Four Phases of AGI
AGI is not discrete, and different phases lead to different opportunities, risks, and strategies
“How long until AGI? I’d say −1 years from now.”
“Considering the worst-case outcomes of AGI, I’m most concerned about the effect on jobs.”
“AGI will be like corporations, so we will control it like corporations.”
“AGI will be millions of times smarter than us and take over control with methods we can’t comprehend.”
These kinds of statements are all over AI discussions. While these statements are all about “artificial general intelligence” (AGI)—meaning AI systems that can perform as well or better than humans on a wide range of cognitive tasks—they have wildly different assumptions and implications. You could decide that some of these takes are ridiculous—that one particular framing of AGI is “correct” and the others “wrong.” People often decide this, leading to unproductive fights.
But what may actually be happening is that different people have valid reasons for believing these different takes. They are simply referring to different concepts—AGI is ambiguous. To further complicate matters, AGI is broad: “as well or better than humans” is a wide range with no upper bound, so the term “AGI” is used for AI systems spanning from advanced chatbots to incomprehensibly superhuman intelligence.
This post lays out a particular framework for conceptualizing different levels of AGI. I aim for it to be particularly useful to non-technical decision-makers who may need to deal with policy and governance issues with respect to all the above perspectives.
Four Phases
One way we can think about the progression of AGI is to split it into four separate phases—Below-human AGI (BAGI), Human-level AGI (HAGI), Moderately-superhuman AGI (MAGI), and Superintelligent AGI (SAGI). Figure 1 conceptualizes these phase transitions as general capabilities (y-axis) advances with increasing time and AI investment (x-axis):
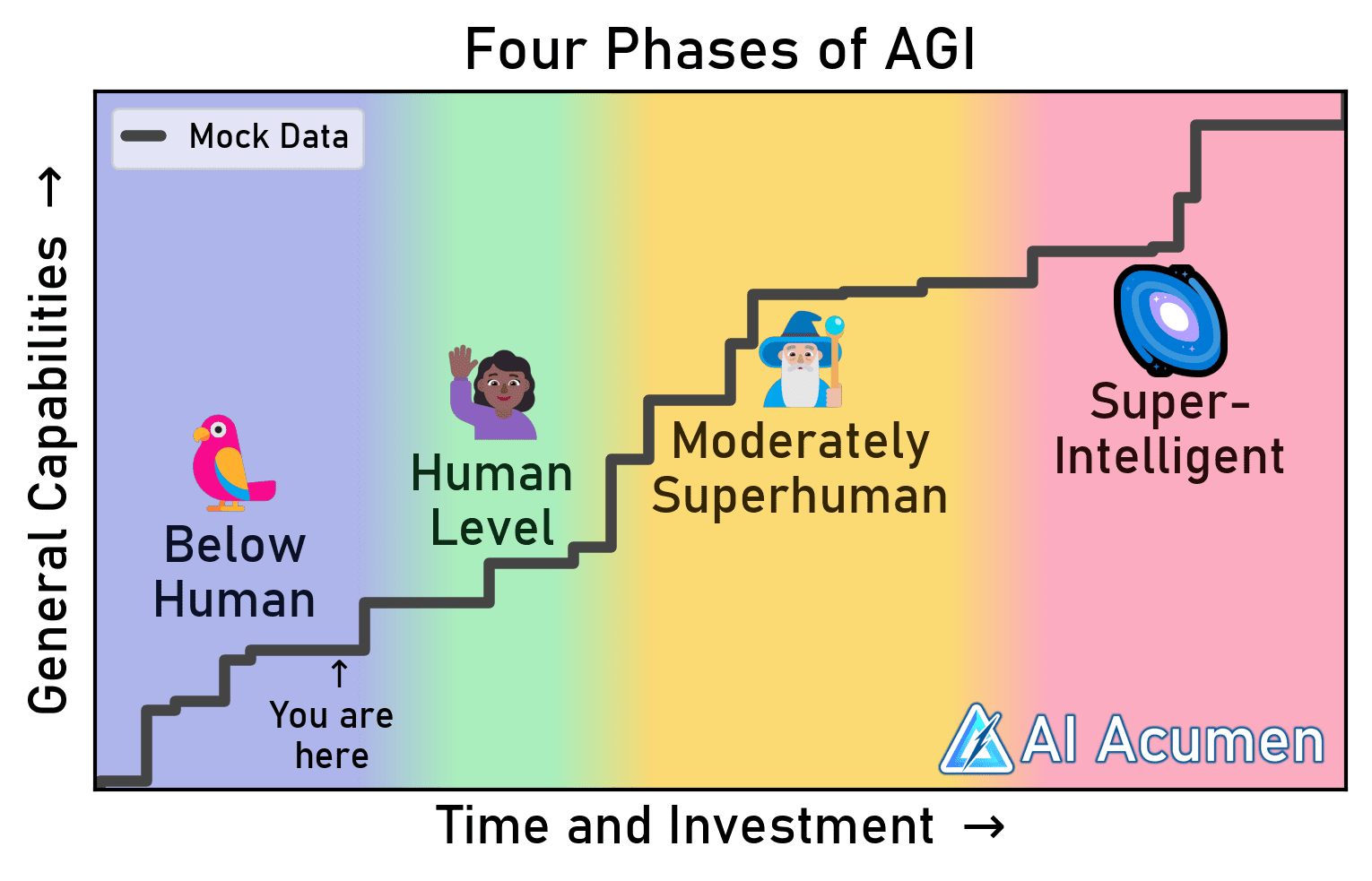
Figure 1: Conceptual illustration of the Four Phases of AGI using mock data. Plot code is here.
By splitting AGI into these Four Phases, we can fix much of the problem where people say “AGI” but mean systems of vastly different levels of capability. But more usefully, we can identify better AI governance and safety interventions to target different risks emerging at each capability level. I’ll first go into more depth on how to think about each of these phases and what risks they entail, and then I’ll talk about some of the general implications of this framing for AI strategy. If you get confused about the abbreviations, note that the letters go up as the phases progress (B < H < M < S).
🦜BAGI: Below-human Artificial General Intelligence—Current AI Systems
“Given the breadth and depth of GPT-4’s capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system.”
- Bubeck et al. (2023)
The first phase is below-human AGI systems (BAGI). As the name suggests, BAGI systems are generally capable across many tasks but nonetheless tend to be below human level on average. The clearest examples of these systems might be current-generation large language models (LLMs) and the AI chatbot apps they are increasingly deployed in, like ChatGPT.

Figure 2: The ChatGPT website on a phone.
Clearly, these kinds of systems satisfy some properties of AGI: They do pretty well at a wide range of interesting tasks, like translating between most popular languages, creating clever poetry, writing working software programs, or serving as personalized companions. It’s no wonder, then, that many have been pointing at these LLM systems and stating AGI Is Already Here.
But they also don’t seem to quite work yet. Autonomous AI agents aren’t yet able to solve long-range tasks, language models are not very robust to adversaries, and AI broadly has not yet brought in the large return on investment many have been betting on. Consequently, the BAGI phase is also the phase of AI skepticism, with many calling these models “stochastic parrots.”
Most of the risks of BAGI are described by the AI fairness, accountability, transparency, and ethics (FATE) community, such as perpetuating harmful biases or false information in the training data or outputting toxic language. Additionally, BAGI systems may aid in harmful misuse for the likes of disinformation campaigns, personalized fraud, or information used to build weapons.
🙋🏾♀️HAGI: Human-level Artificial General Intelligence—As Good as You or Me
“Well if you can’t tell, does it matter?”
- Westworld (2016)
Eventually (and possibly quite soon), those AI systems could start “working” for important tasks. That is the point I call Human-level AGI (HAGI)—when AI systems are able to carry out a wide range, but not necessarily all, of the valuable tasks that humans normally do. This is similar to the definitions of High Level Machine Intelligence (HLMI) or Human-Level AI that AI Impacts has used in its Expert Surveys on Progress in AI.
Thinking intuitively about HAGI is not too hard, as HAGI seems to be what most people think of when talking about AGI. This is partially the case because science fiction AI systems are often at the HAGI level: as capable as human characters, but not a whole lot more.

Figure 3: C-3PO (Anthony Daniels) in Star Wars (1977).
Of course, unlike popular depictions in science fiction, HAGI systems do not necessarily need to be embodied androids. Instead, they could operate as disembodied digital intelligences interacting with the world via computer systems—remote work in the wake of COVID-19 has shown that humans can generate plenty of economic value this way. The first HAGI systems are more likely to be disembodied AI agents in this way because robotics has historically lagged behind reasoning and language in AI (though robotics might be catching up).
HAGI is also a more relatable level because it is the goal of most AGI-building efforts. For example, some kind of HAGI system would likely satisfy OpenAI’s mission: “to ensure that artificial general intelligence (AGI)—by which we mean highly autonomous systems that outperform humans at most economically valuable work—benefits all of humanity.”
As the optimistic part of that mission implies, HAGI could bring many benefits. Most directly, if you can deploy human-level AI systems at a fraction of the cost of humans, then given enough investment, you may be able to rapidly increase the effective human-level workforce, leading to more work being done, a faster-growing economy, and subsequent gains across healthcare, education, scientific discovery, and more. The effects would also be felt at the individual level: HAGI systems could become common as personalized assistants, therapists, tutors, and perhaps most commonly, companions.
But like other transformative technologies, HAGI also brings many risks. AI systems that can outcompete human workers will obviously lead to some human job displacement, and it’s an open question whether they’ll create many more new jobs like previous technological revolutions have. If not and BAGI systems become widespread, then humanity could become quite dependent on AI workers, at least increasing our vulnerability to accidents from overreliance on AI and potentially leading to human disempowerment or enfeeblement. HAGI is also where power concentration could become serious due to the enormous wealth created by a rapid HAGI deployment—imagine a corporation or government doubling its effective workforce in a matter of weeks! Last, some HAGI systems could be capable of automating AI development itself, leading to recursive self-improvement and a rapid progression of AI capabilities beyond the HAGI regime.
🧙🏼♂️MAGI: Moderately-superhuman Artificial General Intelligence—Pretty Magical
“Any sufficiently advanced technology is indistinguishable from magic.”
- Arthur C. Clarke
Assuming human-level intelligence is not the maximum level of intelligence in our universe, then we may soon thereafter see AI systems that clearly perform beyond the human level. I call this third phase Moderately-superhuman AGI (MAGI).
The best analogy for MAGI systems is a witch or wizard: Someone who might generally look at talk like a human upon first interaction, but who can also actually do magic and is clearly more capable than normal people.

Figure 4: The Wizard Gandalf (Sir Ian McKellen) in The Lord of the Rings: The Fellowship of the Ring (2001).
MAGI systems will probably not actually do magic—though it might seem that way to us because they are capable of certain acts that are very difficult for us to understand. They may be able to rapidly solve scientific problems previously thought impossible, accurately predict the future of complex systems, channel the ultimate charisma to persuade almost anyone, or effortlessly create the most beautifully compelling works of art. The important boundary between HAGI and MAGI is when we start consistently saying, “Woah, how did that AI do that? I don’t know any human who could have done that!”
Alternatively, you could think of MAGI systems as consistent draws from the most clever individuals throughout history—imagine AI systems making Einstein-level discoveries on the regular—or like the most successful results of the collective intelligence of humanity—human society has traveled to other planets, eradicated smallpox, and built great Wonders of the World. In a world of MAGI, such wondrous advancements that are far too daunting for individual humans to pursue may instead become commonplace.
However, there are limits to those two analogies: geniuses and collections of people are still bounded by the outer limits of humanity in several ways. While MAGI may be close to the human level initially, this phase of AGI faces no such bounds and could eventually complete tasks that are not just formidable for humans to do, but even to comprehend. As such, I prefer the magic analogy for going further (and so you can remember “MAGI” → “mage”/”magic”).
It would certainly benefit the world to have a lot of good magic around. MAGI systems may be able to suddenly find cures for elusive diseases, negotiate new global partnerships to eradicate many forms of poverty, and build society’s resilience to other emerging threats.
Simultaneously, MAGI systems introduce qualitatively new risks, especially by possessing capabilities beyond humanity’s level of understanding. Most significantly, MAGI systems pose substantial loss of control risk, as they may be so capable of manipulating humans, exploiting security vulnerabilities, and autonomously securing resources that it is difficult to keep them in check. But difficult does not mean impossible, and humanity may still have a fighting chance against rogue MAGI systems.
🌌SAGI: Superintelligent Artificial General Intelligence—We Stand No Chance
“A cognitive system with sufficiently high cognitive powers, given any medium-bandwidth channel of causal influence, will not find it difficult to bootstrap to overpowering capabilities independent of human infrastructure.”
- Eliezer Yudkowsky
Unfortunately, there comes a point where humanity no longer has a fighting chance against a too-superhuman AI system. I call this final phase Superintelligent AGI (SAGI). We can choose to set the SAGI boundary using this power balance: in a global power struggle between humanity and AI, humanity dominates Below-human and likely Human-level systems, it’s a tossup against Moderately-superhuman systems, and AI can dominate humanity once it has reached Superintelligence.

Figure 5: “I fear no man” meme with Eliezer Yudkowsky and superintelligence.
This definition based on power dynamics carries three implications for SAGI:
First, the concrete risks that SAGI will pose to humanity are quite hard to predict despite knowing the general outcome of AI dominance, similar to how it’s easy to predict a chess grandmaster would beat a novice but not to know with which moves they’ll use. Some have postulated new technological innovations SAGI could unlock that would grant it a decisive strategic advantage—such as atomically precise manufacturing or other forms of nanotechnology—but these are just guesses, and SAGI may be capable of developing strategic technologies that not even our science fiction has yet to conceive.
Second, since humanity doesn’t stand a chance in a one-to-one fight against SAGI by definition, the way to mitigate its risks is to not enter a fight with it. This is part of the reason why many AI safety researchers have been advocating for progress on AI alignment for several decades: a strong solution to the alignment problem could ensure that superintelligence systems benefit rather than compete with humanity, allowing us to reap their dramatic powers for good.
Finally, and speaking of benefits, if SAGI systems can develop decisive strategic advantages over all of 21st-century humanity, they can likely also develop immensely positive technologies to improve society. This is where many techno-optimists derive much of their hope, as it seems possible in principle for such advanced AI systems to develop cures to almost all diseases, plentiful clean energy sources, ideal systems of democratic governance, and many more societal advancements that would significantly uplift the world. But again, these benefits may only be securable if humanity can develop solutions such as AI alignment that would ensure these decisively superhuman systems don’t simply supersede us.
Four Things to Know
Now you have a sense of the Four Phases—one possible way to think about the progression of AGI. Here’s that earlier figure again for your reference:
Figure 1, repeated.
Of course, this isn’t the only way to think about AGI progression. Others have contributed analogous conceptual frameworks, including:
Google DeepMind’s Levels of AGI: Operationalizing Progress on the Path to AGI, which is quite similar to this but might split HAGI into “Competent” and “Expert” levels,
OpenAI’s leaked Five Levels of AGI for measuring progress towards its mission,
Anthropic’s AI Safety Levels from its Responsible Scaling Policy, which may not extend all the way to SAGI,
The Artificial General Intelligence (AGI) vs Artificial Super Intelligence (ASI) distinction, which roughly maps to HAGI and SAGI, respectively, but fails to identify below human-level systems or systems between AGI and ASI,
Transformative AI (TAI) is a bit fuzzy since it measures impacts rather than capabilities, but HAGI might count as TAI if it can multiply the effective workforce several times over.
These different frameworks accomplish some similar things: the core realization is that AGI is not a discrete point, that we can decompose the path to increasingly capable AGI systems into different stages, and that these stages imply different benefits, risks, and risk management strategies.
But if you’ll humor these Four Phases, in particular, I’d like to discuss four less obvious implications that are useful to know.
Blurry, Variable-Width Bands
First, these Phases are general “bands” of intelligence, not clearly delineated points. That implies a couple of things:
These bands are blurry, and it might not be immediately clear when we’ve transitioned from one to another.
They can also have considerably variable widths. Like different kinds of electromagnetic radiation, some bands may be much wider or narrower than others.
Figure 6: The range of light visible to humans is a small sliver of the full electromagnetic spectrum. The range of human-level AGI systems might be similarly small.
To complicate the blurriness point, different AI capabilities may not all advance at the same rates, so while a system may generally occupy one band, it may have some capabilities that seem much better or worse than we’d expect from that band. For example, current AI systems are already narrowly superhuman at some skills such as knowing more information or reading documents more quickly than any human would be able to.
Early Stopping Separates AI Worldviews
Second, if we assume AGI progress will stop before certain phases, then it makes sense to prioritize the concerns of the preceding levels, leading to some of the different popular AI worldviews:
Stop before HAGI: AI Skeptic. If we think AI systems won’t reach human-level capabilities, then we might focus on algorithmic fairness, training data bias, and limited misuse risks from models around the current capability level rather than worrying much about catastrophic harms.
Stop before MAGI: Human Plateau. We might think AI systems won’t be much more capable than humans, either due to an anthropocentric bias of thinking that we are at the “end” of evolution, or due to limited imagination for what could surpass humanity. This might lead to the view that the worst-case AI risk is job displacement. I suspect many non-technical policymakers imagine this as the ceiling of AGI.
Stop before SAGI: Bounded Superhuman-ness. If we think AI advancement will peter out above the human level but not at a high enough point where AI systems can decisively win against humans, then we might espouse the “AGI will be like corporations, so we will control it like corporations” view and believe that humanity will always have a significant chance at prevailing over even misaligned AI systems. In my experience, this stopping point is the least commonly believed.
All the way to SAGI: AI Doomer. Finally, if we think AI progress can continue well past the human level, then it’s inevitable that AI capabilities will reach a point where AI can obtain a decisive strategic advantage over humanity, including through means that humanity has yet to conceive of. This implies that we will ultimately need to solve some kind of AI alignment problem if we wish to deploy such powerful systems, but the current rate of AI advancement and lack of alignment progress contributes to many people in this regime believing humanity may be on a path to doom.
Phase Distribution Separates AI Takeoff Views
To expand a bit on the previous two sections, the distribution of the widths of these blurry bands of intelligence also leads to different views about AI takeoff speeds.
For example, a “fast takeoff” might just mean the MAGI regime is comparatively short, such that there is a small window of time between when AI systems can accomplish a wide range of human-level tasks (HAGI) and when they are sufficiently powerful to easily overwhelm humanity if misaligned (SAGI). And vice versa for “slow takeoff” implying a long window of HAGI.
Under this lens, we can also better understand perspectives such as why some at OpenAI believe short timelines and slow takeoff is the safest regime: Short timelines mean we reach HAGI sooner so society can start understanding its opportunities and benefits. Reaching HAGI sooner may in turn create slower takeoff speeds by pulling forward the start of the MAGI regime, especially elongating it if the following SAGI regime is bottlenecked by constraints such as computing power or electricity.
One short-timeline, moderate takeoff view I personally think could be possible is BAGI starting with GPT-3’s release in 2020 until 2025, HAGI from 2025-2028, MAGI from 2028-2035, and SAGI from 2035 and beyond. However, this view is only assuming AI investment and development continue at current rates unchecked by external bottlenecks.
We Can Affect the Lengths of Each Phase
Fourth, unlike the electromagnetic spectrum, we can change how these phases play out, such as by shifting the timing and scaling the duration of each phase.
Society may affect the phase lengths by following natural incentives. For example, we’ll probably want to keep HAGI systems around for quite a while—human-level AI systems more easily plug into our existing human workforce, and they’re more relatable and understandable.
But we may also intentionally choose to affect these phases to benefit society. AI accelerationists may want to shift up the timelines for all of these phases to sooner address the world’s problems, while Pause AI advocates may want to delay the phases to buy more time for technical AI safety and AI governance developments. And there are many other, hybrid views, such as the aforementioned OpenAI view that it might be best to pull forward the initial exposure to HAGI but lengthen the time we have in HAGI and MAGI to prolong takeoff speeds.
The key realization is that as a collective society, we can change the timing of the phases of AGI, and the timing may be very important to safely distributing the benefits of AGI throughout the world.
Towards Moderately-Superhuman AGI Governance
I’ll close by noting that personally, I’m most interested in the Moderately-Superhuman AGI phase. Not only is MAGI the least publicly discussed of these Four Phases, but there are also many reasons to think it could be one of the more important phases for AI governance:
The Time is Right: If HAGI is a relatively narrow band of general intelligence and scale is all you need (at first), then we may find ourselves in the MAGI regime pretty soon. AI governance takes a while to put in place, so while it may be too late to build up ideal BAGI or HAGI governance from a blank slate, the time may be right to plan for ideal MAGI governance.
The HAGI-SAGI Gap May Naturally be Wide: If we develop human-level AGI systems soon, we may still have a considerable gap before AI systems can beat all of humanity. As a simple heuristic, large corporations and governments employ hundreds of thousands to tens of millions of people, so there may be many orders of magnitude between AI systems that can outcompete individual people (HAGI) and AI systems that can outcompete our collective society (SAGI).
Figure 7: The exponential growth of computing from Ray Kurzweil’s The Age of Spiritual Machines (1999). Kurzweil predicted a large gap between the computer performance needed to match one human brain (2023) and all human brains (2050).
Resource Bottlenecks May Extend MAGI: Sources indicate we may soon run out of certain resources needed to train increasingly advanced AGI systems, such as data, hardware, or electricity. If these resource bottlenecks are hit after human-level systems an into the MAGI phase (I personally think that’s pretty likely), then the MAGI phase may be further extended due to the ensuing delay in continued scaling.
MAGI Control is Not Guaranteed, But We Have a Chance: If these superhuman AI systems are like corporations, then I think there’s some hope to the view that we can regulate them like we regulate corporations and turn out all right. As they become more like magic wizards, however, the comparison to human-run corporations breaks down. Humanity no longer clearly wins in conflicts with misaligned MAGI systems, but we still have hope—wizards can be defeated.

Figure 8: Gandalf defeated in The Hobbit: The Desolation of Smaug (2013).
Speaking of, I’ve heard of a few ideas that inform a broad plan for managing the risks and increasing the benefits of MAGI systems in the presence of shorter AI timelines and slow AI alignment progress:
Define g(doom) as the level of general AI capabilities at which humanity is pretty screwed if we deploy a misaligned AI system.
At first, don’t build AI systems more capable than g(doom) (this implies a pause, but a good deal beyond current AI).
Do build quite powerful HAGI systems below g(doom) and deploy them to improve society.
Invest in narrow safety and control techniques that enable us to continually push out the g(doom) threshold.
Eventually make considerable alignment progress, allowing for safely deploying AI systems beyond g(doom).
This plan then yields many unsolved subproblems:
Measuring general intelligence beyond the human regime.
Understanding the dangers associated with different superhuman capabilities.
Reliably predicting downstream capabilities before training.
Societal questions about setting the right risk thresholds to pause HAGI at.
Reaping the benefits of slightly-magical HAGI systems.
Democratically steering HAGI and equitably distributing those benefits through society.
AI Control, robust unlearning, and other means to increase safety for potentially misaligned AI systems below g(doom).
Solving AI alignment, as has continually been a struggle.
How to decide to un-pause once we’re more confident in our AI alignment techniques.
One of my goals in writing this piece was to unify different frameworks for thinking about AGI development and inspire people who occupy one framework to expand their AGI perspectives when communicating with others.
But another goal was to lay out a framework I can reference when discussing the exciting possibilities of Moderately-superhuman AGI governance. I’ll be blogging about MAGI governance and strategy ideas more in the future, so stay tuned if you’re interested!
Agree that some way of talking is useful, but disagree with where you ended up. “Human-level” is part of an ontology from far away, and the need you’re pointing to is for an ontology from close up.
Here’s what I mean by “far away” vs “close up”:
When I’m two miles from my house, “towards my house” is a well-defined direction. When I’m inside my house, “towards my house” is meaningless as a direction to move. The close up ontology needs to expand details that the far away one compresses.
For operating when we’re close to human level AI, we don’t want “human level” to remain a basic location, we want to split up our map into finer details. We could split cognition into skills like working memory, knowledge, planning, creativity, learning, etc., splitting them further or adding dimensions for their style and not just their quality if needed.
Yeah, that’s a good point.
But I also think that maybe there’s a small refinement of these definitions which saves most of the value for the purposes of planning for safety.
If you simply narrow the focus of the terms to “world optimization power”, then I think it basically holds.
Subskills, like working memory, may or may not be a part of a given entity being evaluated. The evaluation metric doesn’t care if it is just measuring the downstream output of world optimization.
Admittedly, this isn’t something we have particularly good measures of. It’s a wide target to try to cover with a static eval. But I still think it works conceptually, so long as we acknowledge that our measures of it are limited approximations.
I think this is great. I think having clearer terms to discuss these things will be helpful, and I hope these get adopted.
I believe that software/algorithmic progress is sufficient for MAGI and SAGI. I also think that the necessary algorithmic advances could be found quite quickly by a large population of HAGI researchers. Thus, I expect something like:
HAGI sometime in 2025-2027
MAGI just 4 months − 1 year after HAGI
SAGI just 1 − 8 months after MAGI.
I have some specific reasoning and evidence to support my view, but I also acknowledge that there are a lot of unknowns being filled in with hunches in my predictions. I don’t think I can make a compelling case that my expected timelines are exactly what we should expect, by I do think I can argue that these projections are within reason. I also think that even shorter timelines than I expect are possible.
I think that the set of preparations it makes sense for society to take differ substantially if you think it is possible that timelines could be very short versus if you think we have strong evidence to support the view that such short timelines would be impossible.