Summary: This is a quick overview of the current state of our system AI Safety Impact Markets: We want to give donors an improved ability to coordinate so that their diverse knowledge can inform our crowdsourced donation recommendations. AI Safety Impact Markets will help them identify the most impactful projects and get the projects funded more quickly too. (More on our long-term vision can be found in the article “The Retroactive Funding Landscape.”)
| Please send me your name, email address, and approximate annual donation budget in a private message (or through this form) if you are interested in using AI Safety Impact Markets to inform your giving! We publish only the sum of all budgets. It’s crucial for us to motivate expert donors to share their donations. |
This is an edited transcript of an eponymous talk. I’ve held this talk at EAGx Berlin and Warsaw 2023 among other venues.
The Funding Constraint

Great entrepreneurs who start highly impactful charity projects exist in various countries around the world and in lots of different fields that require highly specialized expertise. They also speak a number of different languages and have all their own social circles in the various countries that they live in.
That makes it difficult for an individual donor in Berkeley or London to identify but a tiny fraction of them.
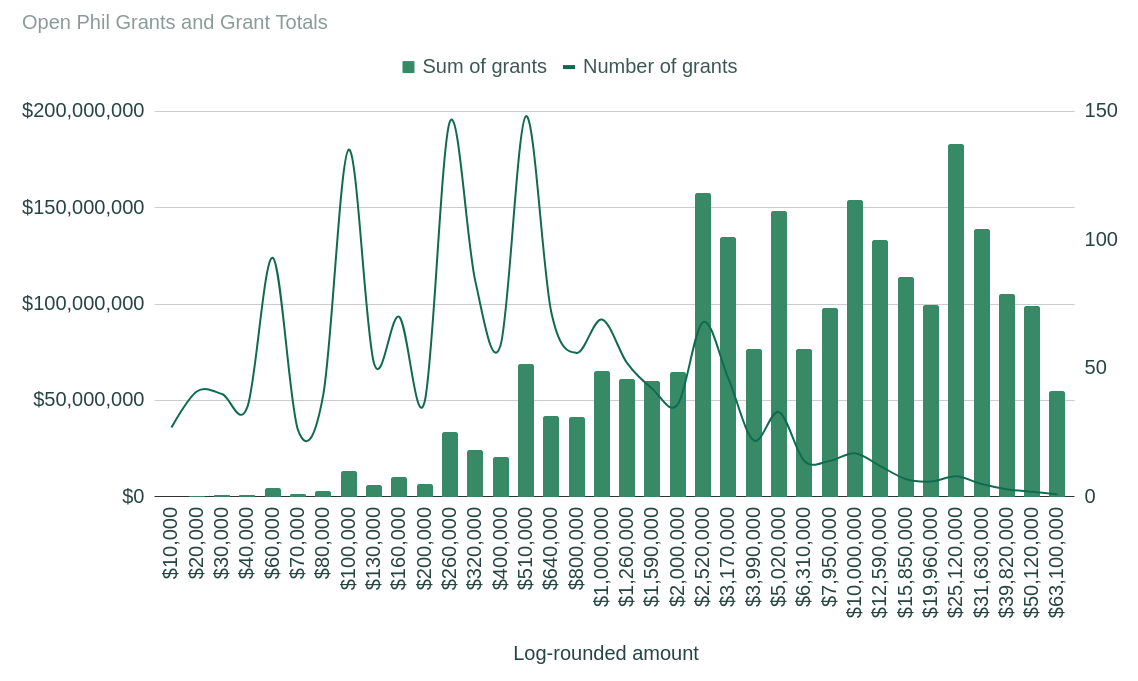
Even really big foundations like the Open Philanthropy Project have problems with this. The Open Philanthropy Project can invest a lot of time into researching grants if the grant size is upward of $1 million or possibly $100,000 so that they make many grants in that area, measured by the total of those grants. But below $1 million the total grant size starts to trail off, and below $50,000 the number of grants drops off too. If they don’t already know the field and the founders, it becomes more and more difficult for them to research the projects efficiently enough that it’s still worth it for them given the small grant sizes.
That mirrors how venture capital firms would probably also love to invest the first $100,000 into all the future unicorns, but since they can’t identify them at that stage, or only vanishingly few of them, they depend on business angels and the founders’ friends and family to take the first step.
But we’re now in a world where AI safety projects struggle to raise $2,000 to make ends meet. So that gap below $1 million, particularly below $100,000, is critical. We need to coordinate the nonprofit equivalents of business angels so they can fill the gap!
Donors to the Rescue
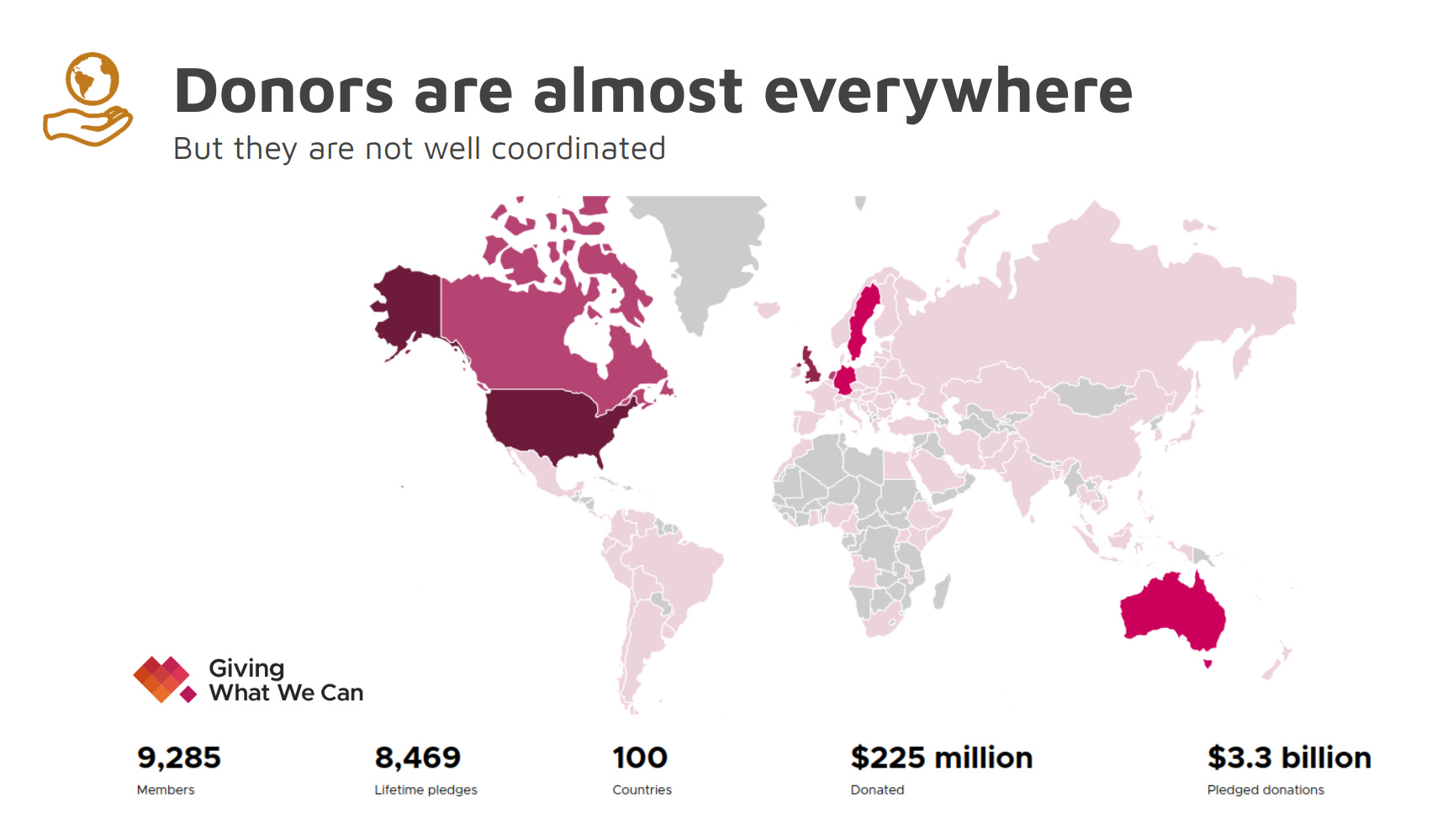
How do we help donors coordinate? The good thing about individual donors is that they are almost everywhere in the world. If we just look at Giving What We Can data we see Giving What We Can pledge takers in 100 countries around the world. That’s a really sizable network that, if it were better coordinated, could serve to fill all of these funding gaps.
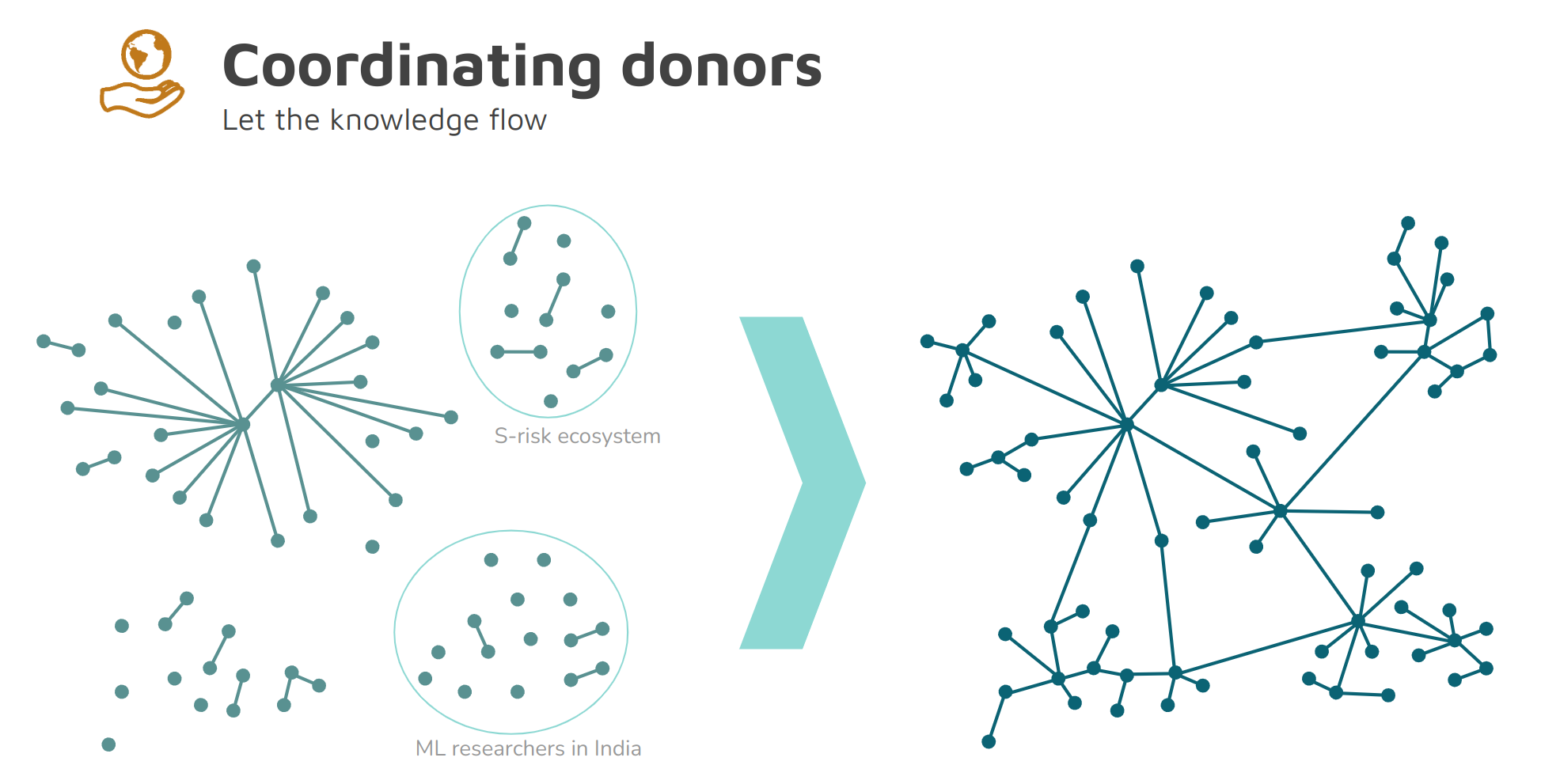
On the left, you can see the donor network as I intuit it today. There are some relatively well-connected funders but there are also lots of individual donors and lots of individual charity entrepreneurs. They’re largely disconnected or form small disconnected islands. We would like to rather move to the network on the right where all of these clusters are somewhat connected. It’s not perfect but everyone has connections to all the other funders via relatively few intermediaries. It’s much easier for projects to get funded and for donors to actually identify the most impactful projects on the margin.
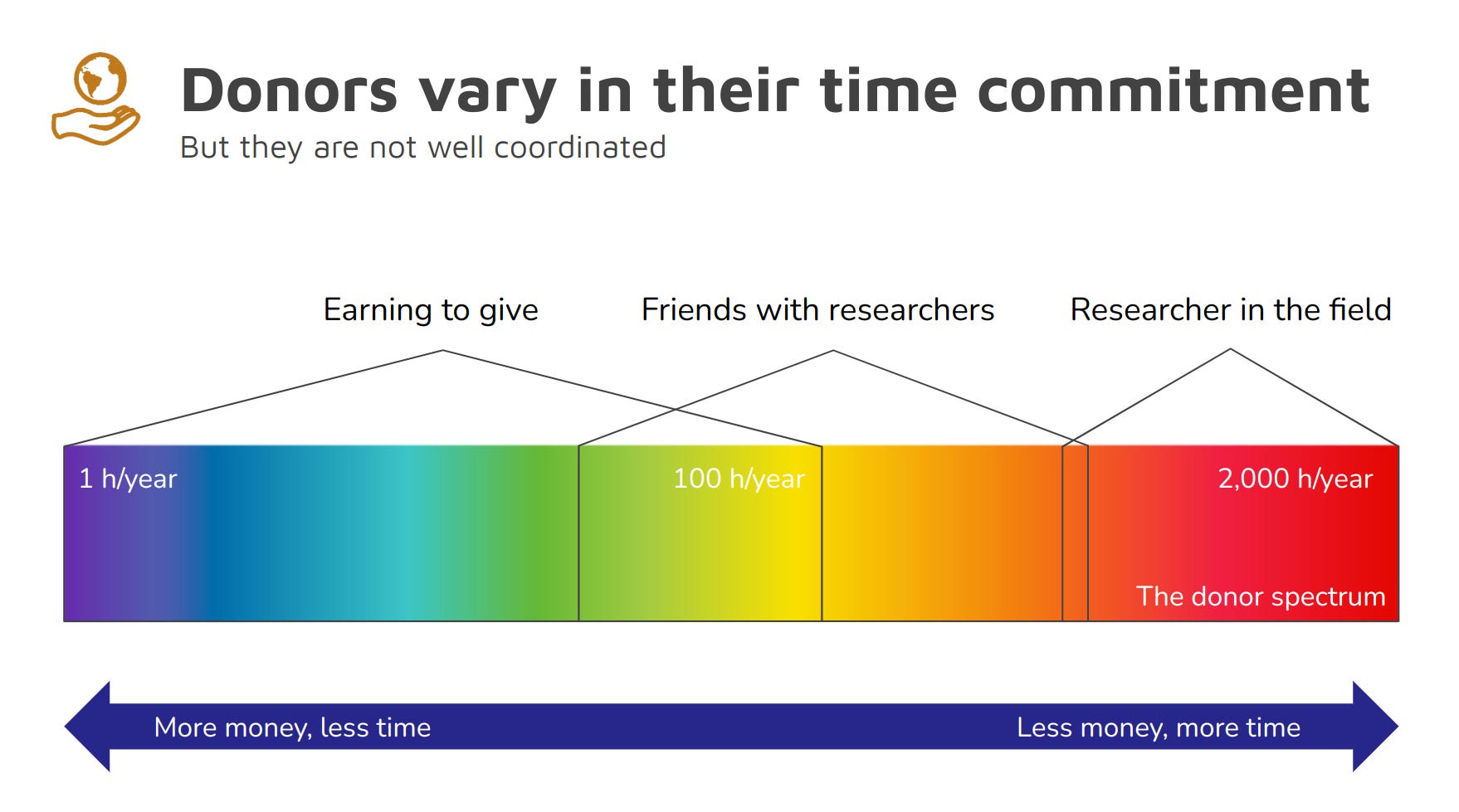
Donors need to be coordinated because they come in various different shapes and sizes. There are some who are in earning to give. They spend all of their time on their full-time jobs where they have little time left to research their donations. But of course, they earn a lot of money in these jobs. These donors are all the way over on the left, the blue side of the spectrum. They can only spend a few hours per year on donation research.
But there are some other donors who can spend easily like three orders of magnitude more time on research that is relevant to their donations because they don’t even have to individually research their donations. They are working in fields where they are all the time, in their full-time jobs, exposed to exactly the sort of knowledge that is valuable for allocating donations.
There are also donors in between who – even though they work full-time in jobs that have nothing to do with donation research – are friends with researchers or live in the same flat with researchers. So these donors also osmotically absorb some of the knowledge that’s valuable for making donations, be it just the knowledge that the particular researchers that they know can be trusted.
We would like to bridge the gap between these 1000x donors and the 1x donors. We want to make it possible for the blue donors who spend all their time earning to draw on all the knowledge of the donors all the way over on the red side of the spectrum.
Our Solution
Our system works the way that we score donors after the fact in terms of how early they were able to identify some successful project, how confidently they identified it (via the donation size), and the level of success of the project. This is a retrospective scoring, so a project has generated some impact and then we look back at who has supported the project early on and exactly how early they supported the project, and then score these donors in terms of these three factors.
That will cause smart donors to stand out in our ranking. So the smartest donors will be at the top of the ranking. At the moment it’s still pretty easy to break into those top spots, so I encourage you to try!
The top donors then continue to make their donations. Thanks to their track record we know to listen to them. So we can generate new, forward-looking donation recommendations that aggregate all of their wisdom.
For the top donors, conversely, the incentive is to leverage more donations for the projects that they think are the most impactful ones.
Here is a quick example of how the scoring works:
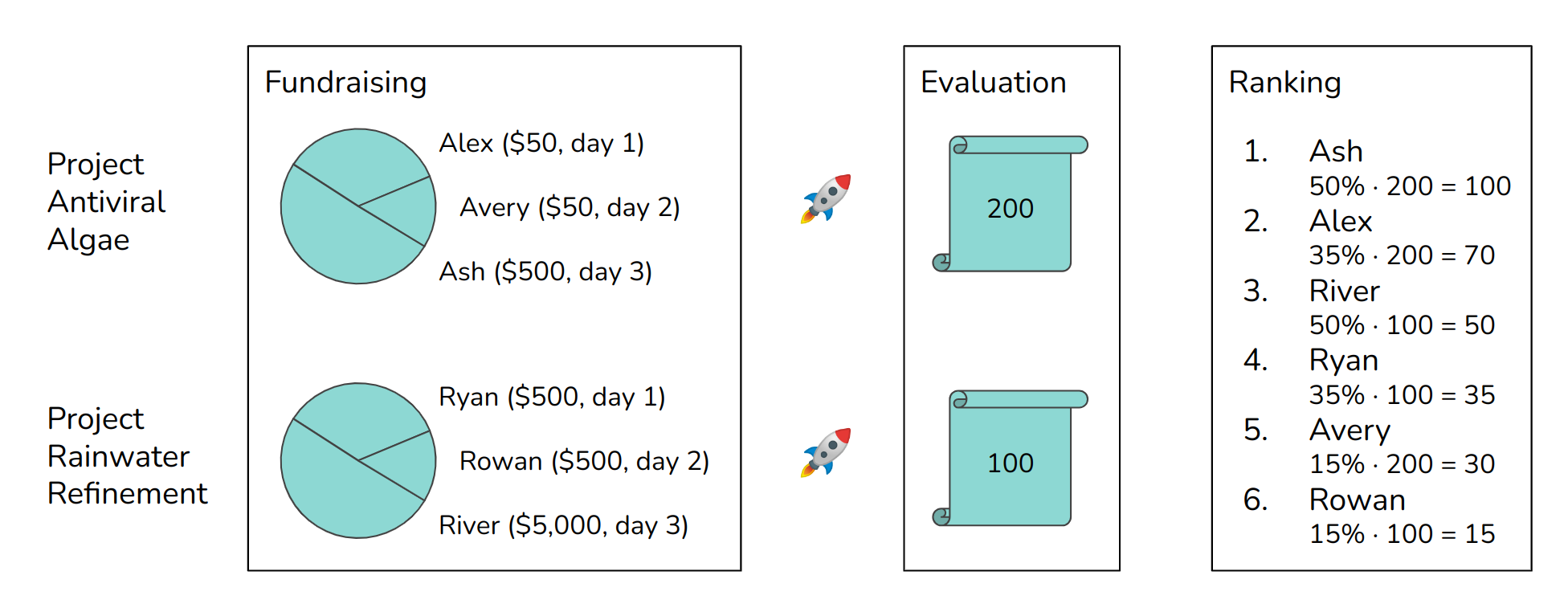
There are pictured here two projects, the project Antiviral Algae and the project Rainwater Refinement. These projects enter the fundraising phase and find three donors each.
Alex was first, donated on day one to the project Antiviral Algae; then Avery donated on day two; and then Ash donated on day three. Our algorithm scores Alex highly in this project because Alex donated very early, but it also scores Ash highly because Ash donated a lot.
Likewise, for the second project, Ryan and River score highly because they, respectively, donated early or a lot. In between is Rowan.
And then the projects get executed. They invest the donations that they’ve received into their respective programs.
Then the evaluation happens. Our evaluators decide that the first project should receive a score of 200 and the second project one of 100. This results in the ranking that you can see all the way over on the right.
Finally, Ash receives the highest rank, and Alex is second, because the first project has the highest score, and these two donors have made the biggest contribution – monetarily in Ash’s case and in terms of information value in Alex’s case.
There are no donors who’ve donated to two projects in this case. The scores from these two projects would get added up.
Our Roadmap
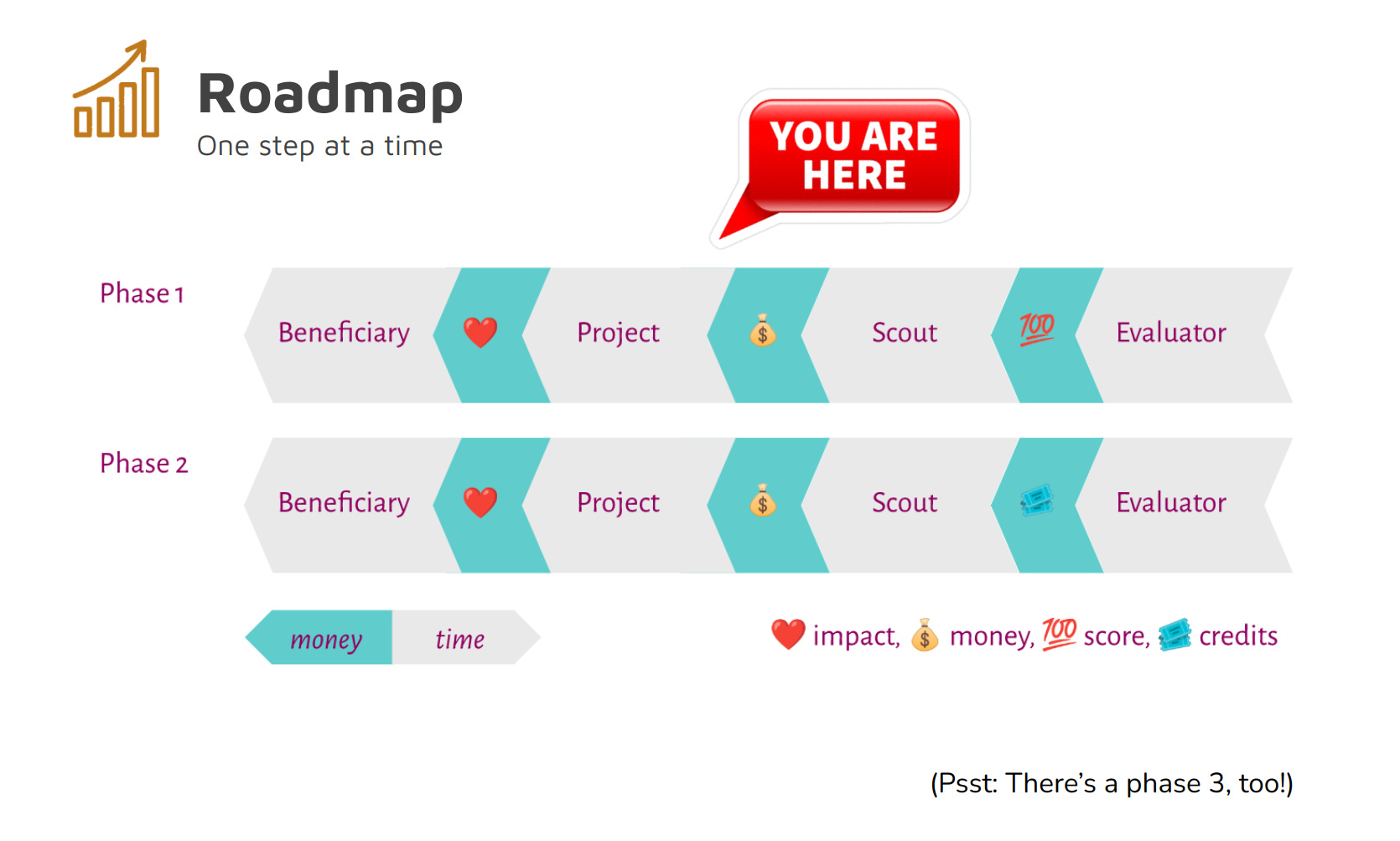
At the moment we are in something that we call phase one. We have 46 projects on our platform, and we’re looking for more project scouts who want to make the first donations to these projects or potentially bring more projects onto the platform that they have already donated to so that they can register their donations to these projects. (That just depends on whether the scouts think that the most impactful project is one that is on the platform already or one that they still have to convince to join the platform.)
Eventually, once a sufficient number of these projects have been successful and have produced something that can be evaluated (we call these things artifacts), said evaluation will happen and we’ll pay some evaluators to score the projects. That’s phase 1.
Once we have some 100+ monthly active users we want to introduce something that we call impact credits or impact marks. It’s a play-money currency that we want to use on our platform. We’ll have various uses for it but primarily, it can be used by the people with the highest donor scores on the platform to themselves act as evaluators to some extent.
There’s also a phase 3 that is in the distant future at this point. Hopefully, one day, we’ll figure out all the legal problems of trying to institute a new kind of commodity. Then, hopefully, we’ll be able to institute these impact credits in a way that will make it possible to trade them on a market against US dollars or against some other kind of currency.
Phase 3 is particularly interesting because at the moment the “investors” on the platform are donors who try to use all of their specialized knowledge to make great donations. But eventually, we want to also bring for-profit investors onto the platform, investors who will bring all of their knowledge about (say) angel investing and all the experience from the startup sector into the nonprofit sector. They would try to earn impact credits to then sell them on the market.
We’re modeling this market ecosystem after that of carbon credits. Large buyers like governments could have like limit buy orders on our impact exchanges in order to encourage seed investment into early-stage charity projects.
More on our long-term vision can be found in the article “The Retroactive Funding Landscape.”
Current Challenges

Project scouts. I already mentioned that at the moment we’re looking for project scouts. So if you have some insider knowledge of some area and feel able to make highly impactful donations in that area then you can now share that knowledge with other people and thereby also leverage the donations of people with less knowledge of that area.
They will follow your donations in order to make almost as impactful donations. At the moment you can also import your historical donations to the platform to get a higher donor score. If you have a lot of donations to import, you can ask me and I can do it for you.
At the moment, you’d be able to leverage some fraction of the $391,000 donation budget of the 38 donors who have expressed interest in using the platform.
Donors. We’re also looking for donors of course – donors who just want to use the platform to allocate their donations but don’t think that they have any special knowledge of which project should receive them. These donors can just check out our top recommendations or pick out particular top donors that they want to follow.
If that is you, it’s crucial to us that you register your interest, so that we can increase the incentive for project scouts.
Investments. Finally, we’re also a Delaware public benefit corporation. So if you’re an impact investor or an angel investor and would like to invest in our project then we’d love for you to get in touch.
Seems interesting and important.
I think it’s great that you’re working on this!
My thoughts are mostly critical—since I think you’re trying something extremely difficult.
But again, it’s great that you’re trying!
From what I can see the usefulness of this system will all hinge on the evaluation system.
To be clear, I don’t mean “it’s important that there’s a well-thought-through impact evaluation mechanism” (though it is). Rather “it’s far from clear we have the collective understanding to produce a fit-for-purpose impact evaluation system”.
The first thing I’d look for in a new funding mechanism is: “Is this likely to provide support for important research directions that current mechanisms don’t favour?”
I.e. is it usefully shaping the incentive landscape?
My expected answer for something like this is: “no” (without an evaluation system designed with this in mind)
Most current systems already incentivize the pursuit of incremental, reliably artifact-producing, legibly-plausibly-useful research. It’s not clear that building more roads to the same destinations helps. (please let me know if it seems that I’m misunderstanding the system)
In particular, [x did this nice thing we can easily measure] may often have the externality [x didn’t try this much more important higher variance thing], or [x didn’t do this nice thing it’s hard to measure].
Then there’s an [amplification of the field’s existing direction] issue—fine if the field is broadly doing the right thing already; otherwise not. (some mechanic to reward [those who’ve backed projects that cause other donors to update on seeing the results] might be worth a thought)
I don’t currently have great thoughts on ways to do better—though it’s something I hope to find time to think through more carefully.
However, if there’s one key consideration, I think it’s that:
[support projects for which there’s the best evidence of high (future) impact] and [incentivize researchers to pursue the projects with highest expected impact] do not imply the same approach. ([optimize for (early, reliable) evidence of impact] != [optimize for impact])
If we actually want the latter, we shouldn’t be creating multiple systems to do the former.
Awww, thanks for the input!
I actually have two responses to this, one from the perspective of the current situation – our system in phase 1, very few donors, very little money going around, most donors don’t know where to donate – and the final ecosystem that we want to see if phase 3 comes to fruition one day – lots of pretty reliable governmental and CSR funding, highly involved for-profit investors, etc.
The second is more interesting but also more speculative. The diagram here, shows both the verifier/auditor/evaluator and the standardization firms. I see the main responsibility with the standardization firms, and that’s also where I would like my company to position itself if we reach that stage (possibly including the verification part).
One precedent for that is the Impact Genome. It currently recognizes (by my latest count) 176 kinds of outcomes. They are pretty focused on things that I would class as deploying solutions in global development, but they’re already branching out into other fields as well. Extend that database with outcomes like different magnitudes of career plan changes (cf. 80,000 Hours), years of dietary change, new and valuable connections between collaborators, etc., and you’ll probably end up with a database of several hundred outcome measures, most of which are not just about publishing in journals. (In the same section I mention some other desiderata that diverge a bit from how the Impact Genome is currently used. That article is generally the more comprehensive and interesting one, but for some reason it got fewer upvotes.)
In this world there’s also enough financial incentive for project developers to decide what they want to do based on what is getting funded, so it’s important to set sensible incentives.
It’s possible that even in this world there’ll be highly impactful and important things to do that’ll somehow slip through the cracks. Absent cultural norms around how to attribute the effects of some more obscure kind of action, it might lead to too many court battles to even attempt to monetize it. I’m thinking of tricky cases that are all about leveraging the actions of others, e.g., when doing vegan outreach work. Currently there are no standards for how to attribute such work (how much reward should the leaflet designer get, how much should the activist get, how much should the new vegan or reducitarian get). But over time more and more of those will probably get solved as people agree on arbitrary assignments. (Court battles cost a lot of money, and new vegans will not want to financially harm the people who first convinced them to go vegan, so the activist and the leaflet designer are probably in good positions to monetize their contributions, and just have to talk to each other how to split the spoils.)
But we’re so so far away from that world.
In the current world I see three reasons for our current approach:
It’s basically on par with how evaluations are done already while making them more scalable.
The counterfactual to getting funded through a system like ours is usually dropping out of AI safety work, not doing something better within AI safety.
If we’re successful with our system, project developers will much sooner do small, cheap tweaks to make their projects more legible, not change them fundamentally.
First, my rough impression from the projects on our platform that I know better is that for them it’s mostly that they’re, by default, not getting any funding or just some barely sufficient baseline funding from their loyal donors. With Impact Markets, they might get a bit of money on top. The loyal donors are probably usually individuals with personal ties to the founders. The funding that they can get on top is thanks to their published YouTube videos, blog articles, conference talks, etc. So one funding source is thanks to friendships; the other is thanks to legible performance. But there’s no funding from some large donor who is systematically smarter and more well-connected than our evaluators + project scout network.
And even really smart funders like Open Phil will look at legible things like the track record of a project developer when making their grant recommendations. If the project developer has an excellent track record of mentioning just the right people and topics to others at conferences, then no one, not Open Phil or even the person themselves will be able to take that into account because of how illegible it is.
Second, we’re probably embedded in different circles (I’m guessing you’re more thinking of academic researchers at university departments where they can do AI safety research?), but in my AI safety circles there are the people who have savings from their previous jobs that they’re burning through, maybe some with small LTFF grants, and some that support each other financially or with housing. So by and large it’s either they get a bit of extra money through Impact Markets and can continue their work for another quarter or they drop out of AI safety work and go back to their industry jobs. So even if we had enough funding for them, it would just prevent them from going back to unrelated work for a bit longer, not change what they’re doing within AI safety.
A bit surprisingly, maybe, one of our biggest donors on the platform is explicitly using it to look for projects that push for a pause or moratorium on AGI development, largely though public outreach. That can be checked by evaluators through newspaper reports on the protests, and other photos and videos, but it’ll be unusually opaque how many people they reached, whether any of them were relevant, and what they took away from it. So far our track record seems to be to foster rather illegible activism rather than distract from it, though admittedly that has happened a bit randomly – Greg is just really interested in innovative funding methods.
Third, currently the incentives are barely enough to convince project developers to spend 5 minutes to post their existing proposals to our platform, and only in some cases. (In others I’ve posted the projects for them and then reassigned them to their accounts.) They are not enough to cause project developers to make sure that they have the participants’ permission to publish (or share with external evaluators) the recordings of their talks. They’re not enough for them to design feedback surveys that shed light on how useful an event was to the participants. (Unless they already have them for other reasons.)
And it makes some sense too: We’ve tracked $391,000 in potential donations from people who want to use our platform; maybe 10% of those will follow through; divide that by the number of projects (50ish), and the average project can hope for < $1,000. (Our top projects can perhaps hope for $10k+ while the tail projects can probably not expect to fundraise anything, but the probability distribution math is too complicated for me right now. Some project developers might expect a Pareto distribution where they’d have to get among the top 3 or so for it to matter at all; others might expect more of a log-normal distribution.) Maybe they’re even more pessimistic than I am in their assumptions, so I can see that any change that would require a few hours of work does not seem worth it to them at the moment.
If we become a bit more successful in building momentum behind our platform, maybe we can attract 100+ donors with > $1 million in total funding, so that we can present a stronger incentive for project developers. But even then I think what would happen is rather that they’ll do such things as design feedback surveys to share with evaluators or record unconference talks to share them etc., but not to fundamentally change what they’re doing to make it more provable.
So I think if we scale up by 3–4 orders of magnitude, we’ll probably still do a bit better with our system than existing funders (in terms of scaling down, while having similarly good evaluations), but then we’ll need to be careful to get various edge cases right. Though even then I don’t think mistakes will be path dependent. If there is too little funding for some kind of valuable work, and the standardization firms find out about it, they can design new standards for those niches.
I hope that makes sense to you (and also lunatic_at_large), but please let me know if you disagree with any of the assumptions and conclusion. I see for example that even now, post-FTX, people are still talking about a talent constraint (rather than funding constraint) in AI safety, which I don’t see at all. But maybe the situation is different in the US, and we should rebrand to impactmarkets.eu or something! xD
Thanks for the lengthy response.
Pre-emptive apologies for my too-lengthy response; I tried to condense it a little, but gave up!
Some thoughts:
First, since it may help suggest where I’m coming from:
Certainly to some extent, but much less than you’re imagining—I’m an initially self-funded AIS researcher who got a couple of LTFF research grants and has since been working with MATS. Most of those coming through MATS have short runways and uncertain future support for their research (quite a few are on PhD programs, but rarely AIS PhDs).
Second, I get the impression that you think I’m saying [please don’t do this] rather than [please do this well]. My main point throughout is that the lack of reliable feedback makes things fundamentally different, and that we shouldn’t expect [great mechanism in a context with good feedback] to look the same as [great mechanism in a context without good feedback].
To be clear, when I say “lack of reliable feedback”, I mean relative to what would be necessary—not relative to the best anyone can currently do. Paul Christiano’s carefully analyzing each project proposal (or outcome) for two weeks wouldn’t be “reliable feedback” in the sense I mean.
I should clarify that I’m talking only about technical AIS research when it comes to inadequacy of feedback. For e.g. projects to increase the chance of an AI pause/moratorium, I’m much less pessimistic: I’d characterize these as [very messy, but within a context that’s fairly well understood]. I’d expect the right market mechanisms to do decently well at creating incentives here, and for our evaluations to be reasonably calibrated in their inaccuracy (or at least to correct in that direction over time).
Third, my concerns become much more significant as things scale—but such scenarios are where you’ll get almost all of your expected impact (whether positive or negative). As long as things stay small, you’re only risking missing the opportunity to do better, rather than e.g. substantially reducing the odds that superior systems are produced.
I’d be surprised if this kind of system is not net positive while small.
In much of the below, I’m assuming that things have scaled up quite a bit (or it’s likely no big deal).
On the longer-term, speculative aims:
My worry isn’t around obscure actions/outcomes that slip through the cracks. It’s around what I consider a central and necessary action: doing novel, non-obvious research, that gets us meaningfully closer to an alignment solution.
My claim is that we have no reliable way to identify or measure this. Further, the impact of most other plausibly useful outcomes hinges on whether they help with this—i.e. whether they increase the chance that [thing we can’t reliably measure progress towards] is produced.
So, for example, a program that successfully onboards and accelerates many new AIS researchers in
I think it’s more reasonable in an AI safety context to talk about outcomes than about impact: we can measure many different types of outcome. The honest answer to whether something has had net positive impact is likely to remain “we have no idea” for a long time.
With good feedback it’s very reasonable to think that [well constructed market mechanism] will do a good job at solving some problem. Without good feedback, there’s no reason to expect this to work. There’s a reason to think it’ll appear to be working—but that’s because we’ll be measuring our guesses against our guesses, and finding that we tend to agree with ourselves.
The retrospective element helps a little with this—but we’re still comparing [our guess with very little understanding] against [our guess with very little understanding and a little more information].
There are areas where it helps a lot—but those are the easy-to-make-legible areas I don’t worry about (much!).
It seems very important to consider how such a system might update and self-correct.
On the more immediate stuff:
This is a good reason only if you think [scaled existing approach] is a good approach. Evaluations that are [the best we can do according to our current understanding] should not be confused with evaluations that are fairly accurate in an objective sense.
The best evaluations for technical AIS work currently suck. I think it’s important to design a system with that in mind (and to progressively aim for them to suck less, of course)
I think what’s important here is [system we’re considering] vs [counterfactual system (with similar cost etc)]. So the question isn’t whether someone getting funded through this system would drop out if there were no system—rather it’s whether there’s some other system that’s likely to get more people doing something more valuable within AI safety.
First, I don’t think it’s reasonable to assume that there exist “small, cheap tweaks” to make the most important neglected projects legible. The projects I’d consider most important are hard to make legibly useful—this is tied in a fundamental way to their importance: they’re (attempting) a non-obvious leap beyond what’s currently understood.
Second, the best systems will change the incentive landscape so that the kind of projects pursued are fundamentally changed. Unless we think that all the most important directions are already being pursued, it’s hugely important to improve the process by which ideas get created and selected.
Another point that confuses me:
I expect there is hugely valuable work no-one is doing, and we don’t know what it is (and it’s unlikely some meta-project changes this picture much). In such a context, we need systems that make it more likely such work happens even without any ability to identify it upfront, or quickly notice its importance once it’s completed.
I’m not hugely worried about there being inadequate funding for concrete things that are noticeably neglected.
I think this depends a lot on one’s model of AI safety progress.
For instance, if we expect that we’ll make good progress by taking a load of fairly smart ML people and throwing them at plausibly helpful AIS projects, we seem funding constrained.
If most progress depends on researchers on Paul/Eliezer’s level, then we seem talent constrained. (here I don’t mean researchers capable of iterating on directions Paul/Eliezer have discovered, but rather those who’re capable of coming up with promising new ones themselves)
Of course it’s not so simple—both since things aren’t one-dimensional, and because there’s a question as to how effectively funding can develop the kind of talent that’s necessary (this seems hard to me).
I also think it depends on one’s high-level view of our current situation—in particular of the things we don’t yet understand, and therefore cannot concretely see. I think there’s a natural tendency to focus on the things we can see—and there there’s a lot of opportunity to do incremental work (funding constraint!).
However, if we instead believe that there are necessary elements of a solution that require identification and deconfusion before we can even find the right language to formulate questions, it’s quite possible that everything we can see is insufficient (talent constraint!).
Generally, I expect that we’re both funding and talent constrained.
I expect that a significant improvement to the funding side of things could be very important.
Oh, haha! I’ll try to be more concise!
Possible crux: I think I put a stronger emphasis on attribution of impact in my previous comment than you do because to me that seems like both a bit of a problem and solveable in most cases. When it comes to impact measurement, I’m actually (I think) much more pessimistic than you seem to be. There’s a risk that EV is just completely undefined even in principle and even if that should turn out to be false or we can use something like stochastic dominance instead to make decisions, that still leaves us with a near-impossible probabilistic modeling task.
If the second is the case, then we can probably improve the situation a bit with projects like the Squiggle ecosystem and prediction markets but it’ll take time (which we may not have) and will be a small improvement. (An approximate comparison might be that I think that we can still do somewhat better than GiveWell, especially by not bottoming out at bad proxies like DALYs or handling uncertainty more rigorously with Squiggle, and that we can go as well as that in more areas. But not much more, probably.)
Conversely, even if we have roughly the same idea how much the passing of time helps in forecasting things, I’m more optimistic about it, relatively speaking.
Might that be a possible crux? Otherwise I feel like we agree on most things, like desiderata, current bottlenecks, and such.
Argh, yeah. We’re following the example of carbon credits in many respects, and there there are some completely unnecessary issues whose impact market equivalents we need to prevent. It’s too early to think about this now, but when the time comes, we should definitely talk to insiders of the space who have ideas in how it should be changed (but probably can’t anymore) to prevent the bad incentives that have probably caused that.
Another theme in our conversation, I think, is figuring out exactly what or how much the final system should do. Of course there are tons of important problems that need to be solved urgently, but if one system tries to solve all of them, they sometimes trade off against each other. Especially for small startups it can be better to focus on one problem and solve it well rather than solve a whole host of problem a little bit each.
I think at Impact Markets we have this intuition that experienced AI safety researchers are smarter than most other people when it comes to prioritizing AI safety work, so that we shouldn’t try to steer incentives in some direction or other and instead double down on getting them funded. That gets harder once we have problems with fraud and whatnot, but when it comes to our core values, I think we are closer to, “We think you’re probably doing a good job and we want to help you,” rather than “You’re a bunch of raw talent that wants to be herded and molded.” Such things as banning scammers is then an unfortunate deviation from our core mission that we have to accept. That could change – but that’s my current feeling on our positioning.
Nothing revolutionary, but this could become a bit easier. When Michael Aird started posting on the EA Forum, I and others probably figured, “Huh, why didn’t I think of doing that?” And then, “Wow, this fellow is great at identifying important, neglected work they can just do!” With a liquid impact market, Michael’s work would receive its first investments at this stage, which would create additional credible visibility on the marketplaces, which could cascade into more and more investments. We’re replicating that system with our score at the moment. Michael could build legible track record more quickly through the reputational injections from others, and then he could use that to fundraise for stuff that no one understands, yet.
Yeah, also how to even test what the talent constraint is when the funding constraint screens it off. When the funding was flowing better (because part of it was stolen from FTX customers…), has AI safety progress sped up? Do you or others have intuitions on that?
I also suspect that the evaluation mechanism is going to be very important. I can think of philosophical debates whose resolution could change the impact of an “artifact” by many orders of magnitude. If possible I think it could be good to have several different metrics (corresponding to different objective functions) by which to grade these artifacts. That way you can give donors different scores depending on which metrics you want to look at. For example, you might want different scores for x-risk minimization, s-risk minimization, etc. That still leaves the “[optimize for (early, reliable) evidence of impact] != [optimize for impact]” issue open, of course.