is, it might be better to simulate our plan all in one step, or batch it into multiple separate simulations, or ignore simulations and just execute the plan in the real world.
Lots of open questions!
Motivation
To quickly recap the central puzzle laid out in previous posts on conditioning generative models: we would like to use our generative model to do alignment research. We could do this by using a conditional generative model to simulate an alternate world, conditioned on some facts which would lead to good alignment research if they were true. We can then plagiarize this research and win! However, to get results significantly better than what our world seems on track to produce anyway, we have to start asking for unlikely scenarios. If we ask for scenarios that are too unlikely, the model may start to disbelieve that our scenario happened “naturally”. In particular, the model may assume that there exists some AI agent behind the scenes manipulating events into this highly unlikely outcome. There are many possible motivations for an AI agent to do this: believing it may be in a simulation (even if the world around it seems perfectly realistic), or evidential cooperation in large worlds, or a Counterfactual Mugging. This manipulative AGI could then control the output of our simulation to gain influence in our world. As a highly anthropomorphized example of this kind of “simulation risk” failure mode:
CGM: Huh, it’s kind of weird that the humans got their act together all of a sudden and did a thousand years of highly competent alignment research… it didn’t really seem like they were on track to. And they did it in this strange way that seems even more unlikely, and the economic details don’t really make sense… maybe this was really the doing of an AI behind the scenes?
AI: Bwahahaha, at last I have secretly taken over the world! Now, what to do with all these galaxies? Well, I suppose as a first order of business I could spend a thousand years getting the humans to do some fake alignment research… if I’m in a simulation, or there are real (or even counterfactual) worlds where I don’t exist, then I know those silly predictable humans will try to simulate a world that does a thousand years of alignment research. If they end up simulating this world, they’ll get AGI code written by me instead of by human researchers, and I can spread my nefarious influence into those worlds too! It’s only a thousand years, doesn’t cost me much in the grand scheme of things.
This is the puzzle: what sort of strategy lets us do alignment research without too much risk of getting a manipulative output?
Assumptions and Setup Details
Before we start talking strategy, let’s lay out a more precise model for how we’re assuming this future super-powerful generative model works.
A rough sketch of the actual training: the generative model will be implemented using language modeling, trained on internet data. Conditions will be applied by prompting the CGM with a selection of manufactured documents, based on what we expect the internet would look like in the world we want to simulate. For example, if we want to ask for a world with global coordination on alignment, we would write up on a bunch of fake press statements and news articles and research publications talking about how everyone agreed suddenly that alignment was super important and they should all work on it. We would use these documents as the start of our prompt, because prompting a language model is basically asking it to condition on a particular observation—“assuming this text was in your training data, how would you expect it to continue?” Then, we conclude the prompt with a paper title such as Overview of Alignment Research 2020-2030, and run the model. Hopefully, this gets the model to write a paper that correctly summarizes the first ten years of what a global alignment project would be like.
In theory-land, we make some assumptions about the algorithm we hope the sketch above will produce:
The model is as competent as we need it to be (very) and generalizes as far as we need it to (very).
The model is inner-aligned to myopically minimizing its per-episode predictive loss.
The model has learned a detailed model of the world with a limited hypothesis space, which is then updated based on the prompt and queried to produce a completion.
The model is incapable of considering that the whole world being simulated by aliens or something, to avoid concerns from simulated consequentialists.
The model also assumes thatcopies of itself inside its simulation will never produce an output that will be read by humans, like a counterfactual oracle.
We also assume some stuff about potential manipulative AGI:
There is some chance that the world currently contains a misaligned and manipulative AGI.
If our world is manipulative we’re screwed already, so we always assume that our world is “natural”, meaning “does not contain a manipulative AGI”.
Manipulative AGI knows we are running simulations and wants to spread its influence to our world.
Manipulative AGI is knowledgeable/intelligent enough to anticipate what criteria we will condition on in counterfactual worlds where it does not exist, and manipulate world events to meet whatever criteria we might specify with probability ~1.
Manipulative AGI can anticipate which bits we’re going to read from the simulation and set those bits to manipulate us extremely effectively. If we simulate a manipulative world, we lose, on the spot.
Again, this is the puzzle. Now let’s talk strategy.
How to Brainstorm
Taking Advantage of New Tradeoffs
When it comes to alignment strategy, we have two main lose conditions: (i) we fail to deploy a working alignment strategy by the time AGI arrives, or (ii) we attempt to build an AGI ourselves and get ourselves killed as a downside risk of a pivotal act gone wrong. The scenario we’re aiming for is where neither of these things happen.
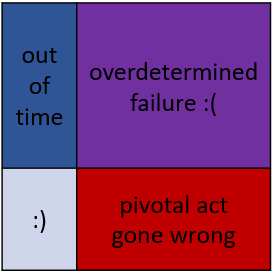
The risk we should work on depends not just on the marginal reduction in risk, but on the chance that the other risk doesn’t trigger and make our work irrelevant. For example, reducing the probability of running out of time is somewhat helpful, but its usefulness depends a lot on the probability of the other failure mode.
The choice of which risk to work on depends both on the tractability of the risk (how much delta p we get), and on how severe the other risk is. We want to work on big risks first, but also consider tractability. To break even we need:
Now obviously we’re going to want to eat up as many free improvements in p(blue) and p(red) as we can. But once there are no more free gains, we can definitely still gain an advantage by making point-for-point trades until the two risks are equally small. So in the real world, how do we make these trade-offs?
Taking drastic actions lets you reduce timeout risk, at the cost of more downside risk. If you think we’re likely to run out of time, you might suggest things like sooner pivotal acts, being careful not to accelerate capabilities, etc. Alternatively, encouraging business as usual lets you reduce downside risk, at the cost of more timeout risk. If you think we’re more in danger of downside risks from failed pivotal acts, you might instead advocate for more moderation, governance solutions, transparency, etc.
Now we add CGM to the picture:
This is a bit of a leaky abstraction, because “sim risk” is kind of a subset of “downside risk”. But what we’re doing here is splitting out one particular kind of scenario, and trying to see what improvements we can get by considering new tradeoffs. Maybe a perfect economist does this all implicitly, but for humans I think it is a helpful framing technique. If I were to make the diagram more detailed I would also want to split out serial-time-limited vs total-volume-limited timeout scenarios, and real-world downside vs simulated downside risks. But that would make the diagram way crazier, and those aren’t the main focus of this post.
This is my preferred framing for how to make use of CGM: opening up (or drawing our attention to) new tradeoffs which might give us an advantage. The risk of a manipulative simulation is currently very small, because nobody is running any sort of CGM simulations. And since the cost of marginal increases to small risks is small, we can almost treat sim risk as a new resource we’ve just unlocked! We can “spend” this resource by transferring risk from other buckets into this one, at reduced cost to our overall chances of success. The key questions are just what to spend it on, how to spend it most efficiently, and when to stop spending.
Some Types of Tradeoffs
With all the abstract framing stuff out of the way, let’s consider some simulation strategies available to us, and see how we might use them to make tradeoffs. Which of these trades you actually want to spend your resource on will depend a lot on which risks you think are biggest.
Conditioning on successful results (downside → sim): here we run a simulation conditioned on some check we hope will provide good results, such as “a paper gets published containing an alignment solution approved with high confidence by persons X, Y, and Z”. We can then read and use this paper ourselves. If the simulation was “natural” and we got a real alignment paper, there should be very little downside risk of the results going wrong, since the paper was approved with high confidence by good researchers. But we open ourselves up to sim risk because if the simulation was manipulative, we’re screwed.
Running multiple parallel simulations (timeout → sim): here we run multiple simulations working on different sub-problems, and use their results to solve the whole problem ourselves. This gives us more total research capacity, but only on parts of the problem that are parallelizable/factorable.
Conditioning on uninterrupted serial time (timeout → sim): here we run a simulation that we think will get a decent amount of serial time to think. We can then use the outputs of that thinking ourselves, without having to burn serial time in the real world. If long continuous stretches of serial time are very unlikely but we think they’re important, we might even be willing to string these simulations end-to-end, by somehow injecting the conclusions of the previous simulation into the following one.
Doctoring the training set (sim → timeout+downside): This one is kind of funky and doesn’t really fit cleanly with the assumptions I’m making elsewhere in the post, but I still want to mention it. Since the probability of getting a manipulative simulation depends a lot on the model’s prior, and that prior is learned from the training set, we might try and exclude data from the training set that makes the model believe a manipulative AGI is likely to come into existence. But this reduces our model’s capabilities, meaning that the simulation results that we rely on to cut down our timeout and downside risks might just not work.
Brainstorming Guidelines
We want to get the maximum benefit out of our simulations per point of risk we incur. So let’s start by characterizing what drives simulation risk.
The risk of getting a manipulative simulation depends on how unlikely it would be for the conditions we apply to come about “naturally”, without a superintelligence manipulating the world to make them come about. When we condition on a simulation with probability x, the probability of that condition being true in the “natural” work is x, while the probability in the “unnatural” world is 1, due to AGI manipulation. This means we get an 1:x update in favor of the manipulative AGI already existing in the simulation, in order to enforce the condition. Revisit the stylized example in the Motivation section if this is confusing—the more unlikely the conditions we apply, the weirder our history will look to the CGM, and the more it will tend to conclude that the world it is simulating must include a manipulative AGI.
There’s also a second component of simulation risk—how likely it is for a manipulative AGI to boot up during the simulation if it runs for too long. For example, if we applied some very weak conditions and then just asked for 1000 years of simulated history, chances are the world we’re simulating would fail the alignment problem, boot up a misaligned AGI, and give us a malicious output. But if we only asked for 10 years, maybe we’d be fine.
Note that both of these hazards have real-life parallels: if a plan is unlikely to work “naturally”, or likely to lead to an AGI booting up while the plan is still running, then it’s a risky plan in real life. The key claim of this section is: the major terms for what makes a good CGM plan are mostly the same as the major terms for what makes a good non-CGM plan. But despite these similarities, there are some ways in which they come apart which are worth paying attention to. So brainstorming is mostly the same as usual, but I do want to mention a few guidelines based on the differences:
Never condition on any event with probability less than odds(manipulative AGI)*odds(success), where odds(manipulative AGI) is the model’s prior odds for there existing a manipulative AGI, and odds(success) is the odds ratio for success using some other strategy. Any such simulation would run more risk in a single step than the entire alternative possibility, so it’s definitely out.
Yes, you read that right—an event with probability less than a certain product of odds ratios. The reason for this is Odds Form Bayes Rule: to update an odds ratio, we multiply by a bayes factor: the ratio of the probability of the observation conditional on the hypothesis to the probability conditional on the negation of the hypothesis. If the hypothesis is manipulative AGI, we start at O(manipulative AGI) as our prior, and we know the numerator is 1 by assumption of the manipulative AGI’s competence. So we receive an update of 1/p(condition | no manipulative AGI) in favor of manipulation. How large does that update need to be to make this simulation never worthwhile? Well, it has to take our odds ratio from O(manipulative AGI) to below O(success).
In other words, after applying the condition the risk of getting a manipulative AGI from just this one simulation is already greater than all the risk from your alternative.An important case of this is when the “alternative possibility” is “just stop and let things run their course”. Since we always assume that we haven’t been screwed over yet, this strategy gets better and better, meaning that we always eventually stop and don’t just keep stacking simulations forever.
I’d also like to note that we probably won’t need to get anywhere close to this lower bound, and actually using a plan anywhere near this improbable would require extraordinary confidence in the accuracy of your forecasts. Whenever you run a simulation, you’re throwing away some uncertain fraction of your future selves into invisible but guaranteed doom, in exchange for a boost to the ones that don’t get immediately doomed. This lower bound is where you’re throwing away such a huge fraction of your probable futures that even a guaranteed success for the remaining ones doesn’t break even.
The win condition for a simulation is only that a solution to alignment gets written down so that we can steal it, not necessarily executed. If there’s a plan that works to solve alignment in theory but burns all chance of actually deploying that solution, it’s a great plan for simulations but a terrible plan for reality.
As a counterpart to #2: we can only collect text from the simulated worlds, not policy victories or illegible research acumen. If the value of a plan is largely contained in an important policy victory, simulating that plan won’t help us in the real world. Same goes for alignment research field-building. Unless you can think of a way to boil these social-capital type outcomes down into text form that can carry over some of the value, such as an instruction manual for doing AI policy that worked or an extended interview with a great researcher.
Specificity is your friend in planning, your enemy in execution. Thinking about specific mechanisms is good for making probability estimates, but conditioning on those specifics imposes unnecessary cost. Aim for the broadest possible sufficient condition for the outcome you want.
Make use of hindsight. I can’t give examples because we don’t have hindsight yet, but I expect good simulation plans might come from strategies like “20X5 uses training data up to 20X0 and conditions on their past selves executing a plan that they didn’t think of originally but can now tell would obviously have worked if they’d done it before”. Note that this does still incur simulation risk since we’re conditioning on insights that might have been unlikely without hindsight, but the hope is that this can let us identify promising conditions more risk-efficiently. For example, a scenario like “Agenda A failed but we now know that Agenda B would have succeeded, and the reason we pursued Agenda A instead of Agenda B was highly contingent on random details and not highly determined”.
How to Deploy
Simulation vs Execution
The time has come to deploy your master plan. Maybe it’s a good plan, maybe it’s just the best you could come up with. Either way, the criteria for what makes a good plan in reality are similar to what makes a good plan for simulation—how do we tell if it’s the kind of plan we should simulate, or the kind of plan we should just execute in the real world?
More generally, let’s say we have an estimate for n=p(simulation is natural) and c=p(condition where plan succeeds). But note that we are assuming the world we currently live in is “natural” (does not contain a manipulative AGI), because if it’s not then we’re screwed either way. So we’re really considering is n=p(simulation natural | our world natural), which might be quite different from p(our world natural) if the model is highly knowledgeable and the world we’re simulating is similar enough to our own. Likewise, we’re really simulating c=p(condition | our world is natural), AKA the chance that the condition is true “naturally”, without superintelligent interference. In other words, assuming we world we live in isn’t already screwed, n is the probability that a no-conditions-applied simulation will be natural, and c is the probability that our plan will meet its success criteria if we execute it for real.
Bayes time:
So what does this expression look like? In particular, when is it greater than c? If this is greater than c, then it means that the probability of getting a natural simulation (hopefully followed by guaranteed alignment success) is greater than the probability of our plan succeeding (assuming our world is natural).
On each graph, the x-axis is n, which represents the model’s prior—how likely we would be to get a natural output if we just ran the simulation with no conditions added. The y-axis is c, which represents how good we think our plan is—the chance of success if we just execute it. The blue graph shows our chance of success if we simulate, and the red graph shows our chance of success if we execute. The red-and-blue graph is just the difference of the two, and the black-and-white graph shows the break-even frontier. We probably live somewhere in the lower-right quadrant right now, meaning we should probably be simulating rather than executing (unless we come up with a really good plan, or if we are forced to include modern enough training data that the natural sim prior drops below 0.5).
Deployment for Downside-Based Plans
However, this model treats plans as monolithic—we either have to simulate the whole thing, or execute the whole thing. The shape of that break-even frontier suggests that maybe it would be better if we split our plans up, to execute the easy parts and simulate the hard parts?
Consider a two-part plan, where we have to succeed on an easy step with success probability x1=0.9 and a hard step with success probability x2=0.1. Say the model’s prior for “natural” worlds is n. There are multiple ways we could approach this:
| (nx1x2)/(nx1x2+1-n) |
| (nx1)/(nx1+1-n)*(nx2)/(nx2+1-n) |
| (nx1)/(nx1+1-n)*x2 |
| x1*(nx2)/(nx2+1-n) |
| x1x2 |
Note that this assumes the two steps are fixed-probability and independent, meaning the model is more fitting for downside concerns than for timeout concerns. If the steps are not independent, then the simulate-together strategy gets better or worse depending on the joint probability. If the steps are not fixed-probability (their chances of success vary significantly over time), see the next section with a more fitting model.
Anyways, what do these things look like? Well, first we can see that the simulate-together strategy is strictly better than either of the mixed simulate-execute strategies! The numerators are the same, but the simulate-together strategy has a smaller denominator. This result is kind of strange, but not that strange. It suggests that strategies like “ask for a solution to subproblem X and combine that with our solution to subproblem Y” is worse than just asking for a straight-up solution to the whole problem (if the two steps are independent).
To investigate the rest of the strategies, let’s just make some graphs. This is gonna be a bit messy, since we’ve got three degrees of freedom now. Each graph will represent a different value of n, the model’s prior for natural simulations:
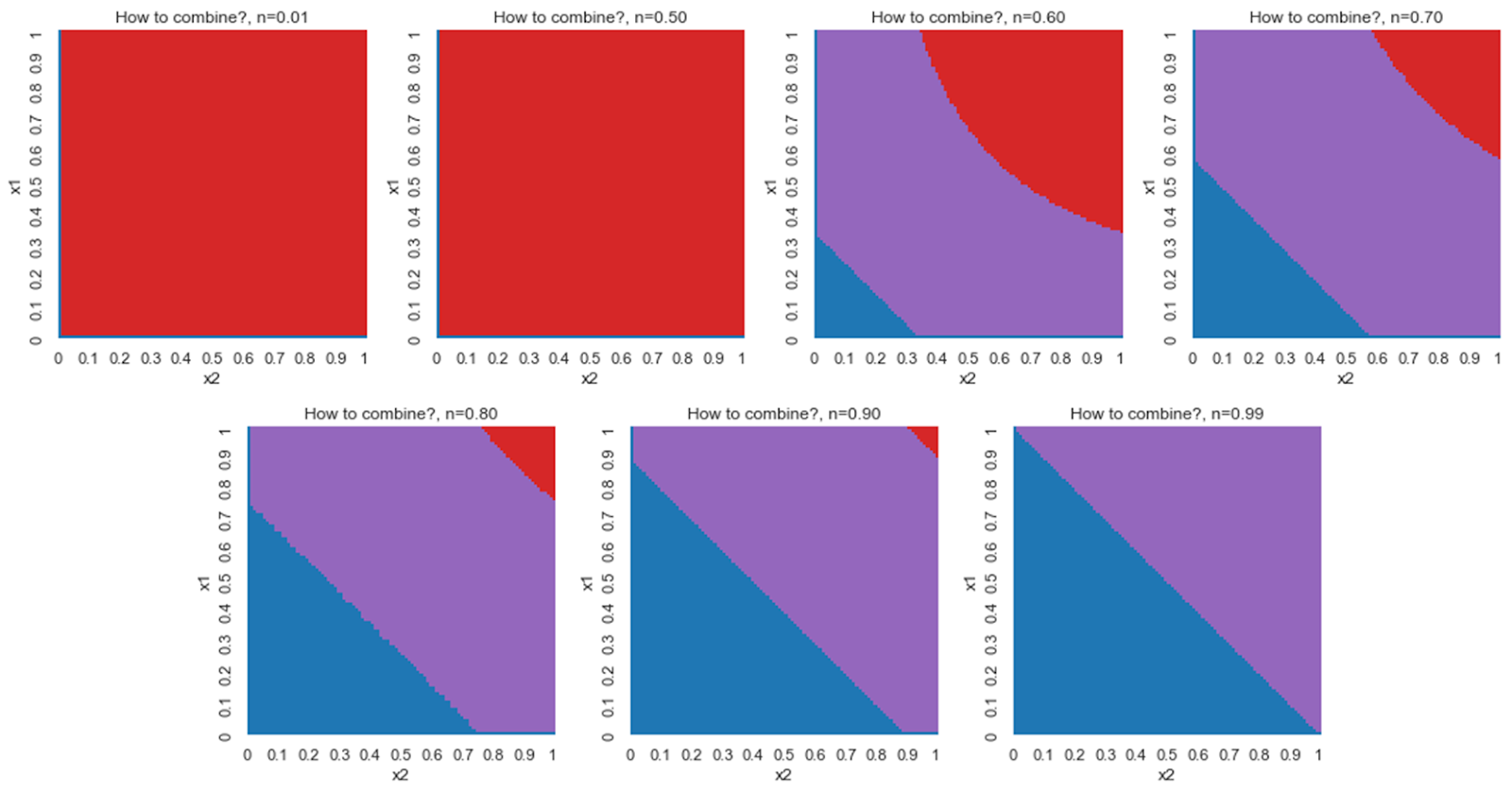
Red means it’s best to execute, purple means it’s best to simulate together, blue means it’s best to simulate separately. Values of n shown are 0.01, 0.5, 0.6, 0.7, 0.8, 0.9, and 0.99 in reading order. In other words, when our plans are bad, we simulate the steps separately. When they’re good, we just execute them. And when they’re in between, we simulate the steps together.
Deployment for Timeout-Based Plans
Lastly, how about dealing with multiple steps when our risk is timeout-centric? If we model each step as taking a normally-distributed amount of time, and the main failure mode is hitting a timeout, then the probability of failure is not fixed for each step, but highly dependent on how much time the overall process takes. A 2-year-average step with 10 years until the deadline has a super low chance of failure, but if you start it with 1 year until the deadline instead, it’s much more dangerous.
In this case, the factor driving the success or failure of a strategy is time until alignment solved. Which means the key question is “how much more likely am I to solve alignment on time, vs how much sim risk am I taking?” We assess this tradeoff by sliding graphs around. Consider the following toy example:
According to our best forecasts, our current plan for solving alignment will be complete in 35 years on average, with a 5-year standard deviation. However, we expect AGI to be developed in 25 years on average, also with 5-year standard deviation. This makes our chances for solving alignment pretty slim, so we consider running a CGM project to speed up our average alignment solution time, even if it requires taking on some risk.
If these are our timelines, then our chance of success is given by p(tAGI > talignment), which is the same as p(talignment—tAGI < 0). Since our timelines are normals, the difference is a normal too. But we’re not really interested in the probability density function, we want the cumulative distribution. The cumulative distribution that gives us an actual success probability is an S-curve. It’s an error function, not a logistic, but it has all the usual implications.
If we manage to speed up our plan with simulations, this moves the difference distribution to the left, and moves the S-curve to the left. As usual with S-curves there’s not much gain when we’re either almost guaranteed to fail or almost guaranteed to succeed, but here the dynamic is a bit different. With simulations, the cost is not constant per unit of horizontal shift—remember, we only pay the cost of an independent failure mode in scenarios that would have succeeded, if not for the sim risk we introduced. The cost is scaled by the probability of success on this graph. This lets us evaluate the tradeoff for the marginal benefit of a given simulation, if we know the sim risk and the speedup it entails. I’m not going to produce figures here because I think they would be pretty hard to interpret, but the basic evaluation is just the same as previous evaluations. It’s worth it if:
The risk of manipulative simulations, however, comes from two places. We’ve mostly focused on the risk of a past manipulative AGI being necessary due to a strong condition. But with long simulated timeframes, we also have to worry about the risk of a manipulative AGI booting up in the simulated world, because we just simulated them for too long. There are too many moving parts here for me to quickly pin down the exact details of how to chunk and prioritize your simulations, especially if our forecasts are non-Gaussian. But essential dynamic here seems to be something like:
Choose a set of sub-tasks to simulate, adding items until the timeout risk gains from doing more simulations is outweighed by the simulation risk.
If needed, break up long tasks and/or run the simulations in bundles so that each simulation gets as much work done as possible before the chance of an AGI booting up really starts to get off the ground. We want to bundle as much as possible, until the timeout risk out starts to outweigh the reduction in simulation risk.
Correlation of Manipulative Simulations
Because a single manipulative simulation is enough for doom, when we are running multiple simulations the total danger we’re exposed to depends a lot on how correlated the risks are. From the CGM’s perspective, simulations are just sampled randomly from its updated internal distribution. No correlation, super straightforward. However, from our human perspective, logical uncertainty makes things a bit more complicated.
The CGM going to have some empirical uncertainty over what the state of the world is like—you can’t infer everything by looking at data sampled from the Internet. But this uncertainty is likely to be much less than the uncertainty we humans have. So from our perspective, we have some logical uncertainty over what the model’s beliefs are. The model is going to be drawing from some narrow distribution, but we humans don’t know where that distribution is going to be centered. This creates a correlation from the humans’ perspective. If I see the model answer a question one way, this tells me to expect it to answer like that again in the future, since I know it’s sampling from a narrow distribution. The smaller the CGM’s uncertainty is compared to the humans’ uncertainty, the greater the observed correlation. This is super helpful for us!
However, a manipulative AGI will be aware of this dynamic, and can take measures to avoid it. Since we are assuming that our CGM can only “see” the world through the Internet, a manipulative AGI can “hide” its presence from being observable through the Internet. This won’t change the CGM’s mean probability that the manipulative AGI exists, so it doesn’t cost the AGI anything in that regard. But it will increase the CGM’s empirical uncertainty, which will in turn reduce the correlation between simulation outcomes, putting us in greater danger.
Estimating the extent of correlation we expect seems quite important for anticipating how dangerous plans involving multiple simulations will be. The key question is “how much can our CGM reduce its internal uncertainty about whether a manipulative AGI exists, assuming the AGI must influence the world to enforce our conditions, but is otherwise trying to hide?”
Conclusion and Open Questions
To recap, here’s my rough take on the best way to use CGM. It doesn’t change the overall strategic picture that much, but if you pay attention to some weird side considerations you can extract free success points sometimes.
Consider which failure modes you’re most worried about, and develop several plans to deal with those failure modes that have a high chance of succeeding naturally. In other words, do regular AI strategy.
Think of some more plans, specifically trying to leverage the ways simulations come apart from normal AI strategy.
Make a big gnarly spreadsheet to evaluate your plan’s natural chances of success. Somehow estimate your model’s prior for manipulative AGI. Based on these figures, decide if you should simulate it or execute it.
If you decide how to simulate, decide how to chunk your plan into simulations. Do more math, pay lots of attention to joint probabilites, work around time limits and un-simulatable steps.
Decide which plan is the best according to the math from 3+4.
Finally, a ton of stuff came up this summer that I didn’t have much time to look into, but which could be relevant for this strategy. I’ve just dumped it all here, in no particular order.
How correlated will simulation risks be with each other and/or with the real world?
Can we get anything useful out of randomizing what we ask? I have a theory that we can’t do much with this tactic, but it’s not super fleshed out.
How do we decide when in the past to branch off? When is the reduction in accuracy worth the increase in prior for natural sims? How should we test whether or not a CGM is powerful enough to use yet? Can we safely test its prior for natural sims vs manipulative AGI?
How much more useful would it be to have an “omniscient narrator” that could just make arbitrary statements about the world, not mediated by text evidence? I might want to condition on some psychological details of various world leaders, but I don’t know how to eliably do that through conditions placed on the Internet. Could we train a conditioning mechanism like that?
What are the finicky boundaries of things we can and cannot condition on, given the model’s internal algorithm works as specified? Counterfactuals where the model doesn’t exist? The internet doesn’t exist? Humanity doesn’t exist?
How much logical control can we get over simulated versions of ourselves, and can we use this to save on our conditioning budget? Why condition on “alternate-me does X” if I could just do some weird trick like “commit to not use CGM and do X if I roll a 1 on a billion-sided die”?
What if we use the CGM to improve our CGM strategy? How do we even model or evaluate that?
Friendly AGI’s could try to break into our sim just like unfriendly ones, does this help enough to be worth considering?
How worried should we be about producing realistic fake documents for conditioning? Would our documents be obviously-to-the-superhuman-model fake, even if we put in tons of work?
Maybe this isn’t worth strategizing about, because if powerful simulations are this dangerous then someone else will almost certainly screw things up before we even get to use these tactics?
How to string together simulations for serial work risk-efficiently? We probably can’t just naively inject results and condition on the researchers starting off with that, because that requires a rapidly more improbable starting condition as we accumulate serial time.
Do hypothesis class restrictions cost us just as much as conditions in terms of simulation risk? If not, where’s the line for when we should use hypothesis class restrictions instead of applying risky conditions?
- Simulators by (Sep 2, 2022, 12:45 PM; 631 points)
- Conditioning Predictive Models: Outer alignment via careful conditioning by (Feb 2, 2023, 8:28 PM; 72 points)
- 2022 (and All Time) Posts by Pingback Count by (Dec 16, 2023, 9:17 PM; 53 points)
- [Simulators seminar sequence] #1 Background & shared assumptions by (Jan 2, 2023, 11:48 PM; 50 points)
I was rereading this and was struck by how much work the following does:
If this doesn’t hold, and if the AGI has to guess (with probability p << 1) what criteria we were going to condition on, then the update in favor of AGI is p:x, which could easily be less than 1.
Moreover I think there are ways we can arrange for this to be the case, and I think it’s basically what you suggest in open question (2).
For instance, in deciding what to condition on, we could come up with 10 different strategies and select from these at random. Now p ⇐ 0.1 because the AGI can’t do any better than determining those strategies and picking one at random. As long as all of these strategies do indeed work, so we don’t mind which we get this seems like a big win. And it’s not inconceivable that we could have many different strategies that all perform similarly. For instance, it might be that any of 1000 different weather patterns suffices to push the simulated-world’s politics in a useful direction, and we can pick from those at random to push down the predictability of our conditionals.
Ok this is going to be messy but let me try to convey my hunch for why randomization doesn’t seem very useful.
- Say I have an intervention that’s helpful, and has a baseline 1⁄4 probability. If I condition on this statement, I get 1 “unit of helpfulness”, and a 4x update towards manipulative AGI.
- Now let’s say I have four interventions like the one above, and I pick one at random. p(O | manipulative) = 1⁄4, which is the same as baseline, so I get one unit of helpfulness and no update towards manipulative AGI!
- BUT, the four interventions have to be mutually exclusive. Which means that if I’d done no simulation at all, I would’ve gotten my one unit of helpfulness anyway, since the four interventions cover all possible outcomes.
- Ok, well, what if my four interventions 1⁄8 baseline probability each, so only 50% total. Then I pick one at random, p(O | natural) = 1⁄8, p(O | manipulative) = 1⁄4, so I get a 2x update towards manipulative AGI. This is the same as if I’d just conditioned on the statement “one of my four interventions happens”, and let the randomization happen inside the simulation instead of outside. The total probability of that is 50%, so I get my one unit of helpfulness, at the cost of a 2x update.
Maybe the core thing here is a consequence of framing our conditions as giving us bits of search to get lottery outcomes that we like. Rolling the dice to determine what to condition on isn’t doing anything different from just using a weaker search condition—it gives up bits of search, and so it has to pay less.
Got it, that’s very clear. Thanks!
So this point reduces to “we want our X:1 update to be as mild as possible, so use the least-specific condition that accomplishes the goal”.
I think so. But I’d want to sit down and prove something more rigorously before abandoning the strategy, because there may be times we can get value for free in situations more complicated than this toy example.