I’m, as are most, familiar with Google Trends. What I’m interested is something more analytical than Google Trends. Maybe Google Trends would be closer to what I am imagining if it displayed and detailed how individual trends in aggregate constitute some portion of a larger historical event(s) playing out. For example, that Tucker Carlson is trending now might be a component of multiple other, larger phenomena unfolding. Also, beyond Google Trend’s measure of normalized search interest, I would be interested in seeing the actual numbers across social networks / platforms by token or related tokens. Again, my phrasing here may be poor, but I feel that Google Trends misses some level of cohesiveness with the trends it measures (maybe stated as “some inadequacy on part of Google Trends to integrate multiple trend histories into the larger picture”). Thank you for your comment.
T431
[Question] Measures of Internet Virality and News Popularity
I asked it to give me a broad overview of measure theory. Then, I asked for it to provide me with a list of measure theory terms and their meanings. Then, I asked it to provide me some problems to solve. I haven’t entered an solutions yet, but upon doing so I would ask for it to evaluate my work.
Further on this last sentence, I have given it things I’ve written, including arguments, and have asked for it to play Devil’s Advocate or to help me improve my writing. I do not think I’ve been thorough in the examples I’ve given it, but its responses have been somewhat useful.
I imagine that many others have used GPT systems to help them evaluate and improve their writing, but, in my experience, I haven’t seen many people to use these systems to tutor them or keep track of their progress in learning something like measure theory.
I have (what may be) a simple question—please forgive my ignorance: Roughly speaking, how complex is this capability, i.e. writing Quines? Perhaps stated differently, how surprising is this feat? Thank you for posting about / bringing attention to this.
Strong agreement here. I find it unlikely that most of these details will still be concealed after 3 months or so, as it seems unlikely, combined, that no one will be able to infer some of these details or that there will be no leak.
Regarding the original thread, I do agree that OpenAI’s move to conceal the details of the model is a Good Thing, as this step is risk-reducing and creates / furthers a norm for safety in AI development that might be adopted elsewhere. Nonetheless, the information being concealed seems likely to become known soon, in my mind, for the general reasons I outlined in the previous paragraph.
Does anyone here have any granular takes what GPT-4′s multimodality might mean for the public’s adoption of LLMs and perception of AI development? Additionally, does anyone have any forecasts (1) for when this year (if at all) OpenAI will permit image output and (2) for when a GPT model will have video input & output capabilities?
...GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs)...
These masks are also exceedingly uncommon in my Northeastern US town + the surrounding area; I think I’ve seen fewer than 5 people wearing one since late 2020. None of them were unusually coloured, either. In my experience, most establishments where masks can be purchased don’t carry these pouch-masks. It would be surprising and funny to see a whole group of people will yellow duckbill masks. Also, thank you for teaching me a new word (anatine “of or belonging to the surface-feeding ducks of Anas and closely related genera”). I wish your daughter a hasty recovery.
For those who may not have seen and would like to make a prediction (on Metaculus; current uniform median community prediction is 15%)
Will WHO declare H5N1 a Public Health Emergency of International Concern before 2024?
So why should you dress nice, even given this challenge? Because dressing nice makes your vibes better and people treat you better and are more willing to accommodate your requests.
This is a compelling argument to me, as someone who also had a fuzzy belief that “dressing nicely was a type of bullshit signaling game” (though perhaps with less conviction than you had).
It was around the time (several years ago) that I saw someone dressed like me (pants tucked into the socks and shirt tucked into the pants) that I had the realization that I would probably benefit from dressing better.
This realization was compelling enough to stoke me into initial action, which took the form of testing out new clothing that had passed the rough vibe check of my family and friends, who dress well and seem to care a decent amount about how they dress, but was not strong enough to keep me trying out new clothing.
I found that all the clothing I was trying on was too physically uncomfortable for me. There was also a minor psychological component as a well that I can only describe as a feeling of mismatch between my self-perception and the expected perception people would have of the clothed object before me in the mirror.
As a result of these “failed” experiments, I opted to wear flannels and make sure that the color of my socks matched the color of my pants; to me, this intervention was enough to get me above a vague status threshold and did not require much effort. With very few exceptions, I have not deviated from this dress code.
I cannot recall if I observed a difference in how I was treated after following change, which occurred several years ago.
Thank you writing this post Gordon. After reading and bookmarking it, I think I am marginally more likely to again attempt to dress better in the near-term future.
For the person who strong downvoted this, it would be helpful to me if you also shared which facets of the idea you found inadequate; the 5 or so people I’ve talked to online have generally supported this idea and found it interesting. I would appreciate some transparency on exactly why you believe the idea is a waste of time or resources, since I want to avoid wasting either of those. Thanks you.
Great piece.
Note: small thank you for the link https://www.etymonline.com/word/patience; I’ve never seen this site but I will probably have a lot of fun with it.
Thank you for your input on this. The idea is to show people something like the following image [see below] and give a few words of background on it before asking for their thoughts. I agree that this part wouldn’t be too helpful for getting people’s takes on the future, but my thinking is that it might be nice to see some people’s reactions to such an image. Any more thoughts on the entire action sequence?

[Question] Value of Querying 100+ People About Humanity’s Future
[Question] Rough Sketch for Product to Enhance Citizen Participation in Politics
I understand its performance is likely high variance and that it misses the details.
My use with it is in structuring my own summaries. I can follow the video and fill in the missing pieces and correct the initial summary as I go along. I haven’t viewed it as a replacement for a human summarization.
Thank you for bringing my attention to this.
It seems quite useful, hence my strong upvote.
I will use it to get an outline of two ML Safety videos before summarizing them in more detail myself. I will put these summaries in a shortform, and will likely comment on this tool’s performance after watching the videos.
Is there a name for the discipline or practice of symbolically representing the claims and content in language (this may be part of Mathematical Logic, but I am not familiar enough with it to know)?
Practice: The people of this region (Z) typically prefer hiking in the mountains of the rainforest to walking in the busy streets (Y), given their love of the mountaintop scenery (X).
XYZ Output: Given their mountaintop scenery love (X), rainforest mountain hiking is preferred over walking in the busy streets (Y) by this region’s people (Z).
Thoughts, Notes: 10/14/0012022 (2)
Contents:
Track Record, Binary, Metaculus, 10/14/0012022
Quote: Universal Considerations [Forecasting]
Question: on measuring importance of forecasting questions
Please tell me how my writing and epistemics are inadequate.
1.
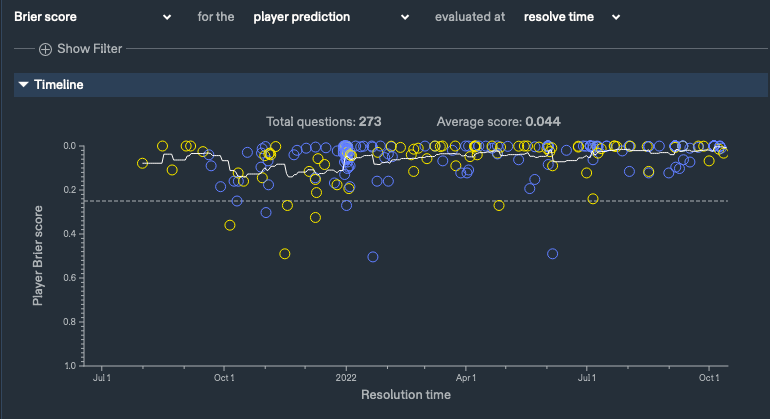
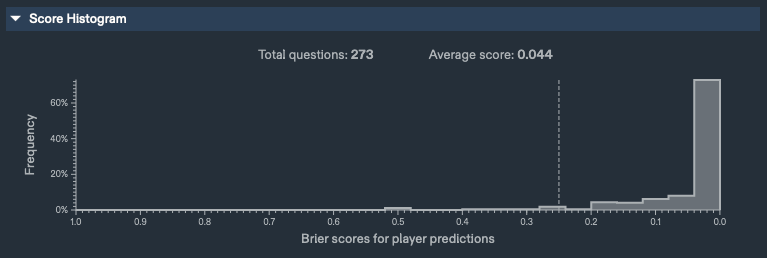
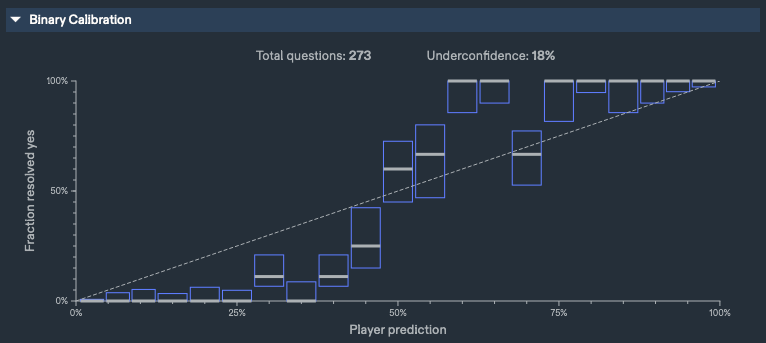
My Metaculus Track Record, Binary, [06/21/0012021 − 10/14/0012022]
2.
The Universal Considerations for forecasting in Chapter 2 of Francis X. Diebold’s book Forecasting in Economics, Business, Finance and Beyond:
(Forecast Object) What is the object that we want to forecast? Is it a time series, such as sales of a firm recorded over time, or an event, such as devaluation of a currency, or something else? Appropriate forecasting strategies depend on the nature of the object being forecast.
(Information Set) On what information will the forecast be based? In a time series environment, for example, are we forecasting one series, several, or thousands? And what is the quantity and quality of the data? Appropriate forecasting strategies depend on the information set, broadly interpreted to not only quantitative data but also expert opinion, judgment, and accumulated wisdom.
(Model Uncertainty and Improvement) Does our forecasting model match the true GDP? Of course not. One must never, ever, be so foolish as to be lulled into such a naive belief. All models are false: they are intentional abstractions of a much more complex reality. A model might be useful for certain purposes and poor for others. Models that once worked well may stop working well. One must continually diagnose and assess both empirical performance and consistency with theory. The key is to work continuously toward model improvement.
(Forecast Horizon) What is the forecast horizon of interest, and what determines it? Are we interested, for example, in forecasting one month ahead, one year ahead, or ten years ahead (called h-step-ahead fore- casts, in this case for h = 1, h = 12 and h = 120 months)? Appropriate forecasting strategies likely vary with the horizon.
(Structural Change) Are the approximations to reality that we use for forecasting (i.e., our models) stable over time? Generally not. Things can change for a variety of reasons, gradually or abruptly, with obviously important implications for forecasting. Hence we need methods of detecting and adapting to structural change.
(Forecast Statement) How will our forecasts be stated? If, for exam- ple, the object to be forecast is a time series, are we interested in a single “best guess” forecast, a “reasonable range” of possible future values that reflects the underlying uncertainty associated with the forecasting prob- lem, or a full probability distribution of possible future values? What are the associated costs and benefits?
(Forecast Presentation) How best to present forecasts? Except in the simplest cases, like a single h-step-ahead point forecast, graphical methods are valuable, not only for forecast presentation but also for forecast construction and evaluation.
(Decision Environment and Loss Function) What is the decision environment in which the forecast will be used? In particular, what decision will the forecast guide? How do we quantify what we mean by a “good” forecast, and in particular, the cost or loss associated with forecast errors of various signs and sizes?
(Model Complexity and the Parsimony Principle) What sorts of models, in terms of complexity, tend to do best for forecasting in business, finance, economics, and government? The phenomena that we model and forecast are often tremendously complex, but it does not necessarily follow that our forecasting models should be complex. Bigger forecasting models are not necessarily better, and indeed, all else equal, smaller models are generally preferable (the “parsimony principle”).
(Unobserved Components) In the leading time case of time series, have we successfully modeled trend? Seasonality? Cycles? Some series have all such components, and some not. They are driven by very different factors, and each should be given serious attention.
3.
Question: How should I measure the long-term civilizational importance of the subject of a forecasting question?
I’ve used the Metaculus API to collect my predictions on open, closed, and resolved questions.
I would like to organize these predictions; one way I want to do this is by the “civilizational importance” of the forecasting question’s content.
Right now, I’ve thought to given subjective ratings of importance on logarithmic scale, but want a more formal system of measurement.
Another idea for each question is to give every category a score of 0 (no relevance), 1 (relevance), or 2 (relevant and important). For example, if all of my categories “Biology, Astronomy, Space_Industry, and Sports”, then the question—Will SpaceX send people to Mars by 2030? - would have this dictionary {”Biology”:0, “Space_Industry”:2, “Astronomy”:1, “Sports”:0}. I’m unsure whether this system is helpful.
Does anyone have any thoughts for this?
Thank you for taking a look Martin Vlach.
For the latter comment, there is a typo. I meant:
Coverage of this topic is sparse relative to coverage of CC’s direct effects.
The idea is that the corpus of work on how climate change is harmful to civilization includes few detailed analyses of the mechanisms through which climate change leads to civilizational collapse but does includes many works on the direct effects of climate change.
For the former comment, I am not sure what you mean w.r.t “engender”.
Definition of engender
2 : to cause to exist or to develop : produce
“policies that have engendered controversy”
Thank you for this comment (sorry this Thank You was delayed; I came back here to add what I’ve added below, but realize that I hadn’t replied to you).
I came across this today: https://www.newsminimalist.com/
The Homepage:
This is another interesting use case of LLMs, this time for meaningful content sorting and tracking, and is helpful in a way different from how you utilized GPT-4 for my initial question. With some additional modification / development, perhaps LLMs can produce a site with all the features I indicated above, or at least something closer to them than https://www.newsminimalist.com/, which I view as a stepping stone. Anyway, I thought you might find the link / concept interesting!