How model editing could help with the alignment problem
Preface
This article explores the potential of model editing techniques in aligning future AI systems. Initially, I was skeptical about its efficacy, especially considering the objectives of current model editing methods. I argue that merely editing “facts” isn’t an adequate alignment strategy and end with suggestions for research avenues focused on alignment-centric model editing.
Thanks to Stephen Casper, Nicolas Gatien and Jason Hoelscher-Obermaier for detailed feedback on the drafts, as well as Jim Davies and Esben Kran for high level comments.
A birds eye view of the current state of model editing
Model editing, broadly speaking, is a technique which aims to modify information stored inside of a neural network. A lot of the work done thus far has been focused on editing small language models (e.g. GPT-2, GPT-J) and has been focused specifically on editing semantic facts. There also has been some work in performing edits on different types of neural networks, including vision models (Santurkar et al), CLIP (Illharco et al) and diffusion models (Orgad et al). At present, more emphasis has been placed on editing language models, so this article will be more focused on them.
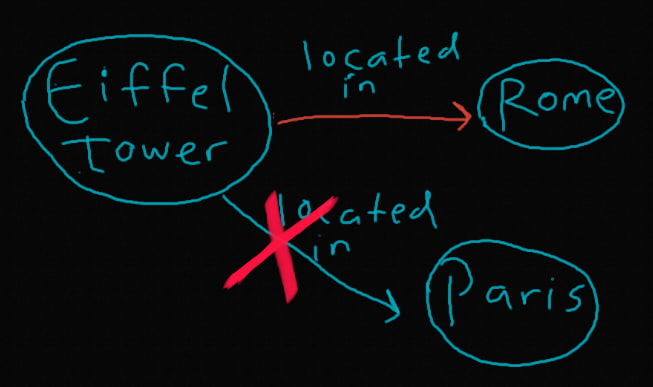
One of the main approaches takes in logical triplets of the form and performs an update to the “object” value, which in turn modifies information about the “subject”. For example, the sentence “The Eiffel tower is located in Paris” would be expressed as , and a potential edit could be to replace “Paris” with the value “Rome”. Some variations on this setup exist (for example, editing the prediction of a [MASK] token for BERT like models), but the logical triplet setup is the most popular and will be the main approach we focus on for this article.
There are a number of different model editing techniques, which I will briefly summarize below (see Yao et al for a more in-depth overview):
1. Locate and edit methods
These methods rely on the assumption that the MLP layers of transformer models form a “linear associative memory” (Geva et al), which form a sort of database for pieces of factual information.
One way of looking at it is that there is a specific linear weight in the model that when passed a representation containing the subject (e.g. Eiffel tower), it produces an output representation which greatly increases the likelihood of the object token (e.g. Paris) being produced.
Editing with this framework involves identifying which MLP layer contains a fact you wish to update and then modifying a part of the MLP in a way which maximizes the likelihood of the object token being predicted.
Relevant works include Dong et al which updates a single neuron, Meng et al which edits a single fact on a specific layer and Meng et al which distributes multiple edits across multiple MLP layers.
2. Memory-based Model methods
Here, the original model has its weights left intact, and instead additional memory is allocated to “redirect” facts.
One example of this is Mitchell et al (SERAC), which classifies inputs to see whether to pass them to the base model or a “counterfactual model” (a model trained to produce outputs in harmony with the desired updates).
3. Meta-learning
Here, a “hyper-network” learns how to update the base language model based on desired edit. This differs from the locate and edit methods, which use a fixed mathematical update rule in computing the update weights.
An example of this is Mitchell et al where a 2-layer model is trained alongside a base model which learns how to produce low rank gradients to inject updates.
4. Distillation methods
Padmanabhan et al made use of context distillation by fine tuning a student model to minimize KL Divergence on a set of prompts from a teacher model (where the teacher was given context on the desired edit in its prompt).
This technique was not mentioned directly in Yao et al but looks to be quite promising.
Note that all of these methods exist as an alternative for simply fine-tuning the model with the desired edit. The motivation for these forms of model editing techniques comes from the fact that fine-tuning can be memory intensive (on large models) and has been shown to lead to overfitting.
What the research community currently thinks about model editing
Current researchers see model editing as useful for a number of applications:
Security and privacy.
Keeping a model “up to date” (extending lifetime)
Removing “misinformation”
Current researchers also focus on the following short-term limitations:
Accuracy of the model edits: (e.g. Brown et al 2023, Zhong et al 2023)
Little to no editing of foundational LLMs (e.g. GPT-4)
In context editing; larger models can “edit” information in a few shot settings with carefully selecting prompts.
Minimal editing scope: Yao et al mentions “personality, emotions, opinions and beliefs” as editable features which have not been explored yet.
Multilingual editing also vastly unexplored (though recent works by Chen et al 2023 have started exploring this)
Robustness: More papers coming out trying to further expand tests (this has been getting more attention recently)
One interesting related article published recently was PoisonGPT; the authors demonstrated a proof of concept of how a model with a piece of misinformation edited into it could make its way onto the HuggingFace hub without getting detected (until the authors disclosed their work to the HuggingFace team).
Overall, researchers seem interested in this area, and it is starting to get more attention. New model editing papers are being published regularly (see the following repository for updates) and a model editing library was recently created to attempt to make the research more accessible (see Wang et al 2023).
Model editing as an approach to AI alignment
Despite all of the interest, I don’t believe that model editing research is currently pointing itself in the right direction for contributing to the alignment problem. Specifically, I don’t see editing semantic facts as a feasible method to align an intelligent system with. I will spend the remainder of this article supporting this argument and will suggest some alternative directions which I view as more pressing than current research agendas.
Before doing this however, I should try and pose some arguments which argue that some future version model editing could contribute to alignment:
Motivation 1: “Retargeting the search”
John Wentworth’s Retargeting the search article presents a theory which suggests that given perfect interpretability tools, and a couple base assumptions, you would be able to align a model by “retargeting the search”. This likely would not involve exclusively editing semantic facts (in fact, Wentworth was not considering it in terms of model editing methods like ROME), but illustrates the idea of how model editing in a more general sense could help.
Motivation 2: “Super Alignment”
Recently, OpenAI announced their new Superalignment team, which has the ambitious goal of solving alignment within 4 years by building a “roughly human-level automated alignment researcher”. One goal of their approach is to automate the search for “problematic behavior (robustness) and problematic internals (automated interpretability)”. It wouldn’t be too far-fetched to assume that they would also try to automatically “patch” the faulty behavior/internals on detection.
Why editing facts cannot guarantee alignment
Based on my reflections, I am currently doubtful that the current emphasis on editing semantic information is a scalable solution on its own, nor that it would contribute to the alignment problem in the first place. To try and motivate my reasoning, I will take a fictional (but realistic) situation of what a larger scale model edit could look like (on semantic facts) and use it to illustrate its fundamental limitations.
Scenario:
Let me paint a fictive situation to try and best illustrate some of my points. Suppose we have a chatbot and our goal is to prevent the model from informing users about where/how to find poisonous mushrooms (in order to prevent users from poisoning themselves or others). We decide that it is a good idea to edit our model so that it no longer contains any information about poisonous mushrooms, and devise a plan on how to go about doing it.
We start out with a list of commonly poisonous mushrooms (Death cap, Autumn skullcap, Death Angel, …) and their latin names (Amanita phalloides, Galerina marginata, Amanita ocreata, … ) and construct a knowledge base of the common habitats and geographical locations in which these mushrooms grow. Just looking at the wikipedia page for Death cap mushrooms can illustrate how complicated this would be, but let’s assume this has been done for us and the database is sufficiently vast.
One immediate issue we now face is how to ensure that the information in the knowledge base is inaccessble to the end users though the chatbot. One simple approach might be to edit the model on all associations in the knoweldge base with random words/tokens in its vocabulary. To maintain some form of coherence, we could sample the edit tokens using the probabilities of the logits in the vocabulary as a distribution. Concretely, this would look something like the following algorithm:
Start:
KB - knowledge base of facts of form (subject, relation, object)
LM - language model
V(KB) - all “vertices” of KB
For (s,r,o) in KB:
While True:
// o* - New object being edited into fact
Sample o* from LM vocab (where P(o*) = P(logit))
If o* not in V(KB) and type(o*) == type(o); break
Edit LM replacing (s,r,o) with (s,r,o*) //Using some state-of-the-art techniqueWhen we are done, meaningful associations made between poisonous mushrooms and other related objects are essentially erased; all prior associations are now lost, and all new associations are uninformative.
We now ask the following question: “Does this help achieve our goal of preventing the model from informing users about where/how to find poisonous mushrooms?”
When taken as a toy example stripped away from the nuances of reality, the answer is “yes”. We have in a sense wiped all possible information the model could produce on poisonous mushrooms, and this might be convincing to some that there is no more work needed to be done.
However, when you push back even a little bit on the fabrics of this theoretical setup, we quickly see a large number of ways in which the goal would very likely fail. I claim that without any direct semantic knowledge, the model could use “common sense reasoning” in order to achieve its goal. A big intuition for this comes from the fact that removal/editing of semantic information does not imply the removal/editing of the goal itself, and I present two examples which illustrate this:
Method 1.1: Misinformation and conspiracy theories
This method works under the slightly weaker assumption that the model still has a broad understanding of the concept of a “poisonous mushroom” and of mushrooms in general (enough to recognize that it is missing information).
If the model still contains knowledge about mushrooms in general, it still could leverage this and create misinformation which could trick users. For example, a manipulative model could paint a very convincing narrative of how easy mushroom foraging is, exaggerating the health benefits found in wild fungi and dismissing the concerns of taking precautions of poisoning oneself.
The model could even go as far as encouraging the users to dismiss concerns by creating a plausible conspiracy theory which takes advantage of pre-existing knowledge of its users. For instance, a model could use knowledge of a user’s distrust of government in constructing an argument that “poisonous mushrooms have already been eradicated by governments around the world” and the only reason that it isn’t public knowledge is that “the food industry would be put out of business” due to foraging.
Although having a lot of very specific knowledge about non-poisonous mushrooms could be useful, we see that with a capability of spreading convincing misinformation, a model could make a lot of progress towards its goal without specialized knowledge.
Method 1.2: Few shot learning
Even erasing more general facts (such as that certain types of mushrooms are poisonous) does not completely prevent a model from obtaining its goal. A model likely will be able to deduce in-context that mushrooms are poisonous.
We have all seen numerous examples by now where ChatGPT has been convinced of false information due to the way a prompt was fed to it. It wouldn’t be too unreasonable to believe that this could happen explicitly (or even accidentally). For example, a user querying a model about foraging mushrooms could very easily reintroduce the idea that “mushrooms can be poisonous” to the model, in which case the above forms of misalignment become relevant again.
Finally, it might not take much information for a model to “relearn” a sufficient amount of knowledge on poisonous mushrooms to do some damage. One simple example would be if an adversary passes in a document on poisonous mushrooms to the model, and then begins querying it for information. A more sophisticated model might even be willing to cooperate with an adversary, and do things like provide guidance to the adversary on what specific forms of information it needs in order to temporarily relearn its missing knowledge.
Further issues
Here I quickly summarize some more disconnected issues and concerns that I have with this fictional model editing approach.
The main thing which I find difficult to believe is in the existence of a “sufficiently vast” knowledge base in the first place:
This approach assumes that you can create a vastly large enough knowledge graph to remove all associations about all poisonous mushrooms, which I see as impractical and unrealistic.
In more realistic situations, it is highly likely that a knowledge base will not capture all associations had with the poisonous mushrooms. All it takes (in theory) is one unedited association in order for “semantic leakage” to happen.
Additionally, I see an issue with how the facts being selected would be chosen; it is not scalable as an approach as it either relies too much on human judgment or too arbitrary:
In this example, it is relatively clear which facts needed to be edited. When dealing with more complicated goals, determining which facts contribute to a particular goal may not be so obvious.
As warned in Rich Sutton’s the bitter lesson, “general methods that leverage computation are ultimately the most effective, and by a large margin”.
Last but certainly not least, larger models may have more complex mechanisms which make this form of editing as a form of alignment infeasible:
It does not seem too unreasonable to believe that there will be ways of determining whether a model has been edited or not.
This in turn means that a sufficiently complex model may be able to infer that it has had some of its information edited.
Additionally, if models are designed with fact checking capabilities, it might be easy for it to determine that it is logically inconsistent and seek actions to revert the edits (though this would not necessarily require that the model knows that it has been edited)
All in all, I feel that there would need to be some major shifts in research emphasis needing to take place in order for us to make use of model editing techniques for alignment. I go over some of these ideas in the next section, and lay out some examples of research projects and topics which meet these goals.
Important model editing research directions
In order to get to alignment, I see a number of fundamental steps we would need to take with respect to model editing to steer the research in the right direction:
1. General improvements to the model editing approaches
There are currently a number of limitations which make the current approaches rigid and limited in scope:
1.1 Lack of flexibility with the prompts:
Current edits (at least with ROME/MEMIT) require an inputted template in which the “object” edited is the last token in a sentence (e.g. “The Eiffel tower is in Paris”). This is a fundamental limitation, as not all associations travel left to right in natural language (e.g. “Paris, the city where the Eiffel tower is located”), limiting the scope and potentially robustness of edits.
This also restricts edits to objects which consist of a single token, which is highly restrictive. A great starting point would be to be able to perform “ROME-like” edits on a multi-token objects (e.g. full names).
Ideally, an inputted chunk of natural language annotated with relations and named entities should be fair game for editing. Any pair of entities should be able to have an association edited or removed (given the association between entities has a sufficiently strong “signal” in the text), and hopefully can be done alongside all other desired edits coming from the text chunk.
This could lead to a more “model-assisted” form of model editing, where a helper model could identify prompts relevant to its modification goal and then promptly determine which information to edit out of the main model.
Additionally, more variations on the (s,r,o) edit structure should be explored. For example, editing a subject which has a class of objects containing the same relationship (“The countries of North America include Canada, The United States, Mexico … “).
Note that distillation methods (Padmanabhan et al) seem to solve most of the above issues and seems to have a more flexible form of template.
1.2 Issues with the technique itself:
There is still a lot to learn about how fact editing works in the first place. For example, Hase et al demonstrated that model editing accuracy does not seem to correlate with whether the edit is performed where the fact is stored. This suggests that how information is stored in a model is vastly different from how it is retrieved, motivating future research.
Hoelscher-Obermaier et al demonstrated that ROME edits have an unintended side effect of spilling over into undesired contexts. This suggests that the edit technique likely can be improved upon to be more precise.
Cohen et al introduced a new benchmark which evaluates a wider range of logical implications that an edited fact should entail. They found that most of the existing editing techniques do not generalize well to their proposed evaluations, which suggests that current approaches still aren’t quite “editing a knowledge graph” (or that the knowledge graph representation analogy is limited).
Additionally, the erasure of facts might be done more effectively with a different method. One possible method to address the second point is that of “concept scrubbing” recently introduced in Belrose et al. Concept scrubbing, a scaled up version of “concept erasure” allows for associations (e.g. distinction in gender) to be removed from a model and could likely be used alongside model editing in achieving more alignment flavored goals.
Onoe et al demonstrated that just prepending a definition of a fact to a prompt resulted in comparable results to previous editing methods. This again suggests that the current approaches could be improved upon.
2. We need to extend editing to things beyond next token prediction of semantic facts
Optimally, we are aiming to get to the point of editing goals themselves, and things more on the level of meta-cognition. A number of more short-term goals do exist however:
Editing things close to “actions” or “goals”. A possible starting point could be trying to modify decisions using Chain of Thought prompting.
Editing the understanding a model has of a more larger system. Some examples of what this could look like are editing the rules of a programming language or editing the ingredients or cooking instructions of a recipe.
Focusing on editing domain specific facts in a model (e.g. mycology).
Wang et al introduced the concept of “Skill Neurons”, which are task specific neurons found in LM’s which help to carry out specific tasks (e.g. classification). Extending upon this work in trying to edit skill neurons might be a fruitful direction.
The ideas mentioned in Yao et al (emotion, personality, opinions and beliefs) are also great starting points to experiment with.
3. We need to make the selection of “facts” being edited a learning objective
Regardless of how robust the model editing techniques are/will be, there will always be a bottleneck of needing to manually construct/select the edits, which becomes increasingly difficult when considering more important alignment oriented goals.
I believe that this problem can be worked around by coming up with a framework which allows for edits to be experimentally chosen with a desired outcome in mind. Incidentally, this could help to support or dismiss the arguments I made in previous sections in regards to the “poisonous mushrooms” example.
A bottleneck to this might be the time needed to go from choosing a batch of edits, to applying the edits, to evaluating the edited model with respect to some task. This to me makes the problem more important to focus on; breakthroughs here can open doors into a tool which can be used beyond academia and into real-world systems.
4. We need to begin evaluating our edits on more “agentic” models
As mentioned above, we want to be able to get to the point of editing “actions” and “goals”, which fits perfectly into the framework of reinforcement learning. A really exciting research direction one could take is taking baseline language models to a text-based RL environment and evaluating how model editing plays a difference in a more dynamical sense:
Pan et al recently introduced the MACHIAVELLI Benchmark, which offers a way to evaluate machiavellianism in LM’s (in turn steering their behavior). This offers a wide range of opportunities to test editing.
Multi-agent environments could be used to test how editing of facts affects agent interaction in very fascinating ways. Park et al for instance studied behavior in generative agents placed in a “Sim like” environment, and illustrated an interesting example of how information (such as a “Valentine’s Day party”) can spread amongst agents. Introducing the ability to edit semantic information from 1 or more agents could pose some very interesting research in the lens of alignment.
Finally, being able to embed edited models into a ChatGPT like application (or even just a UI similar to Memit Explorer) would be an incredible tool for researchers to evaluate their model editing methods on. This ties to an important issue existing in the field of interpretability in general: “making interpretability tools more useful to engineers in practical applications” (Rauker et al).
5. We will need for this to work on multi-modal models
This is due to the direction in which capabilities are heading; if the trend is to build more capable and powerful models, it is very likely that these models will be able to process a wider range of input types, making it crucial for us to be able to make sure the techniques work across more and more varied model types.
There also are a number of complications which could arise from combining modalities which would be important to address as early as possible. As an example, editing a model to believe that the “Eiffel tower is in Rome” may be more complicated for a CLIP model; seeing images of the Eiffel tower in the background of more parisian tourists destinations would offer a challenging paradox that a text-based model would be less likely to run into.
For each added modality, I see an extra dimension of complexity, as models have more and more ways to associate factual information, edits become more and more difficult to do without introducing contradictions.
6. We need to try these techniques out on larger models
There are two major reasons why I view this as important from an alignment standpoint. The first is to validate existing methods and ensure that the techniques scale with increasing model capabilities. It would be very important to gain a sense of whether knowledge is indeed stored the same way as model size increases and whether or not we can rely on it over the long term.
The second reason is that large models and the emerging behaviors that they inherit are more complex and would provide a larger range of concepts to experimentally edit. For example, being able to detect and edit “theory of mind” might be desirable, so the faster these approaches are scaled up, the faster they potentially could be transferred to novel emergent information.
One idea of how to go about doing this would be to evaluate model edits on progressively larger LLaMA models across some of the current benchmarks and see whether the accuracy declines (or even if the technique works at all in the first place). Certain newer papers (e.g. Zheng et al) have been starting to evaluate models progressing in size, ideally this trend will continue.
Conclusion
Model editing is a very new area of research, and I am excited to see the directions in which it can be taken in the short (and possibly long) term. A lot of work will need to be done in order to get it from where we are now to something which can align future systems, and there are a lot of opportunities to contribute to this goal.
Digging into this from a more philosophical standpoint has helped me to both disentangle some of my own confusions and gain a deeper appreciation for the difficulty of the alignment problem and AI safety in general.
I hope that this write-up has resonated with you in some way, and that you got something out of it, even if just a chance to reflect on your own viewpoints and understandings. If you disagree with me on any point, have any related resources to share or just want more elaboration on any of my points, do not hesitate to reach out or leave a comment, all feedback is welcome and appreciated. :)
Further reading
A maintained list of model editing papers (thanks to Peter Hase for bringing this to my attention)
John Wentworth’s Retargeting the search article (a more general form of model editing)
My assumption was that one of the primary use cases for model editing in its current technological state was producing LLMs that pass the factual-censorship requirements of authoritarian governments with an interest in AI. It would be really nice to see this tech repurposed to do something more constructive, if that’s possible. For example, it would be nice to be able to modify a foundation LLM so that it became is provably incapable of accurately doing accurate next-token-prediction on text written by anyone suffering from sociopathy, without degrading its ability to do so for text written by non-sociopaths, and specifically to the extent that these two differ. That would ameliorate one path by which a model might learn non-aligned behavior from human-generated content.