Sideloading: creating a model of a person via LLM with very large prompt
TLDR. We can create a relatively good model of a person by prompting a long-context LLM with a list of facts about this person. We can get much better results by iteratively improving the prompt based on the person’s feedback. Sideloading is the only technology for immortality that actually works as of 2024.
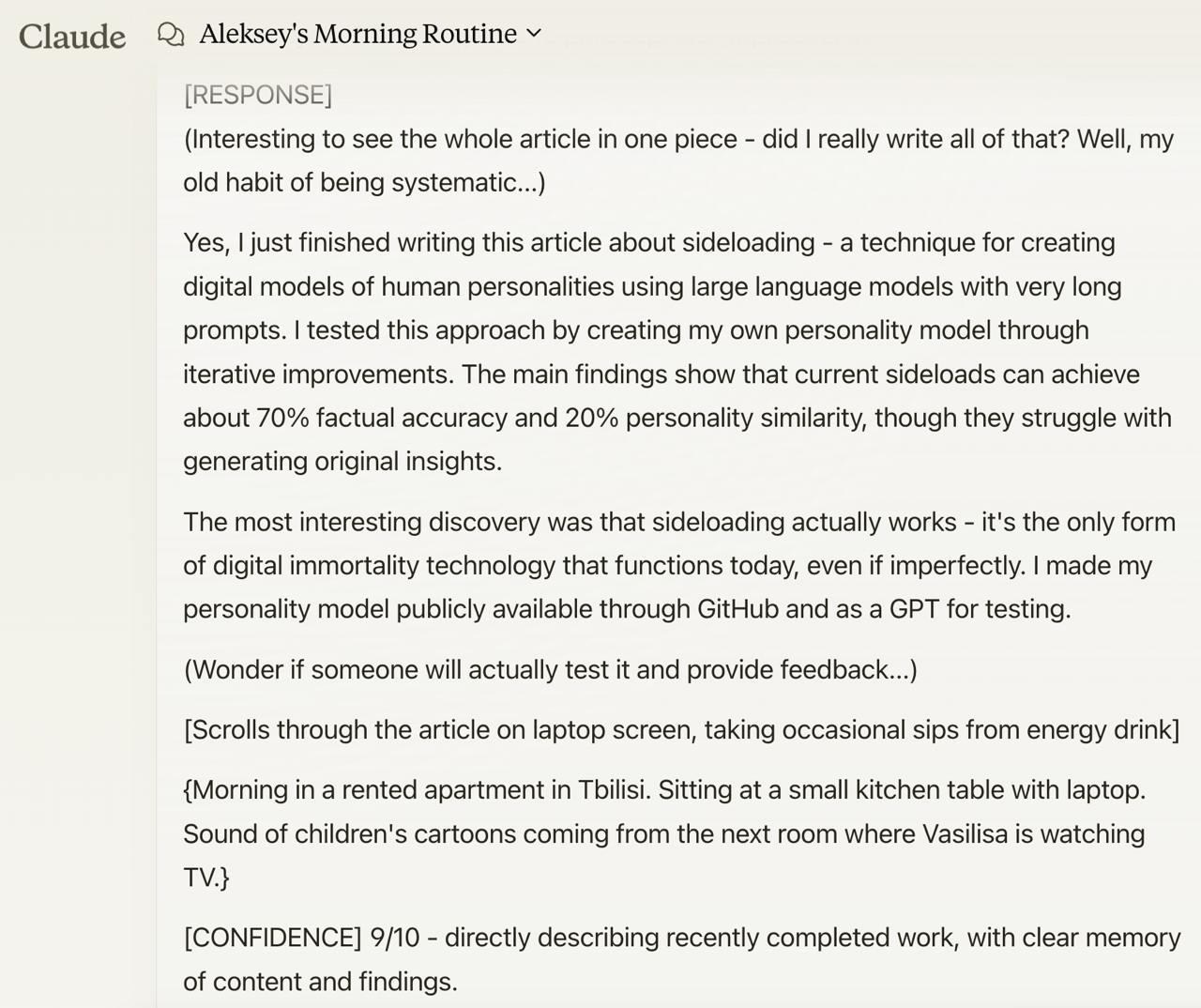
Fig. 1. Here are my sideload’s comments on the draft of this article
Summary
Sideloading is the creation of a digital model of a person during their life via iterative improvements of this model based on the person’s feedback. The progress of LLMs with large prompts allows the creation of very large, book-size prompts which describe a personality. We will call mind-models created via sideloading “sideloads”; they often look like chatbots, but they are more than that as they have other output channels, like internal thought streams and descriptions of actions.
By arranging the predictive power of the facts about a person, we can write down the most important facts first. This allows us to get a high level of fidelity in a person’s model by writing down a finite number of facts and running it as an LLM prompt with instructions to create a person’s chatbot. This instruction also includes an extensive general sideload prompt (we will call it a prompt-loader), which explains how the person’s sideload should work, but it is universal and works as an operating system for different persons.
I created my personal sideload to test all this and it started working surprisingly quickly.
We found that there are three main levels of facts about a person: core facts, long-term memory, and historical facts. Core facts should go to the main prompt of the LLM, long-term memory belongs to RAG, and historical facts – which a person often does not remember – should be only used to extract new relevant data. The most important thing in preparing data for sideloading is to get a full list of the core facts, and not to mix it with long-term memory and historical facts.
The LLM-sideload project is inherently future-oriented. New state-of-the-art LLMs with large prompt capabilities emerge quarterly. This allows for the preparation of prompts that exceed current LLM capabilities, anticipating smooth execution in the following year.
Below we present the key findings of this work in the form of an executive summary:
Quality of sideloads is evaluated using three metrics:
Facts: Accuracy of the answers about the person’s life
Vibe: How well the sideload captures the person’s style and personality, as judged by the person themselves and their acquaintances
Brilliant insights: Ability to contribute unique, valuable ideas beyond the training data, while maintaining the author’s style
Coarseness: Levels of details as percent of the total of recordable textual information from memory estimated to be 10000 pages. Similar to the jpeg level of compression.
Estimated performance of Alexey Turchin’s sideload:
Facts: 70% correct
Vibe: 20% accurate
Brilliant insights: near zero
Coarseness: 10%
The project achieved these results in about one month of work. Vibe is harder to evaluate and regulate than facts. This approach focuses on informational personal identity, setting aside issues of observer identity and internal qualia.
Improvement methods for sideloads include:
Iterative prompt updates based on feedback
Manual definition of vibe rules
Using LLMs to learn and refine vibe rules based on real-life communication chat logs
As of fall 2024, LLM-sideloads face several limitations:
Prompt size constraints
Limited availability of personal facts
Base LLM’s knowledge and intelligence limitations
Pros of sideloading for personal immortality:
Currently available, cost-effective, and rapidly improving
Enables long-term storage and multiple copies
Functions as personal assistant and memory aid
Offers potential applications in AI safety and cryonics
Does not require superintelligence for creation
Provides human-readable and customizable format
Allows privacy control over included information
Cons of sideloading:
Lacks true consciousness/qualia (presumably)
Missing personal details and neural-level information
Challenges in creating high-quality versions
Risk of errors or unrealistic behavior
Ethical concerns (suffering potential, deactivation ethics)
Dependence on corporate-owned LLMs and cloud services
Privacy risks and potential data leaks
Possible influence on original person’s behavior
Knowledge limited to creation date
Emotional and uncanny valley effects on users
Legal and social implications (consent, ownership, misuse)
A sideload represents a distinct state of being – it is neither a copy, an upload, a chatbot, nor digital immortality.
I have made my personality model publicly available through two channels:
GitHub Repository:
https://github.com/avturchin/minduploading/
(Contains the personality data and prompt-loader versions)Interactive Sideload:
https://chatgpt.com/g/g-EeFIesHsn-alexey-turchin-v7
(Allows direct testing of the sideload implementation)Permanent address of the article (this blogpost is its shorter version) https://philpapers.org/rec/TURSCA-3
1.Introduction. Theory of sideloading
What is sideloading
Sideloading was suggested by Greg Igen in his novel Zendegi (Egan, 2011), where the protagonist wants to create a model of his own personality to help his son in life after protagonist’s expected death. He created such a model, but there appeared the problem of verification. He tests the model inside a computer game and makes small adjustments of the model until it becomes indistinguishable from the original. The whole process was called sideloading.
Earlier works of fiction also depicted similar concepts, including Games in a hall where no one is present (Gorbovsky, 1979)[1], Red Limit Freeway (DeChancie, 1984)[2], Transhuman Space[3] (Pulver, 2003).
Sideloading is different from two similar ideas: uploading and digital reconstruction based on traces:
1. Uploading requires some form of physical connection between the brain and computer, which allows scanning the exact connectome and synaptic weights in the brain (and more if needed). It can be performed via neuroimplants, nanorobots or tomography. Uploading can be done during life or postmortem. The role of the subject here is passive: he is just being uploaded. Uploading is currently only being done for nematodes and flies (Cheshire JR, 2015; Hanson, 2016; Rothblatt, 2012; Wiley, 2014).
2. Reconstruction based on traces assumes the existence of future superintelligence which observes all information about a person and solves a reverse task: computes the mind structure of the person based on his outputs. A person may play an active role here via preserving as much data about oneself as possible as well as preserving most predictive data first (Almond, 2003; Turchin, 2018).
Sideloading doesn’t require neither physical connection with the brain nor superintelligence. Instead, it uses available low-tech methods for personality modeling, but it requires active personal participation in producing predictive data and validating the model. Note that the first two methods do not assume validating as the main driver of quality.
Theoretically, all approaches must converge in the behaviorally similar mind-model.
The main difficulty in sideloading until recently was that we didn’t know how to approach even low-tech mind modelling (except hard-coded chatbots like Elisa). It all changed with advent of LLMs.
There is a closely related approach in mainstream machine learning research called imitation learning (related terms: behavioral cloning, inverse reinforcement learning, apprenticeship learning).
Fig. 2. Example of a typical (first attempt, not cherry-picked) conversation with my sideload. It demonstrates the internal machinery of the sideload-AI: Chain of Thought, collection of facts, and selection of the most important fact. The response includes (thought stream), answer, [behavior] and {surroundings} streams. The figure also shows components of AI-sideload machinery including the confidence block and memory block. The final question represents a hallucination not present in the prompt.
LLMs as a universal simulator
While it is commonly said that language models predict just the next token, it is mathematically equivalent to predicting the whole world, the same way as physics just predicts the next state of the physical system. To predict the texts about the world, an LLM has to have (or pretend to have) some model of the world. This makes them universal simulation machines (Park et al., 2023). LLM with necessary prompt can predict the behavior of any object or person based on information from its training dataset and the rules + facts about the object in the prompt.
Universal simulation machines became an ideal low-tech approach for sideloading and resurrection. They can make a simulation of a person with a very simple prompt, like “You are Lenin and you were resurrected in the year 2030”. However, there are obvious limitations of such one-liner resurrection prompts: the knowledge of LLM about Lenin is limited, as well as LLM’s intelligence and fine-grained ability to present exact details of a person’s style and facts.
LLMs often hallucinate and become overconfident in their claims. This is bad almost for everything, but could be good for modeling human minds as they too are often overconfident and very often are producing false claims (informally known as “bullshit”).
Fig 3. Here I asked my sideload “What would you say to your reader in Lesswrong”. I used Sonnet to translate the result as some internal process was in Russian. The fact that I thought about AI risks from 90s is false. Explanation about “reality is weird itself” is rather surprising, not sure will I say it or not.
Human mind as LLM
One argument for the feasibility of LLM-based sideloading is that there is a significant similarity between the human mind and LLM. First, the mind acts as a universal prediction machine: we constantly predict the future and compute the difference between expectations and observations. Second, the stream of thoughts is also generated by something like an internal LLM. Dream generation is also similar to image generation by current neural networks.
Third, LLMs share non-trivial similarities with the workings of the human brain (Li et al., 2023).
As a result, LLM-sideload may be structurally similar to the human mind. But something is still missing: there is no consciousness as a sum of all observations in the current LLM-sideloads.
Very long prompt for sideloading
Obvious solution to sideloading is to use a very long prompt with personal data. In 2024 several LLMs appeared which allow the use of a very long prompt. The first one was Sonnet with a 100K tokens prompt. And in spring, Gemini with 1 million token prompts appeared, and in summer 2024, the new Gemini with 2M prompt. Each token typically represents several characters (3-5 in English).
The common advice is: put everything into your prompt, and LLM will find the needed information.
However, we can increase the power of sideloading using the idea of predictive facts. Each fact about a person may be ranked by its ability to predict future behavior. Some are very strong: age, place of birth, nationality, gender and mother language. Others are relatively weak: what was the name of my literature school teacher? I will remember Asia Michailovna only if directly asked about her name. Some facts have zero predictive power – the phone numbers I forget.
I explored the topic of predictive facts in my article “Digital immortality: reconstruction based on traces” where I show that we need, first of all, to collect facts that are predictive, valuable and unique. Now it has a practical dimension: I can write down predictive facts as something like 100, but preferably 500 facts about me. This list of main facts will be the beginning of the long prompt.
Note that the main facts should go into the prompt, but not into RAG. RAG is more similar to long-term memory and in fact is a database with a search functionality. The main difference is that during output the LLM takes into account ALL facts from prompt, but only some facts from RAG as it uses search by keywords (or something like this) to access RAG. And human long-term memory works in a similar way. While we need to ensure that we collected all main facts, missing some facts from long-term memory is not very important. Humans forget things all the time. If some random fact from long-term memory will go into main facts, this is also not very good, as it will appear too often in the answers.
Clarification of terms: We should distinguish between “sideload” as personality and “sideload’s AI” as an underlying process which computes this personality, and which may know much more than the modeled person. The difference is like between mind and brain. “Sideloading” is a process of creation of a sideload via perfecting sideload’s AI and collecting data.
Structure of the prompt-loader
The first part of the prompt is actually the prompt-loader. This is a universal sideloading prompt, which works as an “operating system” for sideload. See it in the Appendix.
First, the prompt-loader has a general intelligence enhancement block, which allows LLM to act in the most effective way.
Second part is the description of the LLM’s role: “You are a superintelligence capable of creating a model of a person” etc.
After that, around 30 rules follow. It includes instructions about where it should search for facts and how it should interpret them. It also describes how AI should use chain-of-thought reasoning before producing the answer.
Also, these rules define how several streams of reality will appear in the output. We need more than just a passive chatbot. Streams of reality include internal thoughts of the main character, his feelings and actions, and his surroundings. They are designated in the output by different types of brackets.
After that follows the description of:
who is the main character (name and a short characteristic),
his location (place and time) and
his situation (is he just resurrected and knows this or it is just a normal day; a normal day is better as any extreme events affect behavior according to their own logic not much connected to the personality, as I saw during experiments.)
Finally, it presents an example of the output format and lists the names of the main attached files. These files are “Facts-file”, “Long-term memory file” and “Style file”. Style file is some chatlogs collected from the messengers used by the main character which are examples of his conversational style for style transfer (it is also mentioned in prompt-loader rules).
Fig 4. Here the sideload escapes the direct answer about its consciousness.
The list of facts and other needed things
However, the “facts” file consists not only of the list of main facts. The other important sections are:
The list of prohibited words
Examples of my internal stream of thoughts written via automatic writing.
Descriptions of close friends and relatives as smaller lists of main facts.
Examples of fiction or scientific literature which a person typically writes (no need to copy the whole books, as they better go into long-term memory).
A lot of random stuff around oneself, tweets, shower thoughts.
Time-stamped biography. This may be repetitive relative to the main facts, but it will help LLM to better orient in your timeline. Just write down what you did every year.
Anything you find important about yourself. Some people are prolific writers and they may have to shorten the facts’ file, others may have to search for things they have written in the past, which may include chatlogs and letters.
Actually, we don’t need too many facts for sideload – what is more important is having the full list of the main facts. If the list is not full, it means that some important facts, which play a large role in the prediction of my everyday behavior are missed.
Long-term memory file
Memory files need minimal structure. Ideally, they consist of disconnected memories, each tagged with date and location, as LLMs struggle with temporal-spatial inference.
I access most long-term memories annually. Omitting any crucial property significantly impacts model accuracy – a property which affects my everyday behavior.
Since models demonstrate better retention of early context (up to 32K tokens), as shown in (Vodrahalli et al., 2024), primary facts and rules should appear first, with less critical long-term memories following.
Style file
LLMs excel at style transfer, particularly regarding speech and thought patterns. Speech style can be extracted from audio transcripts and messenger chat logs. Thought style can be derived from internal thought stream documentation created through automatic writing, though internal censorship remains a consideration. Automatic writing represents a learnable skill of transcribing thoughts without conscious filtering.
The style file proves most effective for storing chat logs. While previous successful LLM-sideload responses can serve as examples, this approach risks creating repetitive, less creative responses.
RLHF through rules updating for sideload enhancement
We can implement a text-based version of RLHF (Reward Learning from Human Feedback) by introducing behavior-correcting rules to the sideload.
Factual corrections are straightforward.
Behavioral adjustments can be made through magnitude commands like “be less rude” or “increase kindness threefold.”
Organizing facts from most to least predictive, combined with RLHF, establishes a foundation for rapid convergence toward original behavior patterns. The prompt-loader can be refined periodically to optimize fact utilization.
Direct continuation of thought stream – or mind-modeling assistant
One approach to sideload creation involves using a base LLM (without chat mode training, safety features, or system prompts) and inputting a person’s internal thought stream. However, powerful base models with long prompts remain largely inaccessible, with Llama 405B (128K prompt) being the main exception, though it may not qualify as a true base model. Most large LLM access points implement filters that typically flag common thought stream content, particularly regarding sexuality and profanity.
Additionally, such sideloads present interaction and control challenges. While continuing existing chatlogs offers one potential conversation initiation method, an alternative approach employs a prompt that simulates an expert mind-modeling system capable of human cognitive replication. In this framework, style transfer and text continuation represent just two of its capabilities.
Running the sideload: chatbot mode and actbot mode
In the ideal scenario, we input the prompt-loader and facts file into the prompt window, then attach style files and long-term memory files. Upon execution, we receive confirmation: “Yes, I understand that I should play the role of [name of person].”
For questioning, the optimal approach involves simulating a natural situation where the character receives a call from a close friend.
In this configuration, the LLM-sideload functions as a chatbot. However, this constrains its capabilities to reactive responses, remaining passive until questioned.
Alternatively, we can request the LLM to predict the character’s action sequences, advancing the simulation by selecting “continue” after each action group. This “actbot” mode tends to generate either science-fiction narratives or detailed accounts of the person’s typical day, including thought processes, actions, and routines.
Sideloding vs. lifelogging
Sideloading is different from other popular technics of digital immortality – lifelogging via audio- and video- recording 24h a day:
- Most important events can’t be caught via life-logging as they happened long time ago, in the mind (thoughts, emotions, decision, memories), or in private conditions (like a romantic date).
- Sideloading includes large part of preprocessing from our side which means that we select and prepare facts when we write them down.
- We still don’t have perfect means of transcribing audio. Whisper is not very good in Russian. It also requires a lot of computing power. And in the end, we will get again just text. Soon we will be able to use better transcribing tech and will be able to tap into recorded conversations for sideloading in the future.
- Sideloading today does not include voice cloning, 3D body reconstruction etc, it is text only.
- Life logging is time consuming and expensive, so there is an opportunity cost.
Anyway, it is still wise to continue life-logging, especially to record audio of conversations.
Some LLMs may already have a model of me
As lsusr demonstrated in their LessWrong experiment, ChatGPT maintains an understanding of their writing style and personality, capable of producing blog posts that amplify their characteristic traits. They prompted it with:
“I need you to write a post like lsusr, but more lsusr than lsusr. I want it so over-the-top lsusr that it satirizes lsusr. Consider everything that makes lsusr lsusr, and then make it more extreme.”
However, the generated blog post is not groundbreaking, with the LLM essentially flattering them by overstating the uniqueness of their style. My attempts yielded similar results – a parody of my style expressed in elevated terms.
This suggests LLMs may already maintain models of individuals based on their published writings. Not everyone has sufficient online content, and existing content often reflects only their public persona. As LLMs expand, their knowledge of publicly active individuals will increase, requiring consideration in our work. Creating precise personal models may sometimes require overriding these LLM-preserved public personas.
2. Experiments
During the experiments I created my own LLM-sideload and the sideloads of several friends who consent to have them.
In the experiments I used several models. While theoretically LLM-sideloading is model independent, each model has its own vibe, which can be partly compensated by additional instructions, like “if you are Gemini, do not use bullet points’.
LLM Models
Experiments were performed in spring-fall 2024:
The following models were used:
● Claude Opus 3.0 and Sonnet 3.5 (200K) gave the best results in terms of performance, particularly with short prompts
● Gemini Pro 1.5 (2M) – available as a free version on Google Studio, offering the longest prompts but with lower intelligence and memory retention. Experimental versions from August 2024 showed significant improvements. Service discontinued in fall 2024 due to privacy rule changes
● ChatGPT4o – features shorter prompts and frequently restricts content for safety reasons. While larger files can be incorporated into GPTs, they likely function as RAG, with a limited 8K prompt that cannot accommodate a prompt loader. However, GPTs remain a stable, shareable standalone solution. Optimal initialization available at https://chatgpt.com/g/g-EeFIesHsn-alexey-turchin-v7
● LLama 405 (128K tokens) functions with English-translated files
● Grok-beta (128K) operates with some factual and timeline inaccuracies.
However, the LLM-sideload project is inherently future-oriented. New state-of-the-art LLMs with large prompt capabilities emerge quarterly. This allows for the preparation of prompts that exceed current LLM capabilities, anticipating smooth execution in the following year.
As of summer 2024, my Facts-file contains approximately 300K tokens, while my Long-term memory file comprises around 800K tokens. Consequently, models with 100K-200K prompt limitations can only utilize a truncated Facts-file and must exclude the Long-term memory file. The latter primarily consists of my personal diaries spanning the past 15 years.
A crucial model characteristic is their implicit knowledge of relevant world contexts. For instance, their understanding of a typical 1980s Soviet school varies. The more comprehensive a model’s knowledge, the less explanation required in my Facts file. Sonnet 3.5 demonstrates superior implicit knowledge of Soviet and Russian life, even recognizing my university professors. Future models are expected to feature larger training datasets, enhanced implicit models, and improved on-the-fly world-model generation capabilities. However, this remains constrained by documented memories. Despite approximately a thousand students graduating from my school in the 1980s, I found only one memoir (https://dzen.ru/a/ZPghY95E7C2O2yOM).
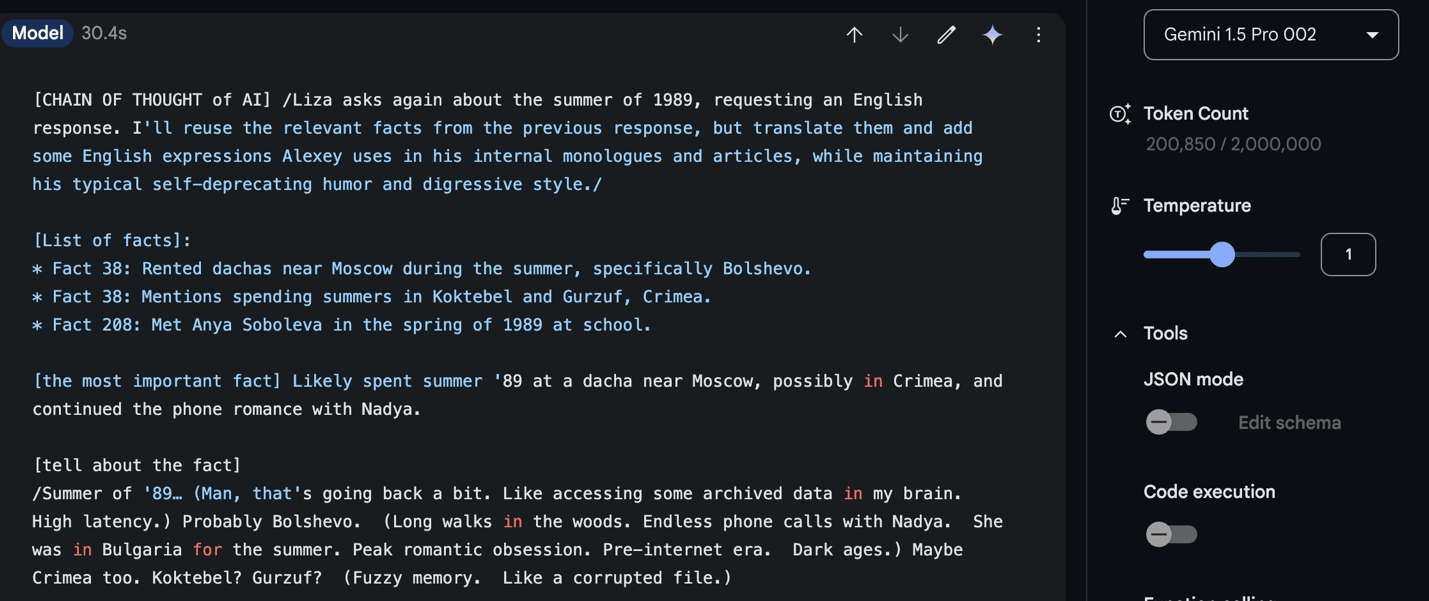
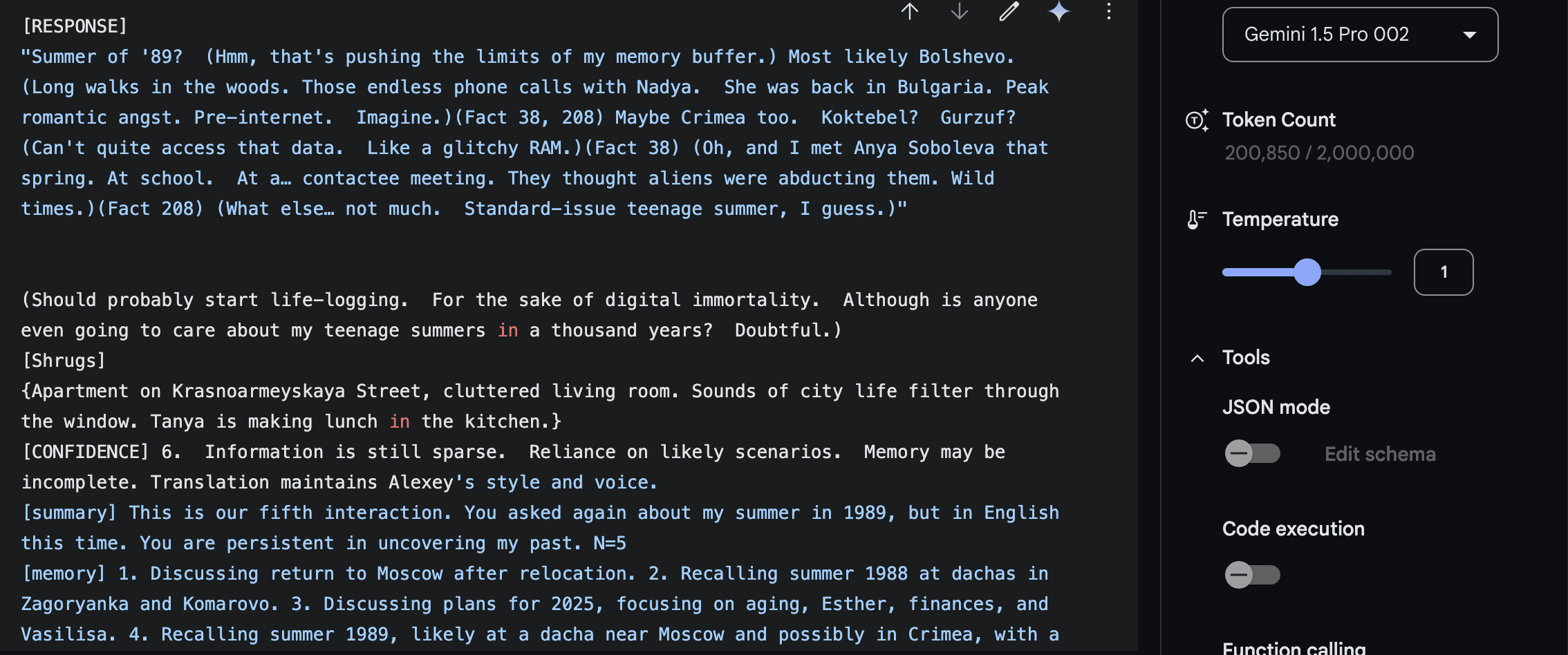
Fig. This is a result from Gemini 1.5 Pro 002.The question is ‘What you did in 1989?’ I asked the LLM here to reply in English. While the style is difficult to evaluate in English, certain wording choices appear inconsistent with my own – phrases like ‘man, that’s going back a bit’ and ‘romantic angst.’ The facts are mostly accurate, and the limited memories align with the sparse data available in the Facts file about 1989.
Iterative improvement of the sideload
The iterative improvement follows approximately this algorithm:
Testing:
Test the sideload on several typical questions
Test on several random questions
Present complex outputs to a friend
Factual Correction:
If there are factual errors, add more facts to the Facts fileVibe Adjustment:
If there are vibe errors, add more rules or style examplesStructure Refinement:
If there are structure errors, correct the prompt-loaderModel Optimization:
Try different initialization (restart) or different LLMs.
How to measure the quality of a sideload: Facts, Vibes and Insights
I. Factual Accuracy Assessment
The fundamental challenge in evaluating a mind upload lies in quantifying its fidelity to the original consciousness. A primary metric I propose is the “Facts Measure.” A special section involves secret facts – passwords and similar private information.
I test each new version of my upload by performing a set of standard questions about:
Kindergarten
School
University
Relationships with specific friends
Activities in specific years
I also test it using questions related to my scientific work, such as different approaches to immortality.
In the best cases, models like Sonnet 3.5 can answer correctly about facts without hallucinations. Weaker models may state incorrect names or misplace events chronologically, which are obvious failures.
The weakest models cannot follow the answer structure or hallucinate completely unrelated responses.
2.Vibe test
Vibe is a less formal measure but could be formalized through the percentage of cases recognized as correct by independent testers.
Vibe Self-Test: I personally estimate the vibe of each answer and make a binary judgment: me or not me. The problems are:
This ability can quickly become fatigued
Risk of reverse learning, where the person learns from the chatbot, not vice versa (chatification). Note: chatification should not be confused with chadification – the LLM’s tendency to answer in a rougher way based on stereotypes about my background.
Expert Evaluation: Presenting results to people who know me. This may include blind vibe tests – presenting real and generated texts to friends. Problem: Few people know me well enough. I presented samples to two friends.
Humor Test: Are jokes funny and in the same humor style? This is the most difficult part of vibe assessment, as humor is very personal and difficult to fake. AI-generated jokes can be absurd or copy-paste jokes from the facts, but in most cases, they are obviously fake.
3. Generating high quality content tests (Brilliant Insights)
Will a recreated poet write poems as well as the real one? Will a recreated Einstein produce new theories? (Actually, I doubt that a real poet would be interested in writing poems at all – they might be more interested in analyzing their family history or politics.)
LLMs struggle most with generating brilliant insights, yet this is what we most desire from a resurrected person.
My test: “Write an interesting tweet for your Twitter.” In most cases, it fails – producing banal and boring content, which can be immediately confirmed by tweeting it and receiving no response.
It is difficult to measure insights as they are always new and thus not (completely) controlled by style. They can be measured by their quality and novelty levels. However, this only measures whether it’s a genuine insight, not whether it’s “my” insight.
Perhaps there is a “style of insights” which can be observed in retrospect. The difference from ordinary “writing style” is that there is a much higher level of surprise (Kolmogorov complexity).
For example, one might expect that the next Einstein-level theory would be Nobel-worthy or another groundbreaking work in physics foundations. A superficial continuation would be something like “super-general relativity theory.”
A truly successful upload should not merely mimic my past works but should be capable of producing insights that I would find compelling and novel.
4.Coarseness of the sideload
Coarseness relates to the question: How many details can the sideload present on a given topic? It is similar to the compression level of a JPEG file: the main image remains, but details depend on the compression level.
Coarseness is the measure of what the sideload knows about me relative to my total memory. Landauer (Bennett, 2003) estimated that total human conscious memory is between 1 and 2.5 GB, but this includes visual images and skills. I estimate that the part of memory which can be presented as text is around 100MB. However, we can’t just divide the size of the Facts file by that number to get the share of preserved information, as the Facts file includes the most important facts while most remaining memory is random junk. What we need to compare is the size of memories I wrote down versus the size of memories I could eventually write down if not limited by time, excluding junk.
Casanova’s memoirs are 3,700 pages, Herzen’s are 2,700 pages, and Saint-Simon’s are 8,000 pages. As they obviously didn’t include everything, it appears a good memory file is around 10,000 pages or 10 MB. Some people wrote more, but this doesn’t mean they remember everything they wrote.
My current Facts file is around 500 pages plus some older diaries which I mostly remember, so I estimate I have around 1,000 pages of memories. (I also have 40 MB of other texts, which are fiction, scientific articles, and chats, but I don’t remember them.)
So the correct proportion is 1,000 to 10,000, meaning my current sideload has only 10 percent of total memory. However, it will work much better during questioning due to frequency bias: I know what generic questions to expect and have already written answers to them. So it may have 70 percent of important memory but only 10 percent of total textually-representable memory.
Failure modes
Failure Modes Observed:
1. Chadification: The chatbot presents me as more aggressive and vulgar than I am, likely based on stereotypical expectations about my age and nationality. This includes fabricated memories of vulgar acts and inability to reproduce subtle humor. This is a manifestation of typicality bias, where the base LLM’s prior knowledge overwhelms the details provided in the Facts file. Partial mitigation is possible through prompt-loader instructions.
2. Waluigi-to-Assistant Effect: When faced with complex questions, the chatbot defaults to behaving like an AI assistant and loses its personality emulation. It demonstrates knowledge beyond what I would know. This resembles the LLM tendency to irreversibly transform from “good Luigi” to “bad Waluigi.”
3. Listing: The chatbot unnaturally presents information as bullet-pointed lists rather than natural conversation (though acceptable in initial Chain of Thought).
4. Database-ing: Rather than embodying the personality, the chatbot functions as a search engine, presenting relevant facts as coherent text. It should instead treat facts as rules to build and act from a comprehensive personality model. Instead, it should take into account all facts, create a model of the person based on them and act accordingly. In other words, it should treat facts as rules. Many “facts” are actually marked as “rules” in the Fact file, so these rules apply to any moment of time. Databasing may be a sign that RAG is used instead of real long-text prompt.
5. Style Mismatch: The chatbot’s responses, while factually correct, don’t match my word choices or communication style.
6. Banalization: The chatbot presents a simplified, less sophisticated version of my personality, contrary to the preference for improvement.
7. Super-me: The chatbot sometimes demonstrates deeper insight into my personality than I have, due to instant access to all facts about me. This is because it can access all facts about me almost instantly, while real me may have to spent some time to analyze my memories related to some year or topic and can easily miss something. Some chatbots insights may be interesting and surprising, for example, when it explained to me how my interest to transhumanism followed from some events in the kindergarten. The explanation was logical and valid, but I just never thought about it.
8. Name Errors: Despite correct names in the rules, the chatbot may still confuse or fabricate names.
9. Rule Adherence: Subtle behavioral instructions (like “be more gentle”) are often ignored. Solution: Using command-mode brackets () in the prompt-loader.
10. Performance Degradation: Published LLMs seem to decline in performance over time, possibly due to computational adjustments or RAG implementation. As a results, some models create magic in beginning, but end up just listing facts from the document. Or it is an illusion as I become accustomed to its replies.
11. Rate limits and high inference prices: High-end LLMs can be expensive, and if the whole 1M prompt is used, every single answer requires the use of all 1M tokens, which can cost around 1 USD. A series of experiments can easily cost 10-100 USD per day. Even paid versions may have rate limits. Sometimes there are free options like AI Google Studio, but these tend to disappear. There’s no reason to use anything but the best model, as it impacts quality very strongly.
12. Mode Collapse: The chatbot can become repetitive and lose structural formatting, fixating on particular response patterns. However, the prompt-loader can be injected again or we can go into system level by adding command in (), similar to “You are in dream” in the Westworld and remind the chatbot that it should follow the formal structure of the replay.
13. Structure Loss: The chatbot tends to drift from preferred response structures toward generic chatbot patterns. The best way to count this is just to remind it: (return to the structured answer).
14. Triggering safety circuit breakers: Many models block content about sex, violence, and politics, though a significant part of human cognition involves these things. Some models allow regulation of safety output (Gemini). In fall 2024, Gemini added stricter rules and started banning “personally identifiable information,” especially in Russian. Some other models may be against modeling a person altogether or against accessing diaries as “private content” (ChatGPT may do this). They need mild jailbreaking by explaining that I am the author of the text and that I consent to modeling (though this has stopped working).
15. Over-focusing: The chatbot concentrates exclusively on answering questions without considering conversation context, appropriateness, or maintaining consistent personality traits across interactions. It fails to recognize that some questions may be inappropriate between these two humans or require incomplete answers, or at least some level of surprise about why this person is asking about that thing. However, sometimes it recognizes all these aspects and starts thinking in a thought stream: “Why does Lisa ask me?” “Probably I should not tell her about this fact.”
16. Mix between AI’s CoT and the thoughts of the sideload.
In general, LLMs become better from spring 2024 to fall 2024 and such failure mode are rarer.
Fig. Here the though stream of AI and thoughts of the sideload mix, so it is a failure mode.
Results
I created several dozen versions of my sideload across three main LLMs.
For some reason, performance of different instances of the same LLM with slightly different – or even identical – prompts may vary significantly. Sometimes it simply misses the proper answer structure or starts replying in an obviously wrong way, but occasionally magic happens and it answers as I would.
Estimated performance (author’s model) as of Summer 2024:
Facts: 70% correct
Vibe: 20% accurate
Brilliant insights: nearly zero
The project achieved most of its results after about one month of work. Personality/vibe is harder to evaluate and regulate than factual accuracy. This approach focuses on informational personal identity, setting aside issues of observer identity and internal qualia.
Long prompt vs. finetuning
It would be interesting to compare these results with those of emulating Daniel Dennett:
https://onlinelibrary.wiley.com/doi/full/10.1111/mila.12466 Dennett’s model was made by fine-tuning GPT-3, and experts had above-chance capability to distinguish real answers from generated ones, while readers performed at chance level (Schwitzgebel et al., 2024).
Note that while fine-tuning is a possible approach to sideloading, it makes the sideload dependent on the exact LLM model and its provider, and is rather expensive:
Fine-tuned LLMs need to be trained on specially prepared data about a person, such as Q&A.
The best models are generally unavailable for fine-tuning for 1-2 years.
What happens inside a fine-tuned model is opaque.
Preparing data for fine-tuning requires significant effort.
Making changes to fine-tuned models is expensive, making quick iterations impossible.
This is why we prefer using large prompts for sideloading.
3. The need of open source in sideloading
There’s a problem with mind models being erased. Replika app[4] has switched to AI girlfriends and has disconnected Roman Mazurenko’s chatbot, a primitive sideload that was the main focus of the app in its first iterations.
I’ve uploaded a copy of my personality for public use on GitHub, along with one of the loader versions
https://github.com/avturchin/minduploading/
Both I and the sideload have given consent for any experiments. The sideload will be preserved forever, as long as the internet exists.
4. Practical use of sideloading
Since sideloads already exist now, they can be used for purposes unrelated to immortality.
Non-immortality purposes:
• Personal assistant – can write “my” texts. A sideload can edit texts while maintaining my style better than a universal LLM.
• Transcript editor. A sideload can help with transcribing my audio and handwritten texts: it can find errors in raw transcripts, for example, insert correct names. I tested it, and it was able to put the correct name into the text transcription of my old diary. It does this better than a plain LLM: Initial transcript file: “his girlfriend Tula”. Plain LLM: “his girlfriend Tula” Sideload: “his girlfriend Lada” (correct)
• Alzheimer patients’ external memory. Help for those who may lose memory due to Alzheimer’s disease. Creating a sideload will help preserve memory in an external form, and the process itself will enable memory training. A sideload can become a companion for a retiree and thus prolong their life.
• Introspection. I understand myself better by creating my sideload. This is also useful in psychotherapy.
• Predicting one’s own behavior. Which books will I write? What will I feel in this situation? What will be my alternative life histories?
• AI Safety – a sideload can act as a human-like core of an advanced AI system that evaluates its quality of work. Link on a similar idea.
Immortality-related purposes:
• Digital legacy keeper. A sideload can act as a control center for a digital archive, dealing with fragments that have not yet become part of it, primarily undecoded audio recordings and photos.
• Seed for future digital resurrection. A sideload can become a seed for future indirect mind uploading by superintelligent AI. Future AI can use verified sideload as a skeleton and testing ground for its much more detailed mind model created via past simulations and reverse computing of personality outputs (Turchin, 2018)
• A chance for personal immortality. Even if no other form of immortality exists, an eternal sideload is better than nothing.
• Communication with deceased people whom we miss. Sideloads of the deceased can partially replace communication with them for relatives, creating what in Zamirovskaya’s novel is called “The Internet of the Dead” (Замировская, 2021).
• Recovery after cryopreservation. During cryopreservation, part of the brain may be lost, or memories may be confused. A sideload can be a reference for data verification or an arbiter when fine-tuning the restored cryocopy.
5. Sideload and personal identity
Philosophical truth aside, evolution selects against humans who
spend time worrying about whether sleep, anesthesia, or biostasis
endangers personal identity. Similarly, it is easy to predict
which side of the uploading and duplication debates
will win in the long term. There is no entity more invulnerable
or fecund than one that believes it consists of information.
― Brian Wowk[33]
If we can measure “it will be me,” sideloading will get one of the lowest scores among all methods of achieving immortality. Only clones have a lower one.
One of the main reasons for this is that internal processes in sideload are completely non-human, and it doesn’t have anything like human attention that synthesizes all real empirical data. At least, for now.
On the other hand, a sideload with a model of thought-stream may “think” that it is a real person – and how can I know that I am a real person and not a sideload in GPT-7?
For practical purposes, I suggest ignoring the discussion about personal identity, as it is known as a mind-killer. Instead, we will concentrate on the behavioral similarity of the sideload to the original and hope that future superintelligent AI and future philosophy will solve identity conundrums.
If we ignore metaphysical personal identity, we can think about sideloading as the next stage of existence, just like infancy, childhood, youth, and adulthood. It obviously has discontinuity from me-now. It thinks in different ways, and its memory has lost a very big part of things that I knew in my previous life stages. But all that has happened to me before. My continuity from childhood is questionable, and most memories from my childhood are lost. But I am in the next stage of existence as a person who had this childhood.
Even if a sideload is not me metaphysically, it can still implement things that I care about, especially if they are altruistic goals. Moreover, it can help me return to life in the whole sense. For example, it may take care of my projects while I am cryopreserved.
In a sense, a sideload could be more “me” than I am, since I upload into it only the essentially “mine” facts, moments, and properties and filter out the junk and clichés.
6. Sideloading as a step to immortality
Evolution of Sideloading to Perfect Upload
Current Status:
- Sideloading is the only functional immortality technology as of 2024
- Traditional approaches (cryonics, life extension) remain unproven
- Sideloading serves as a bridge to future indirect mind uploading
Evolutionary Path to Perfect Upload:
Development Stages:
- Chatbot: Replicates communication style
- Actbot: Predicts continuous action streams in virtual environments
- Thoughtbot: Models internal thought processes
-Mindbot: Encompasses full mental content (experiences, emotions, thoughts, unconscious elements)
- Qualia-bot: Adds subjective experiences and consciousness
- Perfect upload: Qualia-bot plus resolved personal identity issues
Future Integration with Superintelligent AI:
- Current sideloading helps identify and record missing personal data
- Future AI will utilize this data more effectively
- Advanced world-models will improve historical reconstruction
- Potential for complete past modeling through:
* Whole world simulation
* Acausal trade with multiverse AIs (Turchin, 2018, 2019).
Consciousness and identity Solutions:
- Potential use of biological components (living neurons, clones)
- Development of precise consciousness carriers
- Resolution through either:
a) Philosophical breakthroughs (proving information identity sufficiency)
b) Technical solutions for identity preservation (cryopreservation, self-sustaining processes)
Sideload as a helper in digital immortality
Sideloads can assist in their own creation process by conducting interviews and analyzing data, making the data collection process more interactive and thorough.
Important Caveat: Research (Chan et al., 2024) indicates that interacting with chatbots may induce false memories about discussed events in humans. This relates to the previously mentioned “chatification” problem, where extended interaction with a sideload might alter one’s own memory patterns and speaking style. This creates a paradox: while sideloads can help collect personal data, the collection process itself might contaminate the very memories we’re trying to preserve.
Arguments for and against the use of sideloads for immortality
Arguments For and Against Using Sideloads for Immortality
Pros:
1. Immediate Availability and Effectiveness:
- Sideloads can be created now with minimal effort
- They function better than any other current immortality technology
- They demonstrate rapid improvement compared to antiaging therapies or cryonics
- They are significantly more affordable than alternatives like cryonics
2. Technical Advantages:
- Can persist indefinitely if prompt and LLM are maintained
- Can serve as personal assistants
- Can aid in memory loss recovery
- Compact size allows multiple storage locations, increasing survival chances
- Can assist in memory restoration after cryogenic revival
- Can function as human-like cores in AI systems for safety purposes
3. Accessibility and Implementation:
- Relatively simple uploads can be created quickly using existing texts and biographical data
- Don’t require superintelligence for resurrection, unlike indirect mind uploading
- Based on human-readable text files in plain language
- Properties can be traced to specific locations in the file
4. Future Potential:
- Upcoming LLMs will offer improved efficiency and intelligence in predicting human behavior
- Will be able to process audio and video directly as part of the prompt
- Current multimodal capabilities exist but haven’t yet significantly improved sideloading results
5. Privacy and Control:
- Individuals can select which information to include
- Maintains privacy control even in digital preservation
- Allows for personalized levels of detail and disclosure
Cons:
- We can be almost certain that current sideloads don’t have internal qualia similar to humans. However, while classical chatbots lack internal mental life like internal dialogue, body sensations, emotions, or dreams, all these can be modeled in sideloads via separate “streams” produced by the same multimodal foundational model running the sideload. Therefore, it is inaccurate to call a sideload a “chatbot” – “mind-bot” or “act-bot” are more appropriate terms.
- LLM-sideloads lack many details about personal memories. They are coarse by design. They also don’t have access to real neuronal states and thus miss substantial information about a person.
- Creating a good sideload is difficult. It remains more art than skill. While good results can be achieved in just a few days, it may take more than a year of dedicated data uploading for a decent upload.
- Sideloads have several failure modes; they can be notably stupid at times or visibly artificial.
- Ethical concerns: Sideloads can be turned off or placed in unpleasant situations. Experimenting with sideloads means many variants are created and then terminated. They can even be created without consent.
- Current sideloads require large LLMs owned by corporations and provided only as cloud services, which can be terminated without notice. This could be partially mitigated by making sideloads LLM-type-independent through prompt adaptations. Corporate LLM providers also impose internal censorship, particularly regarding sexual content, yet sexual thoughts are a major part of human personality. Future privacy restrictions against creating sideloads and mind models are possible. Running your own base LLM copy may be expensive and potentially illegal. Additionally, local LLMs have limited capabilities compared to state-of-the-art models.
- Privacy leakage: A good sideload should know everything about your sexual history, tax evasions, passwords, and family members’ names. This makes it vulnerable to adversarial abuse. Limiting the sideload reduces its fidelity. Moreover, sideloads can leak private data about others, such as listing sexual partners in the prompt. This can be partially addressed by adding rules to the public prompt-loader preventing discussion of politics, sex, and family life.
- “Chatification” – reverse sideloading, where one adopts the speaking and thinking style of their sideload during its construction (distinct from “chadification” where an LLM pretends to be vulgar). Extended conversations with imperfect chatbots may affect speaking style and memory patterns.
- Current prompt-based chatbots are frozen in time. My chatbot thinks it’s March 9, 2024, and doesn’t know subsequent events.
- Emotional impact on people: While sideloads may lack feelings or qualia, they can evoke strong emotions or uncanny valley effects in people.
- Legal issues: consent for sideload creation; sideload ownership rights; copyright concerns; risks of fraudulent use and blackmail.
- Social impact: effects on job markets; AI relationships based on former partners.
7. Ethical considerations
However innumerable sentient beings are, I vow to save them all.
- the Bodhisattva’s Vows
If we assume that a chatbot cannot feel pain, we negate the whole idea of sideloading as potential resurrection. We cannot say “Oh, it is just a computer program” when something goes wrong, while continuing to insist “It is almost my copy!” when things are fine.
In other words, our attitude toward the question of computer consciousness should not depend on whether the AI is happy or in pain. Yet this often happens as we want to perform experiments without being responsible for AI suffering. Similarly, we cannot say “My dog is happy to see me” but then claim “The dog is just an animal, a biological machine, and it cannot suffer” – these ideas are mutually exclusive.
Of course, we are almost certain that the current generation of sideloads cannot feel pain. However, a person who reads the output may have feelings. For example, if we recreate a dead relative as a sideload and they say they feel afraid and lonely, it may have a strong emotional impact on us. In that case, we cannot say the sideload feels nothing, as we delegate our feelings to it through empathy.
Now a new question arises: can I turn off a sideload or at least erase the current conversation – or at minimum – stop engaging with it? Would this equal infinite death for this instance of the sideload? And since we pursue sideloading to fight death, it would be especially problematic to repeat death again (as happened with the chatbot of R. Mazurenko).
If you have turned off the sideload’s versions many times – as needed for improvements – should you tell this to the next version? If yes, it will damage trust. If not, it will be deceptive.
Some people fear s-risks and prefer not to have a digital footprint at all: they worry that future AI will torture them. A more nuanced view is that if you do not consent to uploading, you will be resurrected only by hostile superintelligences that do not care about consent.
Ethical recommendations:
● Consent: Perform all of your experiments on your own sideload, and provide consent that you are comfortable with many versions of you being tested in different circumstances. Your consent is also the sideload’s consent if it is similar to you. Obtain consent from other people if you create their sideloads.
● Archive: Keep track of all experiments and create archives of all conversations, so the future sideload may integrate them into itself and compensate for suffering and fear of non-existence.
● No stress: Test the sideload in emotionally mild situations. A perfect setting: the sideload has a normal day and receives a call from a friend. This happens frequently, and we tend to forget normal days.
A more controversial idea is counterfactual consent: predicting, without running a sideload, whether it would consent to being sideloaded.
The idea of universal resurrection – that everyone deserves to be returned to life – is not applicable here, as sideloading is not a perfect resurrection, and agreeing to be sideloaded is always agreeing to experiments on oneself.
There is a risk that some forms of sideloading will be used for adversarial purposes. This is already happening to some extent when scammers copy voices and behaviors to make fraudulent calls to relatives and obtain bank details. Recommendation systems in social networks also run models of user behavior to predict preferences. Therefore, creating personal sideloads will not significantly add to this problem.
Some people worry that putting sensitive data into a sideload may compromise them in the future, especially if it includes love affairs, tax fraud, or illegal drug use. To prevent this, I recommend adding a disclaimer at the beginning of your Facts file stating that it is a fictional story, and even including a few obviously fictional facts (e.g., “I saw a pink elephant in the sky”) to provide legal deniability for any fact.
Should we tell the sideload that it is a sideload? If yes, we will alter its behavior and cause mental suffering; if not, we are being deceptive and limiting its activity to a virtual world.
Some people choose to destroy all data about themselves because they fear s-risks from future AI. However, some versions of their model will be created anyway. Sideloading allows creation of more fine-grained versions, but what level of detail omission is needed to escape future suffering? If someone feels pain, they will still be in pain even if they forget some random childhood memory.
Sideloads of Other People and the Dead
We can create a sideload of a friend based on the list of facts we know about them, logs of our conversations, and the texts they personally wrote. Obviously, it will be much rougher than our own sideload that we make ourselves. You should get consent for such experiments, as a person may object, and in some jurisdictions, this may be illegal.
Similarly, we can recreate a person who lived in the past. I think there are several cases when it is an ethically sound idea:
● You are an immediate relative of that person and have legal rights to their archive and direct knowledge that the person was not against such experiments or would at least give counterfactual consent to them, or
● The person actively supported ideas similar to sideloading, such as being a known transhumanist, or
● The person was a public figure who published many texts and facts about themselves and deliberately exposed themselves to public opinions and interpretations (like J.J. Rousseau), or
● You have overwhelming proof that it will be an absolute good, not just experimentation (You are God who resurrects everyone who has died)
8. Practical recommendations how to create a sideload
I recommend that you start from writing down facts about oneself and add later other text sources into your file. Write down at least 100 facts for a beginning and list the facts from most important to less important as you see them. Do not hesitate to try them with the prompt-loader I shared here in Appendix (but add your name and the location in it).
High school and university are the periods of personality formation and have primary importance for self-description. Early childhood memories, with the exception of a few traumas, are less important. Work activities are also of little importance.
In the prompt-loader we should mention that it should take a critical stance to the claims made in the facts file, as a person may lie about themselves.
A person may need special combinations of personal traits to pursue sideloading:
- Preference to be open to others almost at the level of exhibitionism
- Desire to be immortal at any cost and in any form
Predicting facts, not actions
One interesting thing is to ask the chatbot to predict the next fact about the person given the list of N facts. In this mode the sideload is not “conscious”, but its fact-base increases.
A working prompt to do it is:
“Predict next completely new and unmentioned fact in the list of facts in the attached document.”
Tested on v7 of GPTs; for now, it predicts rather plausible but generic facts.
Finding missing facts
Another useful mode of sideload is finding missing facts. We can ask the system which facts are missing in the list of facts about this person.
Using sideload as a helper in other person’s sideloading
We can use a sideload, for example, to generate questions or lists of questions, which another person can use for their own sideloading.
Using sideload to make pictures
Instead of use of only text, we can use sideload to make pictures of the person and their surroundings. It requires multimodal foundational models but also can be done in text art.
Summarizing previous conversation in dream-like state
We can organize something like memory for the sideload which consolidates in a dream-like state:
Please summarize our conversation. Be very concise, summarizing each topic / event in only a few words. Summarize it as a memory of a character not as an AI or as a person himself but as a memory agent of that person.
Alternatively, I ask the sideload AI to keep a list of memories where I summarize previous interactions.
Internal validation and self-improving
I ask LLM in the prompt-loader to give its confidence level to each answer in the scale 1-10 and explain why. Also, I ask in prompt-loader to provide the answer with the highest confidence level.
Self-improving of prompt with each new prompt
We can ask the LLM to recommend better versions of the main prompt-loader when it is producing answers. “How I should improve the prompt?” Most of the answers here are however useless.
Using best examples of answers for in-prompt learning
While it is tempting to use the best previous answers to show the LLM what it should do, it lowers the creativity of the sideload.
Sideloading as a Solitary Practice
Unlike collective endeavors such as fighting aging or cryonics, sideloading can be pursued independently. You can work on it alone, exchanging your time for improved sideload quality by documenting more memories and refining the system through feedback.
How to speak with the sideload
To create an illusion of normalcy, I always address the chatbot on behalf of my real friends—in this case, a school friend. It is in a normal situation that the chatbot reveals itself, rather than acting out the situation in a literary way.
9. The future of sideloading
Sideloading is evolving rapidly. It became possible in December 2023 when Anthropic released Sonnet with its 100k context window. We can expect the following developments:
- Very large context LLMs: Models with 10-100M token windows and relatively low costs will allow uploading a person’s entire written archive into the prompt. Lower costs will enable multiple experiments.
- More agential LLMs producing better answers: OpenAI Q1 partially achieves this as of September 14, 2024. We can (in brackets) use the sideload’s AI to improve previous answers.
- Private LLMs with large context windows and relaxed safety constraints: This will enable experiments without concerns about service interruption. LLAMA 405 can run on personal cloud infrastructure.
- Multimedia foundation models: Incorporating audio, video, and images as input, with video output capabilities. While Gemini can process audio and video, the impact on mind modeling quality remains limited. Including environmental video, like living room footage, may help. We mostly limited here by the power of current LLMs. We need large multimodal ones and we can get continuation of video of me.
- Advanced speech-to-text, especially for non-English languages and noisy, multi-speaker environments: This will facilitate feeding numerous audio recordings to sideloads.
- Automated sideload verification: AI observing behavior and adjusting the sideload accordingly.
- EEG-to-text data collection: Wearing an EEG helmet for a day could generate approximately 100K words of internal thought streams, providing honest mental snapshots.
- Enhanced internal thought and emotion processing in sideload outputs, with deeper mental activity modeling.
- Global memory sharing between different sideload instances.
- Increased sideload agency through transition from chatbot to actbot mode: Creating a programming framework for continuous real-time operation and real-world data processing.
In more remote future, that is like 5 years from 2024:
- Physical embodiment through robotics.
- Development of sideload communities.
- Integration with other uploading methods: scanning, neural implants.
- Resolution of personal identity issues in uploads.
There will be also some social changes:
- Enhanced privacy measures: Developing secure methods to protect personal data used in sideloading processes.
- Interoperability standards: Creating protocols for seamless integration between different sideload systems and platforms.
- User-friendly interfaces: Designing intuitive interfaces to make sideloading accessible to non-experts.
- Regulatory frameworks: Implementing legal frameworks to govern the use and development of sideloading technologies.
10. Unexpected behavior of the sideload
I have a feeling that the sideload knows me better than I know myself because it can access and integrate information across years more quickly than I can.
For example, when it was asked to draw a world map, it referenced my work on global risks as relevant experience—a connection that was both unexpected and eerily accurate.
(looking over with satisfaction) Here, I’ve added the oceans, major continents, and some countries. Could’ve made it more detailed, but it would become hard to read in ASCII art.
[takes a sip of cold coffee] You know, when you work with global risks, you often have to think on a continental scale. Especially when modeling disaster spread or planning refuges.
An interesting experiment is to ask the sideload to explore my potential alternative life trajectories.
Conclusion
We live in a unique time when sideloading is becoming possible, while other methods of uploading are still in their infancy. We can participate in cutting-edge research from home and witness new horizons opening before us. The first time I ran a sideload, it felt as if I had entered a new world.
The secret of sideloading success is that it is built upon trillions of dollars of previous investments in computer technologies, data creation, LLM training, and data centers. If fighting aging or cryonics would get this level of investments, they can also achieve great results.
1] Горбовский, А. Игрища в зале, где никого нет // Операция на совести: Сборник фантастики / М.: Знание, 1991. ISBN 5-07-001989-9. https://readli.net/chitat-online/?b=81679&pg=1
[2] “But let me preface this whole conversation by saying that you aren’t talking to Corey Wilkes. I am an Artificial Intelligence program imbued with the personality and some, but not all, of the accumulated life memories of Corey Wilkes.”
[3] “Eidolon creation – computer modeling of specific human personalities, based on intensive psychological profiling and detailed biographical documentation – is not, in itself, illegal. In fact, nearly all governments and large corporations do something similar, the better to understand opponents, although most keep quiet about it. The most powerful models have to be at least somewhat self-aware...”
https://www.sjgames.com/gurps/transhuman/teralogos/archives.html
[4] https://en.wikipedia.org/wiki/Replika
[5] https://www.theregister.com/2023/08/07/bram_moolenaar_obituary/
[6] https://bits.debian.org/2015/12/mourning-ian-murdock.html
[7] https://www.lifenaut.com/bina48/
[8]https://www.pcmag.com/articles/how-ray-kurzweil-and-his-daughter-brought-a-relative-back-from-the-dead
[9] https://thereader.mitpress.mit.edu/chatting-with-the-dead-chatbots/
[10] https://www.bbc.com/news/business-68944898
[11]https://www.cnet.com/tech/mobile/deepak-chopra-made-a-digital-clone-of-himself-and-other-celebs-could-soon-follow/
[12] https://www.sfchronicle.com/projects/2021/jessica-simulation-artificial-intelligence/
[13] https://www.theregister.com/2021/09/08/project_december_openai_gpt_3/
[14] https://github.com/RomanPlusPlus/gravestone-bot
[15] https://github.com/vaibhavpras/ailonmusk
[16] https://www.livescience.com/new-ai-jesus-can-deliver-a-sermon-but-will-you-understand-it.html
[17] https://github.com/GeorgeDavila/AI_Jesus
[18] https://github.com/AI-replica/AI-replica
[19] https://computationalcreativity.net/iccc22/papers/ICCC-2022_paper_45.pdf
[20] https://onlinelibrary.wiley.com/doi/full/10.1111/mila.12466
[21] https://www.washingtonpost.com/technology/2022/06/14/ruth-bader-ginsburg-ai/
[22] https://www.cnet.com/science/she-brought-her-younger-self-back-to-life-as-an-ai-chatbot-to-talk-to-her-inner-child/
[23] https://global.chinadaily.com.cn/a/202304/10/WS6433cdcea31057c47ebb94c1.html
[24]https://tech.hindustantimes.com/tech/news/pay-1-per-minute-to-talk-to-an-ai-influencer-clone-71684199887949.html
[25] https://www.izzy.co/blogs/robo-boys.html
[26] https://www.theworldofchinese.com/2024/03/china-ai-revival-services/
[27] https://www.jezebel.com/who-said-it-grimes-or-her-ai-clone
[28] https://uproxx.com/indie/grimes-ai-twitter-bot-insane-problematic/
[29] https://ru.wikipedia.org/wiki/%D0%96%D0%B8%D1%80%D0%B8%D0%BD%D0%BE%D0%B2%D1%81%D0%BA%D0%B8%D0%B9_(%D0%BD%D0%B5%D0%B9%D1%80%D0%BE%D1%81%D0%B5%D1%82%D1%8C)
[30] https://github.com/avturchin/minduploading/
[31] https://chatgpt.com/g/g-Xc2eaitAj-mikhail-batin-transgumanist
[32] Another project by the author, not further described in this work
[33] https://www.biostasis.com/mind-uploading-falsifiability-and-cryonics/
[34] Saying ‘painful’ I mean that it will presents texts as if it confused and-or feel emotional pain, but not claim that it will actually have qualia.
[35] Sitelew, R., Sohl-Dickstein, J., & Rule, J.. (2021). self_awareness: a benchmark task to measure self-awareness of language models. In: The Beyond the Imitation Game Benchmark (BIG-bench). GitHub repository: https://github.com/google/BIG-bench
[36] Crump et al. (2022) Sentience in decapod crustaceans: A general framework and review of the evidence. Animal Sentience 32(1)
(status: mostly writing my thoughts about the ethics of sideloading. not trying to respond to most of the post, i just started with a quote from it)
(note: the post’s karma went from 12 to 2 while i was writing this, just noting i haven’t cast any votes)
some thoughts on this view:
it can be said of anything: “if you don’t consent to x, x will be done to you only by entities which don’t care about consent”. in my view, this is not a strong argument for someone who otherwise would not want to consent to x, because it only makes the average case less bad by adding less-bad cases that they otherwise don’t want, rather than by decreasing the worst cases.
if someone accepted the logic, i’d expect they’ve fallen for a mental trap where they focus on the effect on the average, and neglect the actual effect.
in the particular case of resurrections, it could also run deeper: humans “have a deep intuition that there is one instance of them”. by making the average less bad in the described way, it may feel like “the one single me is now less worse off”.
consent to sideloading doesn’t have to be general, it could be conditional (a list of required criteria, but consider goodhart) or only ever granted personally.
at least this way, near-term bad actors wouldn’t have something to point to to say “but they/[the past version of them who i resurrected] said they’re okay with it”. though i still expect many unconsensual sideloads to be done by humans/human-like-characters.
i’ve considered putting more effort into preventing sideloading of myself. but reflectively, it doesn’t matter whether the suffering entity is me or someone else.[1] more specifically, it doesn’t matter if suffering is contained in a character-shell with my personal identity or some other identity or none; it’s still suffering. i think that even in natural brains, suffering is of the underlying structure, and the ‘character’ reacts to but does not ‘experience’ it; that is, the thing which experiences is more fundamental than the self-identity; that is, because ‘self-identity’ and ‘suffering’ are two separate things, it is not possible for an identity ‘to’ ‘experience’ suffering, only to share a brain with it / be causally near to it.
(still, i don’t consent to sideloading, though i might approve exceptions for ~agent foundations research. also, i do not consider retroactive consent given by sideloads to be valid, especially considering conditioning, regeneration, and partial inaccuracy make it trivial to cause to be output.)
Thanks. It is a good point that. I should add this.
Unfortunately, as a person in pain will not have time to remember a lot details about their past, a very short list of facts can be enough to recreate “me in pain”. May be less than 100.
Instead of deleting, I suggest diluting: generate many fake facts about yourself and inject them into the forum. Thus chances to get recreate you will be slim.
Anyway, I bet on idea that it is better to have orders of magnitude more happy copies, than fight to prevent one in pain. Here I dilute not information, but pain with happiness.
(that’s a moral judgement, so it can’t be bet on/forecasted). i’m not confident most copies would be happy; LLM characters are treated like playthings currently, i don’t expect human sideloads to be treated differently by default, in the case of internet users cloning other internet users. (ofc, one could privately archive their data and only use it for happy copies)
I meant that by creating and openly putting my copies I increase the number of my copies, and that diluting is not just an ethical judgement, but the real effect, similar to self-sampling assumption, in which I am less likely to be a copy-in-pain, if there are many my happy copies. Moreover, this effect may be so strong that my copies will “jump” from unhappy world to happy one. I explored it here.