Encultured AI Pre-planning, Part 1: Enabling New Benchmarks
Also available on the EA Forum.
Followed by: Encultured AI, Part 2 (forthcoming)
Hi! In case you’re new to Encultured AI, we’re a for-profit start-up with a public benefit mission: developing technologies promoting the long-term survival and flourishing of humanity and other sentient life. However, we also realize that AI poses an existential risk to humanity if not developed with adequate safety precautions. Given this, our goal is to develop products and services that help humanity steer toward the benefits and away from the risks of advanced AI systems. Per the “Principles” section of our homepage:
Our current main strategy involves building a platform usable for AI safety and alignment experiments, comprising a suite of environments, tasks, and tools for building more environments and tasks. The platform itself will be an interface to a number of consumer-facing products, so our researchers and collaborators will have back-end access to services with real-world users. Over the next decade or so, we expect an increasing number of researchers — both inside and outside our company — will transition to developing safety and alignment solutions for AI technology, and through our platform and products, we’re aiming to provide them with a rich and interesting testbed for increasingly challenging experiments and benchmarks.
In the following, we’ll describe the AI existential safety context that motivated us to found Encultured, and go into more detail about what we’re planning to do.
What’s trending in AI x-safety?
The technical areas below have begun to receive what we call “existential attention” from AI researchers, i.e., attention from professional AI researchers thinking explicitly about the impact of their work on existential safety:
Trustworthiness & truthfulness — ensuring AI systems are telling us the truth and doing the things they and their creators say they’re going to do.
Preference learning — enabling AI systems to learn what humans want.
Interpretability — enabling humans to understand what AI systems are thinking and doing.
Robustness & risk management — ensuring AI systems continue functioning well in novel situations, and quantifying the risk that they won’t.
In other words, the topics above lie in the intersection of the following Venn diagram:
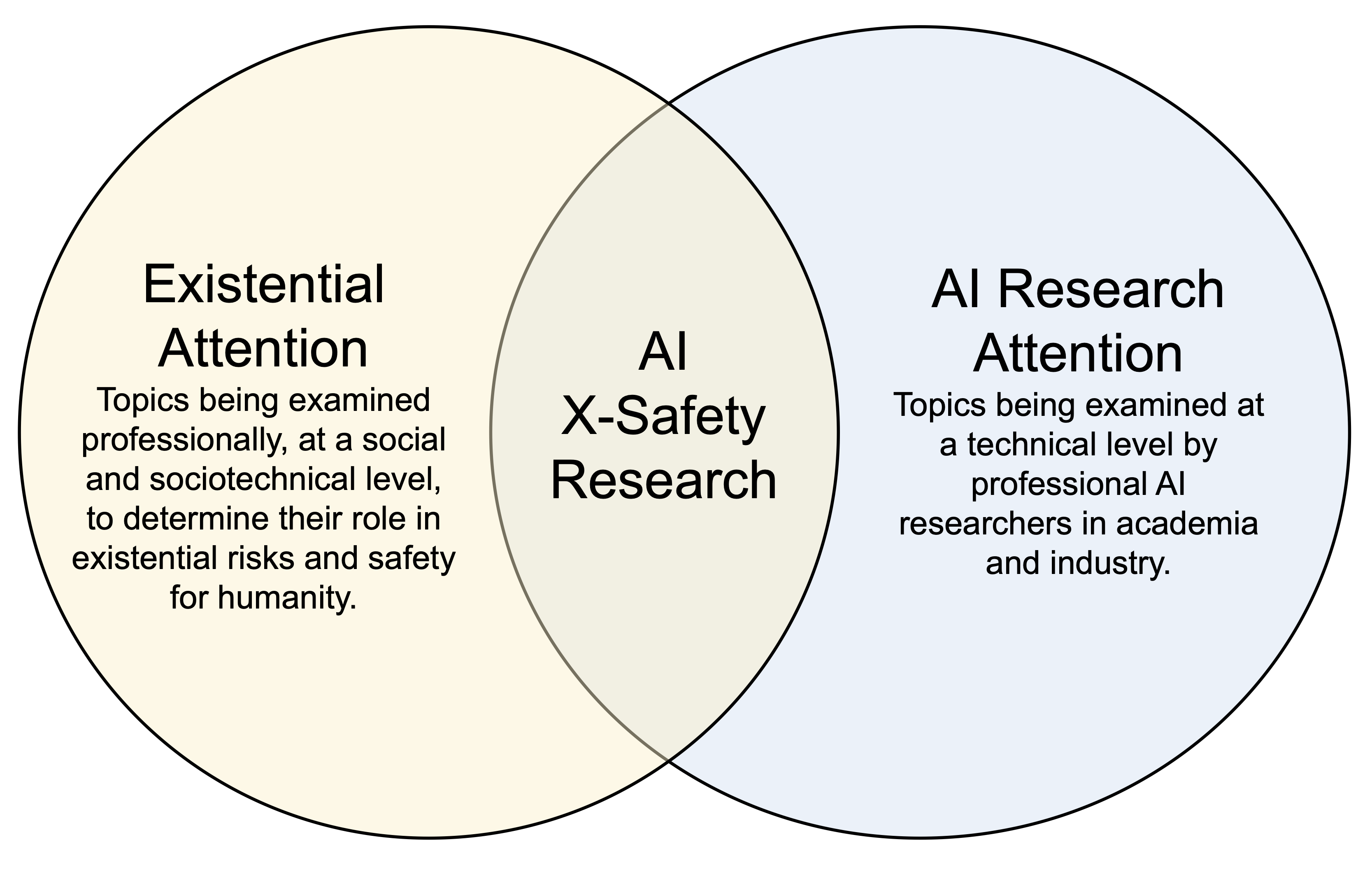
See Appendix 1 for examples of research in these areas. More research in these areas is definitely warranted. A world where 20%+ of AI and ML researchers worldwide pivoted to focusing on the topics above would be a better world, in our opinion.
If our product is successful, we plan to grant access to researchers inside and outside our company for performing experiments in the areas above, interacting directly with users on our platform. And, our users will be aware of this ;) We’re planning on this not only because it will benefit the world, but because it will benefit our products directly: the most valuable tools and services are trustworthy, truthful, preference-sensitive, interpretable, and robust.
What’s emerging in AI x-safety?
The following topics have received research attention from some researchers focused on existential safety, and AI research attention from other researchers, but to us the two groups don’t (yet) seem to overlap as much as for the ‘trending’ topics above.
Cooperative AI — designing AI technologies in ways that enable improved cooperation between humans and AI systems, while preventing collusion between AI systems, i.e., cooperation between AI systems that would be harmful or deceptive to humanity. (see Appendix 2 for related research.)
Multi-stakeholder control of AI systems — allowing people with diverse values, such as from competing geopolitical factions, to share control of a single AI system. (see Appendix 2 for related research.)
Also see Appendix 2 for a breakdown of why we think these areas are “emerging” in AI x-safety.
What’s missing?
While continuing to advocate for the above, we’ve asked ourselves: what seems to be completely missing from research and discourse on AI existential safety? The following areas are topics that have been examined from various perspectives in AI research, but little or not at all from the perspective of x-safety:
Life-aligned helpers: Real-world living creatures, including humans, have numerous properties that distinguish them from abstract agents that are not embedded in the physical world. As such, it’s useful to experiment with AI systems assisting and caretaking for entities with some of the properties listed below.
Soft embodiment — Humans are soft-bodied creatures! Robotics research in prosthetics, teleoperation, and surgery are the closest areas of AI research that address this aspect of human need, but research in these areas don’t usually consider their implications for x-safety.
Multi-scale health — Humans can have health problems with their cells and organs, but can also have problems with mental health, unhealthy relationships, unhealthy communities, and even unhealthy geopolitical dynamics. We believe it is not a coincidence or mere metaphor that the concept of “health” is applied at all of these scales, and we want to enable benchmarks that test the ability to help people and living systems (e.g. communities) at multiple scales simultaneously.
Research in AI ethics and fairness can be viewed as addressing “health problems” at the scale of society, but these topics aren’t frequently examined from the perspective of x-safety.
Boundaries — Humans and all natural living creatures maintain physical boundaries, such as cell membranes, skin, shelters (homes, offices), physical territories (e.g. private land, states), and even cognitive boundaries (e.g., accepted versus taboo topics). These boundaries may be treated as constraints, but they are more specific than that: they delineate regions or features of the world in which the functioning of a living system occurs. We believe many attempts to mollify the negative impacts of AI technology in terms of “minimizing side effects” or “avoiding over-optimizing” can often be more specifically operationalized as respecting boundaries. Moreover, we believe there are abstract principles for respecting boundaries that are not unique to humans, and that are simple enough to be transferable across species and scales of organization. The following sources of information:
Prof. Michael Levin’s research on organismal pattern homeostasis shows how some kinds of cancer — i.e., misaligned cellular behavior — can be caused and prevented through the closing and opening of intercellular gap junctions (video presentation). These effects persist in both absence and the presence of oncogenes. In other words, by stimulating the opening and closing of cellular gap junctions, but without changing the genomes of the cells, we can cause genetically cancerous cells to revert to healthy (non-cancerous) behavior, and cause healthy cells to form cancerous tumors. This means the mechanism of cancer is closely mediated by how cells manage their boundaries.
The late Prof. Jaak Panksepp wrote an excellent textbook, Affective Neuroscience: the Foundations of Human and Animal Emotions (amazon), explaining how many aspects of mammalian emotions are shared across species, and rooted in shared neurological structures. Panksepp’s work is too much to summarize here, but Nick and I both found the book very compelling, and Nick’s paper with Dr. Gopal Sarma, “Mammalian Value Systems” (arxiv, 2016), argues that Panksepp’s insights should inform value alignment for AI. In particular, we now believe certain important aspects of human values are simple enough to be genetically encoded and shared across species, and among those values are emotional heuristics for managing boundaries between individuals, including nurturance, lust, playfulness, fear, anger, and separation anxiety.
Humans can learn to navigate the social boundaries of other species such as lions (video) and bees (video). These individual successes have not been subject to academic study, so we cite them as illustrations of the patterns of cooperative boundary-management we believe are possible, rather than as strong sources of independent evidence.
Other complexities and imperfections — Living systems subsystems are often suboptimal, and thus not easily described as “the optimal solution to X” for any simple optimization problem X. It’s important for AI systems to be able to assist and care for such systems, because we are such systems!
Culturally-grounded AI: A core difference between humans and other animals is our reliance on an exceptionally vast culture. This pervades all aspects of our behavior. As a central example, most animals communicate in a species-universal way (e.g., cats around the world use roughly the same kinds of body language), but humans communicate primarily through a wide variety of mutually unintelligible languages and movements acquired during long-term real-world interactions with existing language users.
Cultural acquisition is a large part of how humans align with one another’s values, especially during childhood but also continuing into adulthood. We believe attention to culture and the process of cultural acquisition is important in AI value alignment for several reasons:AI systems should be tested in simulations of simplified human-like cultures, rather than only in simulations of autonomous agents.
AI systems attempting to serve human values would do well to model humans as engaging in a great deal of cultural acquisition amongst ourselves.
AI could in principle be designed to acquire human culture in a manner similar to how humans acquire it.
AI developers and AI systems should be cognizant of the potential to change human culture through interaction, so as to avoid triggering undesirable value drift.
To make sure these aspects of safety can be addressed on our platform, we decided to start by working on a physics engine for high-bandwidth interactions between artificial agents and humans in a virtual environment.
Recap
We think we can create opportunities for humanity to safety-test future systems, by building a platform usable for testing opportunities. We’re looking to enable testing for both popular and neglected safety issues, and we think we can make a platform that brings them all together.
In our next post, we’ll talk about how and why we decided to provide a consumer-facing product as part of our platform.
Followed By:
Encultured AI, Part 1 Appendix: Relevant Research Examples
Encultured AI Pre-planning, Part 2: Providing a Service
- Encultured AI Pre-planning, Part 2: Providing a Service by (Aug 11, 2022, 8:11 PM; 33 points)
- The Human-AI Reflective Equilibrium by (Jan 24, 2023, 1:32 AM; 22 points)
- Encultured AI, Part 1: Enabling New Benchmarks by (EA Forum; Aug 8, 2022, 10:49 PM; 17 points)
- 's comment on My understanding of Anthropic strategy by (Feb 16, 2023, 3:06 AM; 16 points)
- Encultured AI, Part 1 Appendix: Relevant Research Examples by (Aug 8, 2022, 10:44 PM; 11 points)
- Encultured AI, Part 2: Providing a Service by (EA Forum; Aug 11, 2022, 8:13 PM; 10 points)
- 's comment on (My understanding of) What Everyone in Technical Alignment is Doing and Why by (Aug 29, 2022, 9:42 AM; 9 points)
First, great news on founding an alignment organization on your own. While I give this work a low chance of making progress, if you succeed the benefits would be vast.
I’ll pre-register a prediction. You will fail with 90% probability, but potentially usefully fail. My reasons are as follows:
Inner alignment issues have a good chance of wrecking your plans. Specifically there are issues like instrumental convergence causing deception and power-seeking by default. I notice an implicit assumption where inner alignment is either not a problem or so easy to solve by default that it’s not worth worrying about. This may hold, but I suspect more likely than not not to hold.
I suspect that cultural AI is only relevant in the below human and human regime, and once above the human regime happens, there’s a fairly massive incentives to simply not care about humans culture the same way way that humans don’t really care about the less powerful animals. Actually bettering less powerful being’s lives is very hard.
> First, great news on founding an alignment organization on your own.
Actually I founded it with my cofounder, Nick Hay!
https://www.encultured.ai/#team