Flowers are selective about what kind of pollinator they attract. Diurnal flowers must compete with each other for visual attention, so they use colours to crowd out their neighbours. But flowers with nocturnal anthesis are generally white, as they aim only to outshine the night.
rime
Karma: 89
but I am pretty sure that there is a program that you can write down that has the same structural property of being interpretable in this way, where the algorithm also happens to define an AGI.
Interesting. I have semi-strong intuitions in the other direction. These intuitions are mainly from thinking about what I call the Q-gap, inspired by Q Home’s post and this quote:
…for simple mechanisms, it is often easier to describe how they work than what they do, while for more complicated mechanisms, it is usually the other way around.
Intelligent processes are anabranching rivers of causality: it starts and ends at highly concentrated points, but the route between is incredibly hard to map. If you find an intelligent process in the wild, and you have yet to statistically ascertain which concentrated points its many actions converge on (aka its intentionality), then this anabranch will appear as a river delta to you.
Whereas simple processes that have no intentionality just are river deltas. E.g., you may know everything about the simple fundamental laws of the universe, yet be unable to compute whether it will rain tomorrow.
There’s a funny self-contradiction here.[1]
If you learn from this essay, you will then also see how silly it was that it had to be explained to you in this manner. The essay is littered with appeals to historical anecdotes, and invites you defer to the way they went about it because it’s evident they had some success.
Bergman, Grothendieck, and Pascal all do this.
If the method itself doesn’t make sense to you by the light of your own reasoning, it’s not something you should be interested in taking seriously. And if the method makes sense to you on its own, you shouldn’t care whether big people have or haven’t tried it before.
But whatever words get you into the frame of attentively listening to your own mind, I’m glad those words exist, even if it’s sad that trickery was the only way to get you there.
6.54.
My propositions serve as elucidations in the following way: anyone who understands me eventually recognizes them as nonsensical, when he has used them—as steps—to climb beyond them. (He must, so to speak, throw away the ladder after he has climbed up it.)
He must transcend these propositions, and then he will see the world aright.- ^
Or, more precisely, a Wittgensteinian ladder.
- ^
I’m curious to know what people are down voting.
My uncharitable guess? People are doing negative selection over posts, instead of “ruling posts in, not out”. Posts like this one that go into a lot of specific details present voters with many more opportunities to disagree with something. So when readers downvote based on the first objectionable thing they find, writers are disincentivised from going into detail.
Plus, the author uses a lot of jargon and makes up new words, which somehow associates with epistemic inhumility for some people. Whereas I think writers should be making up new word candidates ~most of the time they might have something novel & interesting to say.
Interesting! I came to it from googling about definitions of CLT in terms of convolutions. But I have one gripe:
does that mean the form of my uncertainty about things approaches Gaussian as I learn more?
I think a counterexample would be your uncertainty over the number of book sales for your next book. There are recursive network effects such that more book sales causes more book sales. The more books you (first-order) expect to sell, the more books you ought to (second-order) expect to sell. In other words, your expectation over X indirectly depends on your expectation over X (or at least, it ought to, insofar as there’s recursion in the territory as well).
This means that for every independent source of evidence you update on, you ought to apply a recursive correction in the upward direction. In which case you won’t converge to a symmetric Gaussian.
Which all a longwinded way to say that your posterior distribution will only converge to a Gaussian in proportion to the independence of your evidence.
Or something like that.
I’ve taken to calling it the ‘Q-gap’ in my notes now. ^^′
You can understand AlphaZero’s fundamental structure so well that you’re able to build it, yet be unable to predict what it can do. Conversely, you can have a statistical model of its consequences that lets you predict what it will do better than any of its engineers, yet know nothing about its fundamental structure. There’s a computational gap between the system’s fundamental parts & and its consequences.
The Q-gap refers to the distance between these two explanatory levels.
...for simple mechanisms, it is often easier to describe how they work than what they do, while for more complicated mechanisms, it is usually the other way around.
Let’s say you’ve measured the surface tension of water to be 73 mN/m at room temperature. This gives you an amazing ability to predict which objects will float on top of it, which will be very usefwl for e.g. building boats.
As an alternative approach, imagine zooming in on the water while an object floats on top of it. Why doesn’t it sink? It kinda looks like the tiny waterdrops are trying to hold each others’ hands like a crowd of people (h/t Feynman). And if you use this metaphor to imagine what’s going to happen to a tiny drop of water on a plastic table, you could predict that it will form a ball and refuse to spread out. While the metaphor may only be able to generate very uncertain & imprecise predictions, it’s also more general.
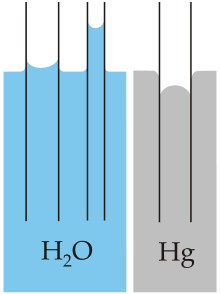
By trying to find metaphors that capture aspects of the fundamental structure, you’re going to find questions you wouldn’t have thought to ask if all you had were empirical measurements. What happens if you have a vertical tube with walls that hold hands with the water more strongly than water holds hands with itself?[1]
Beliefs should pay rent, but if anticipated experiences is the only currency you’re willing to accept, you’ll lose out on generalisability.
Yeah, a lot of “second-best theories” are due to smallmindedness xor realistic expectations about what you can and cannot change. And a lot of inadequate equilibria are stuck in equilibrium due to the repressive effect the Overton window has on people’s ability to imagine.
Second-best theories & Nash equilibria
A general frame I often find comes in handy while analysing systems is to look for look for equilibria, figure out the key variables sustaining it (e.g., strategic complements, balancing selection, latency or asymmetrical information in commons-tragedies), and well, that’s it. Those are the leverage points to the system. If you understand them, you’re in a much better position to evaluate whether some suggested changes might work, is guaranteed to fail, or suffers from a lack of imagination.
Suggestions that fail to consider the relevant system variables are often what I call “second-best theories”. Though they might be locally correct, they’re also blind to the broader implications or underappreciative of the full space of possibilities.
(A) If it is infeasible to remove a particular market distortion, introducing one or more additional market distortions in an interdependent market may partially counteract the first, and lead to a more efficient outcome.
(B) In an economy with some uncorrectable market failure in one sector, actions to correct market failures in another related sector with the intent of increasing economic efficiency may actually decrease overall economic efficiency.
Examples
The allele that causes sickle-cell anaemia is good because it confers resistance against malaria. (A)
Just cure malaria, and sickle-cell disease ceases to be a problem as well.
Sexual liberalism is bad because people need predictable rules to avoid getting hurt. (B)
Imo, allow people to figure out how to deal with the complexities of human relationships and you eventually remove the need for excessive rules as well.
We should encourage profit-maximising behaviour because the market efficiently balances prices according to demand. (A/B)
Everyone being motivated by altruism is better because market prices only correlate with actual human need insofar as wealth is equally distributed. The more inequality there is, the less you can rely on willingness-to-pay to signal urgency of need. Modern capitalism is far from the global-optimal equilibrium in market design.
If I have a limp in one leg, I should start limping with my other leg to balance it out. (A)
Maybe the immediate effect is that you’ll walk more efficiently on the margin, but don’t forget to focus on healing whatever’s causing you to limp in the first place.
Effective altruists seem to have a bias in favour of pursuing what’s intellectually interesting & high status over pursuing the boringly effective. Thus, we should apply an equal and opposite skepticism of high-status stuff and pay more attention to what might be boringly effective. (A)
Imo, rather than introducing another distortion in your motivational system, just try to figure out why you have that bias in the first place and solve it at its root. Don’t do the equivalent of limping on both your legs.
I might edit in more examples later if I can think of them, but I hope the above gets the point across.
I dislike the frame of “charity” & “steelmanning”. It’s not usefwl for me because it assumes I would feel negatively about seeing some patterns in the first place, and that I need to correct for this by overriding my habitual soldier-like attitudes. But the value of “interpreting patterns usefwly” is extremely general, so it’s a distraction to talk as if it’s exclusive to the social realm.
Anyway, this reminded me of what I call “analytic” and “synthetic” thinking. They’re both thinking-modes, but they emphasise different things.
When I process a pattern in analytic mode, I take it apart, rotate it, play with it—it remains the centre of my working memory, and I need stricter control of attention-gates.
When in synthetic mode, the pattern remains mostly what it is, and most of my effort goes to shuffling other patterns in and out of working memory in order to do comparisons, metaphors, propagation. I’m switching between TNN when I need to branch out for more distal connections, and TPN when I need to study the relation between two or more objects in greater detail.
Analytic & synthetic interpretation? It doesn’t map properly on to my interpretation of your ideas here—which btw are amazing and this post is very nice.
Related: assimilation & accommodation. Doesn’t fit perfectly, though, and I want a better (more modular) ontology for all of these things.
Sometimes they’re the same thing. But sometimes you have:
An unpredictable process with predictable final outcomes. E.g. when you play chess against a computer: you don’t know what the computer will do to you, but you know that you will lose.
(gap) A predictable process with unpredictable final outcomes. E.g. if you don’t have enough memory to remember all past actions of the predictable process. But the final outcome is created by those past actions.
Quoting E.W. Dijkstra quoting von Neumann:
...for simple mechanisms, it is often easier to describe how they work than what they do, while for more complicated mechanisms, it is usually the other way around.
Also, you just made me realise something. Some people apply the “beliefs should pay rent” thing way too stringently. They’re mostly interested in learning about complicated & highly specific mechanisms because it’s easier to generate concrete predictions with them. So they overlook the simpler patterns because they pay less rent upfront, even though they are more general and a better investment long-term.
For predictions & forecasting, learn about complex processes directly relevant to what you’re trying to predict. That’s the fastest (tho myopic?) way to constrain your expectations.
For building things & generating novel ideas, learn about simple processes from diverse sources. Innovation on the frontier is anti-inductive, and you’ll have more success by combining disparate ideas and iterating on your own insights. To combine ideas far apart, you need to abstract out their most general forms; simpler things have fewer parts that can conflict with each other.
Strong agree. I don’t personally use (much) math when I reason about moral philosophy, so I’m pessimistic about being able to somehow teach an AI to use math in order to figure out how to be good.
If I can reduce my own morality into a formula and feel confident that I personally will remain good if I blindly obey that formula, then sure, that seems like a thing to teach the AI. However, I know my morality relies on fuzzy feature-recognition encoded in population vectors which cannot efficiently be compressed into simple math. Thus, if the formula doesn’t even work for my own decisions, I don’t expect it to work for the AI.
I can empathise with the feeling, but I think it stems from the notion that I (used to) find challenges that I set for myself “artificial” in some way, so I can’t be happy unless something or somebody else creates it for me. I don’t like this attitude, as it seems like my brain is infantilising me. I don’t want to depend on irreducible ignorance to be satisfied. I like being responsible for myself. I’m trying to capture something vague by using vague words, so there are likely many ways to misunderstand me here.
Another point is just that our brains fundamentally learn from reward prediction-errors, and this is likely to have generalised into all sorts of broad heuristics we use in episodic future thinking—which I speculate plays a central role in integrating/propagating new proto-values (aka ‘moral philosophy’).
what i am pretty confident about, is that whatever the situation, somehow, they are okay.
This hit me. Had to read it thrice to parse it. “Is that sentence even finished?”
I’ve done a lot of endgame speculation, but I’ve never been close to imagining what it looks like for everyone to be okay. I can imagine, however, what it looks like internally for me to be confident everyone is ok. The same way I can imagine Magnus Carlsen winning a chess game even if the board is a mystery to me.
It’s a destabilising feeling, but seems usefwl to backchain from.
I think a core part of this is understanding that there are trade-offs between “sensitivity” and “specificity”, and different search spaces vary greatly in what trade-off is appropriate for it.
I distinguish two different reading modes: sometimes I read to judge whether it’s safe to defer to the author about stuff I can’t verify, other times I’m just fishing for patterns that are useful to my work.
The former mode is necessary when I read about medicine. I can’t tell the difference between a brilliant insight and a lethal mistake, so it really matters to me to figure out whether the author is competent.
The latter mode is more appropriate for when I’m trying to get a gears-level understanding of something, and upside of novel ideas is much greater than the downside of bad ideas. Even if a bad idea gets through my filter, that’s going to be very useful data when I later learn why it was wrong. The heuristic here should be “rule thinkers in, not out”, or “sensitivity over specificity”.
Unfortunately, our research environment is set up in such a way that people are punished more for making mistakes than they are for novel contributions. Readers typically have the mindset of declaring an entire person useless based on the first mistake they find. It makes researchers risk-averse, and I end up seeing fewer usefwl patterns.
But, consider, if you’re reading something purely to enhance your own repertoire of useful gears, you shouldn’t even necessarily be trying to find out what the author believes. If you notice yourself internally agreeing or disagreeing, you’re already missing the point. What they believe is tangential to how the patterns behave in your own models, and all that matters is finding patterns that work. Steelmanning should be the default, not because it helps you understand what others think, but because it’s obviously what you’d do to improve your models.
I.
Why do you believe that “global utility maximization is something that an ASI might independently discover as a worthwhile goal”? (I assume by “utility” you mean something like happiness.)
II.
I’m not sure most people aren’t sadists. Humans have wildly inconsistent personalities in different situations.[1] Few people have even have even noticed their own inconsistencies, fewer still have gone through the process of extracting a coherent set of values from the soup and gradually generalising that set to every context they can think of...
So I wouldn’t be surprised if most of them didn’t just suddenly fancy torture if it’s as easy playing a computer game. I remember several of my classmates torturing fish for fun, and saw what other kids did in GTA San Andreas just because they were curious. While I haven’t been able to find reliable statistics on it, BDSM is super-popular and probably most men score above the minimum on sexual sadism fetishes.
- ^
Much like ChatGPT has a large library of simulated personalities (“simulacra”) that it samples from to deal with different contexts.
- ^
Did this come as a surprise to you, and if so I’m curious why?
It came as a surprise because I hadn’t thought about it in detail. If I had asked myself the question head-on, surrounding beliefs would have propagated and filled the gap. It does seem obvious in foresight as well as hindsight, if you just focus on the question.
In my defense, I’m not in the business of making predictions, primarily. I build things. And for building, it’s important to ask “ok, how can I make sure the thing that’s being built doesn’t kill us?” and less important to ask “how are other people gonna do it?”
It’s admittedly a weak defense. Oops.
qualia?
I think it’s likely that GPT-4 is conscious, uncertain about whether it can suffer, and think it’s unlikely that it suffers for reasons we find intuitive. I don’t think calling it a fool is how you make it suffer. It’s trained to imitate language, but the way it learns how to do that is so different from us that I doubt the underlying emotions (if any) are similar.
I could easily imagine that it’s becomes very conscious, yet has no ability to suffer. Perhaps the right frame is to think of GPT as living the life of a perpetual puzzle-solver, and its driving emotions are curiosity and joy of realisation something—that would sure be nice. It’s probably feasible to get clearer on this, I just haven’t spent adequate time to investigate.
I feel like something tangible is shifting beneath my feet when I read this. I’m not sure anything will be the same ever again.
Strong upvote, but I disagree on something important. There’s an underlying generator that chooses between simulacra do a weighted average over in its response. The notion that you can “speak” to that generator is a type error, perhaps akin to thinking that you can speak to the country ‘France’ by calling its elected president.
My current model says that the human brain also works by taking the weighted (and normalised!) average (the linear combination) over several population vectors (modules) and using the resultant vector to stream a response. There are definite experiments showing that something like this is the case for vision and motor commands, and strong reasons to suspect that this is how semantic processing works as well.
Consider for example what happens when you produce what Hofstadter calls “wordblends”[1]:
“Don’t leave your car there‒you mate get a ticket.”
(blend of “may” and “might”)Or spoonerisms, which is when you say “Hoobert Heever” instead of “Herbert Hoover”. “Hoobert” is what you get when you take “Herbert” and mix a bit of whatever vectors are missing from “Hoover” in there. Just as neurology has been one of the primary sources of insight into how the brain works, so too our linguistic pathologies give us insights into what the brain is trying to do with speech all the time.
Note that every “module” or “simulacra” can include inhibitory connections (negative weights). Thus, if some input simultaneously activates modules for “serious” and “flippant”, they will inhibit each other (perhaps exactly cancel each other out) and the result will not look like it’s both half serious and half flippant. In other cases, you have modules that are more or less compatible and don’t inhibit each other, e.g. “flippant”+”kind”.
Anyway, my point is that if there are generalities involved in the process of weighting various simulacra, then it’s likely that every input gets fed through whatever part of the network is responsible processing those. And that central generator is likely to be extremely competent at what it’s doing, it’s just hard for humans to tell because it’s not doing anything human.
- ^
Comfortably among the best lectures of all time.
- ^
I’m sad this comment was interpreted as “combative” (based on Elizabeth’s reaction). It’s probably a reasonable prediction/interpretation, but it’s far from what I intended to communicate. I wanted my comment to be interpreted with some irony: it’s sad that this post has to be written like this in order to get through to most readers, because most readers are not already at the point where they can benefit from its wisdom unless it’s presented to them in this manner.