This work was inspired by a question by Vanessa Kosoy, who also contributed several of the core ideas, as well as feedback and mentorship.
Abstract
We outline a computationalist interpretation of quantum mechanics, using the framework of infra-Bayesian physicalism. Some epistemic and normative aspects of this interpretation are illuminated by a number of examples and theorems.
1. Introduction
Infra-Bayesian physicalism was introduced as a framework to investigate the relationship between a belief about a joint computational-physical universe and a corresponding belief about which computations are realized in the physical world, in the context of “infra-beliefs”. Although the framework is still somewhat tentative and the definitions are not set in stone, it is interesting to explore applications in the case of quantum mechanics.
1.1. Discussion of the results
Quantum mechanics has been notoriously difficult to interpret in a fully satisfactory manner. Investigating the question through the lens of computationalism, and more specifically in the setting of infra-Bayesian physicalism provides a new perspective on some of the questions via its emphasis on formalizing aspects of metaphysics, as well as its focus on a decision-theoretic approach. Naturally, some questions remain, and some new interesting questions are raised by this framework itself.
The toy setup can be described on the high level as follows (with details given in Sections 2 to 4). We have an “agent”: in this toy model simply consisting of a policy, and a memory tape to record observations. The agent interacts with a quantum mechanical “environment”: performing actions and making observations. We assume the entire agent-environment system evolves unitarily. We’ll consider the agent having complete Knightian uncertainty over its own policy, and for each policy the agent’s beliefs about the “universe” (the joint agent-environment system) is given by the Born rule for each observable, without any assumption on the correlation between observables (formally given by the free product). We can then use the key construction in infra-Bayesian physicalism — the bridge transform — to answer questions about the agent’s corresponding beliefs about what copies of the agent (having made different observations) are instantiated in the given universe.
In light of the falsity of Claims 4.15 and 4.17, we can think of the infra-Bayesian physicalist setup as a form of many-worlds interpretation. However, unlike the traditional many-worlds interpretation, we have a meaningful way of assigning probabilities to (sets of) Everett branches, and Theorem 4.19 shows statistical consistency with the Copenhagen interpretation. In contrast with the Copenhagen interpretation, there is no “collapse”, but we do assume a form of the Born rule as a basic ingredient in our setup. Finally, in contrast with the de Broglie–Bohm interpretation, the infra-Bayesian physicalist setup does not privilege particular observables, and is expected to extend naturally to relativistic settings. See also Section 8 for further discussion on properties that are specific to the toy setting and ones that are more inherent to the framework. It is worth pointing out that the author is not an expert in quantum interpretations, so a lot of opportunities are left open for making connections with the existing literature on the topic.
1.2. Outline
In Section 2 we describe the formal setup of a quantum mechanical agent-environment system. In Section 3 we recall some of the central constructions in infra-Bayesian physicalism, then in Section 4 we apply this framework to the agent-environment system. In Sections 4.2 and 4.3 we write down various statements relating quantities arising in the infra-Bayesian physicalist framework to the Copenhagen interpretation of quantum mechanics. While Section 4.2 focuses on “epistemic” statements, Section 4.3 is dedicated to the “normative” aspects. A general theme in both sections is that the stronger, “on the nose” relationships between the interpretations fail, while certain weaker “asymptotic” relationships hold. In Section 5.1 we construct counterexamples to the stronger claims, and in in Sections 6 and 7 we prove the weaker claims relating the interpretations. In Section 8 we discuss which aspects of our setup are for the sake of simplicity in the toy model, and which are properties of the broader theory.
2. Setup
First, we’ll describe a standard abstract setup for a simplified agent-environment joint system. We have the following ingredients:
A finite set A of possible actions of the agent.
A finite set O of possible observations of the agent.
We’ll write E=O×A, the set of observation-action pairs.
For technical reasons it will be convenient to add a symbol 0 for “blank”, and fix a bijection E+=E⊔{0}≅Z/N
preserving 0, where N=|O|⋅|A|+1.
We’ll use this bijection to treat E+ as an abelian group implicitly.
A Hilbert space He corresponding to states of the environment.
Fix a finite time horizon[1]T∈N. A classical state of a cyclic, length T memory tape is a function τ:Z/T→E+. Let TpT be the set of all classical tape states.
A Hilbert space Hg with orthonormal basis ∣∣ψgτ⟩ for τ∈Tp, corresponding to the quantum state of the agent.
For each a∈A a unitary map of the environment Ua:He→He, describing the “result of the action”.
A projection-valued measure P on O, valued in He (giving projections Po:He→He for each observation o∈O).
Let H=Hg⊗He be the state space of the joint agent-environment system.
Remark 2.1. It would be interesting to consider a setting where the agent is allowed to choose the observation in each step (e.g. have the projection-valued measure P depend on the action taken). For simplicity we’ll work with a fixed observation as described above.
Definition 2.2. Let O≤T=t≤T⨆t∈NOtE≤T=t≤T⨆t∈NEt be the set of observation histories and observation-action histories respectively, i.e. finite strings of observations (resp. observation-action pairs) up to length T. There’s a natural map obs:E≤T→O≤T, extracting the string of observations from a string of observation-action pairs. We’ll call a function π:O≤T→A a policy. For two histories h1,h2 (of either type), we’ll sometimes write h1⊏h2 to mean h1 is a (not necessarily proper) prefix (i.e. initial substring) of h2.
Remark 2.3. We only consider deterministic policies here. It’s not immediately clear how one would generalize Definition 2.7 to randomized policies. In fact, we can always (and is perhaps more principled to) think of our source of randomness for a randomized policy to be included in the environment, so we don’t lose out on generality by only considering deterministic policies. For example, if the source of our randomness is a quantum coin flip, then our approach offers a convenient way of modeling this by including the coin as a factor of He, i.e. part of the environment subsystem.
Definition 2.4. For a tape state τ:Z/T→E+ and an observation-action pair ε∈E, let mem(τ,ε):Z/T→E+ be the state of the tape after writing the pair ε to the tape, defined by mem(τ,ε)(n)={τ(n−1)n≠0τ(−1)+εn=0.
Remark 2.5. Choosing a group structure on E+ is in order to make the map mem(−,ε):Tp→Tp invertible, which in turn makes the map Uoπ in Definition 2.7 unitary.
Definition 2.6. Let the “history extraction” map hist:Tp→E≤T be defined by hist(τ)=(τ(N−1),…,τ(0))∈EN, where 0≤N≤T is largest such that there’s no 0≤n<N with τ(n)=0 (i.e. so that the [0,N) portion of the tape contains no blanks).
Definition 2.7 (Time evolution of a policy). For each policy π:O≤T→A, we define the single time-step unitary evolution operator Uπ on H as the composite of an “observation” and an “action” operator Uπ=UA,π∘UO,π, where UO,π(∣∣ψgτ⟩⊗Po|ψe⟩)=∣∣ψgmem(τ,(o,a))⟩⊗Po|ψe⟩for all o∈OUA,π(∣∣ψgτ⟩⊗|ψe⟩)=∣∣ψgτ⟩⊗Ua|ψe⟩for a=π(obs(hist(τ)))
The time evolution after t∈N time-steps is given by Utπ=Uπ∘…∘Uπ, i.e.Uπ composed with itself t times.
Remark 2.8. As defined above, the first step in the evolution is an observation, so we never use the value of the policy on the empty observation string. In this respect it would be more natural to start with an action instead, but it would make some of the notation and the examples more cumbersome, so we sacrifice a bit of naturality for the sake of simplicity overall.
Lemma 2.9. The operator Uπ is unitary on H.
Proof. The operator UA,π is clearly unitary since each Ua is. We can see that UO,π is unitary as follows. Choose an orthonormal basis ∣∣ψeo,i⟩ of PoHe for each o∈O, so together they form an orthonormal basis for He (note that the range of i might vary for varying o). Then ∣∣ψgτ⟩⊗∣∣ψeo,i⟩ forms an orthonormal basis for H, and UO,π permutes this basis, hence is unitary.□
3. Prerequisites
We recall some definitions and lemmas within infra-Bayesianism. This is in order to make the current article fairly self-contained, all the relevant notions here were introducted in [IBP], [BIMT] and [LBIMT]. In particular we omit proofs in this section, all the relevant proofs can be found in the articles listed.
3.1. Ultracontributions
First of all, we work with a notion of belief intended to incorporate a form of Knightian uncertainty. Formally, this means that we work with sets of distributions (or rather “contributions” turn out to be a more flexible tool).
Definition 3.1. Given a finite set X, a contribution μ is a non-negative measure on X, such that μ(X)≤1. We denote the set of contributions ΔcX. A contribution is a distribution if μ(X)=1, so we have ΔX⊂ΔcX.
There’s a natural order on ΔcX, given by pointwise comparison.
Definition 3.2. We call a subset A⊂ΔcXdownward closed if for μ∈A, ν≤μ implies ν∈A.
As a subspace of RX, the set ΔcX inherits a metric and a convex structure.
Definition 3.3. We call a closed, convex, downward closed subset Θ⊂ΔcX a homogenious ulta-contribution (HUC for short). We denote the set of HUCs by □X.
We’ll work with HUCs as our central formal notion of belief in this article. The exact properties required (closed, convex and downward closed) should be illuminated by Lemma 3.6.
Definition 3.4. Given a HUC Θ∈□X, and a function f:X→[0,1], we define the expected valueEΘ[f]=maxθ∈ΘEθ[f]=maxθ∈Θ∑x∈Xθ(x)f(x).
Thinking of f as a loss function, this is a worst-case expected value, given Knightian uncertainty over the probabilities.
Remark 3.5. It’s worth mentioning that the prefix “infra” originates from the concept of infradistributions, which is the notion corresponding to ultracontributions, in the dual setup of utility functions instead of loss functions. We still often use the term “infra” in phrases such as infra-belief or infra-Bayesianism, but now simply carrying the connotation of a “weaker form” of belief etc., compared to the Bayesian analog.
Lemma 3.6. For Θ∈□X, the expected value defines a convex, monotone, homogeneous functional EΘ[−]:[0,1]X→[0,1].
Lemma 3.7. There is a duality Θ↦EΘ, between □X (i.e. closed, convex, and downward closed subsets of ΔcX) and convex, monotone, and homogeneous functionals [0,1]X→[0,1].
For a functional F:[0,1]X→[0,1], the inverse map in the duality is given by F↦ΘF=⋂f:X→[0,1]{θ∈ΔcX:Eθ[f]≤F[f]}.
3.2. Some constructions
For the current article to be more self-contained, we spell out a few definitions used in this discussion.
Definition 3.8. Given a map of finite sets f:X→Y, we define the pushforward
f∗:ΔcX→ΔcYto be given by the pushforward measure. We use the same notation to denote the pushforward on HUCs, f∗:□X→□Y, given by forward image, that is f∗(Θ)={f∗(θ)∈ΔcY|θ∈Θ}. Equivalently, in terms of the expectation values we have for g:Y→[0,1]Ef∗(Θ)[g]=EΘ[g∘f].
Definition 3.9. Given a collection of finite sets Xi, and HUCs Θi∈□Xi, we define the free product⋈iΘi∈□(∏iXi) as follows. For a contribution θ∈Δc∏iXi we have θ∈⋈iΘi if and only if for each j,
(prj)∗(θ)∈Θj⊂ΔcXj, where prj:∏iXi→Xj is projection onto the ith factor.
The free product thus specifies the allowed marginal values, but puts no further restriction on the possible correlations.
Definition 3.10 (Total uncertainty). The state of total (Knightian) uncertainty ⊤X∈□X is defined as ⊤X=ΔcX, i.e. the subset of all contributions.
Definition 3.11 (Semidirect product). Given a map β:X→□Y, and an element Θ∈□X, we can define the semidirect productΘ⋉β∈□(X×Y). This is easier to write down in terms of the expectation functionals, as follows. For g:X×Y→[0,1], define EΘ⋉β[g]=EΘ[Eβ(x)[g(x,−)]]. Here Eβ(x)[g(x,−)] is the function X→[0,1], whose value at x∈X is given by by taking expected value with respect to β(x)∈□Y of the function g(x,−):Y→[0,1].
As a subset of Δc(X×Y),
⊤X⋉β can be understood as the convex hull of the δx×θ for all x∈X and all θ∈β(x)⊂ΔcY. For Θ⋉β one needs to further restrict to contributions that project down into Θ⊂ΔcX.
3.3. The bridge transform
The key construction we’ll be considering in infra-Bayesian physicalism is the bridge transform. This construction is aimed at answering the question “given a belief about the joint computational-physical universe, what should our corresponding belief be about which computations are realized in the physical universe?”.
We’ll discuss these notions in a bit more detail, but for now both the physical universe Φ and the computational universe Γ are just assumed to be finite sets.
Definition 3.12. Given Θ∈□(Γ×Φ), the bridge transform of Θ,
Br(Θ)∈□(Γ×2Γ×Φ) is defined as follows (cf. [IBP Definition 1.1]). For a contribution θ∈Δc(Γ×2Γ×Φ) we have θ∈Br(Θ) if and only if for any s:Γ→Γ, under the composite
we have ~s(θ)∈Θ⊂Δc(Γ×Φ).
Remark 3.13. The use of all endomorphism s:Γ→Γ in Definition 3.12, although concise, doesn’t feel fully principled as of now. We would typically think of the computational universe Γ as the set of all possible assignments of outputs to programs, i.e. Γ=ΣR, for a certain output alphabet Σ, and a set of programs R (see Definition 4.1). In this context, ΓΓ feels somewhat unnatural. That being said, in the current discussion we mainly use the fact that ΓΓ acts transivitely on Γ, so it’s possible that these results would survive in some form under a modified definition of the bridge transform.
For easy reference, we spell out [IBP Proposition 2.10]:
Lemma 3.14 (Refinement). Given a mapping between physical universes f:Φ1→Φ2, we have
That is, for a belief Θ∈□(Φ1×Γ) we have (idelΓ×f)∗(Br(Θ))⊂Br((idΓ×f)∗(Θ)).
4. An infra-Bayesian physicalist interpretation
We’ll work with a certain specialized setup of [IBP].
Definition 4.1. Let the set of “programs”
R=O≤T, the “output alphabet”
Σ=A, and the set of “computational universe states”
Γ=ΣR=AO≤T be the set of policies up to time horizon T. We’ll write elΓ={(π,α)∈Γ×2Γ:π∈α}.
Definition 4.2. Let a “universal observable” B be a triple (VB,QB,tB), where VB is a finite set (of “observation outcomes”), QB is a projection-valued measure on VB, valued in H (giving projections QB(v):H→H for each v∈VB), and an “observation time”
tB∈N<T. Let U be the set of all universal observables, up to the natural notion of equivalence.
Remark: We use the term “universal observable” here to distinguish between observables of the “universe” (i.e. the joint agent-environment system) from the observations of the environment by the agent.
Definition 4.3 (Initial state). Fix a normalized (norm 1) initial state ∣∣ψe0⟩∈He of the environment, and let ∣∣ψg0⟩ be the state of the agent corresponding to an empty memory tape, i.e.τ:Z/T→E given by τ(n)=0 for all n. Let |ψ0⟩=∣∣ψg0⟩⊗∣∣ψe0⟩∈H be the initial state of the joint system.
Definition 4.4. For a policy π∈Γ, let the marginal distribution of the universal observable B be defined according to the Born rule:
βB(v|π)=∥QB(v)UtBπ|ψ0⟩∥2. I.e. the norm square of the vector obtained by evolving the universe following policy π for tB time-steps from the initial state, and then projecting onto the observation subspace corresponding to the universal observation v∈VB. So βB(−|π)∈ΔVB.
Definition 4.5. Let ΦU=∏B∈UVB be the set of “all possible states of the universe” (more precisely the set of all possible outcomes of all observations on the joint agent-environment system). More generally, define ΦS analogously for any subset S⊂U.
Definition 4.6. For a finite subset F⊂U, let βF(π)=⋈B∈FβB(−|π)∈□ΦF be the free product of the βB, as defined in Definition 3.9. For varying π this defines an ultrakernel βF:Γ→□ΦF, and the associated semidirect product ΘF=⊤Γ⋉βF∈□(Γ×ΦF). Taking the bridge transform and projecting out the physical factor ΦF:
□(Γ×ΦF)Br−→□(Γ×2Γ×ΦF)pr∗−−→□(Γ×2Γ), we get Θ∗F=pr∗(Br(ΘF))∈□(Γ×2Γ).
If F1⊂F2⊂U, we have a natural “refinement” map p:ΦF2→ΦF1, given by projecting out the additional factors in ΦF2. By Lemma 3.14, we have
so Θ∗F2⊂Θ∗F1. Inspired by this, we have the following.
Definition 4.7. Let Θ∗U=⋂F⊂UΘ∗F, where the intersection is over all finite subsets of U.
4.1. Copenhagen interpretation
Definition 4.8. Let h∈E≤T be an observation-action history, and denote by Qh:H→H the projection corresponding to the proposition “the memory tape recorded history h”. More precisely Qh=Qgh⊗idHe, where Qgh∣∣ψgτ⟩={∣∣ψgτ⟩if hist(τ)=h0otherwise.
Definition 4.9. Given a sequence of observation-action pairs h∈En, let h≤m∈E≤m denote the truncated history (i.e. the image under projecting out the last n−m components of En if n>m, and h itself if n≤m).
In the Copenhagen interpretation the “universe” (i.e. the joint system of the agent and the environment) collapses after each observation of the agent.
Definition 4.10. Given a policy π:O≤T→A, the initial state |ψ0⟩∈H, and a sequence of observation-action pairs h∈En, we can define |ψt⟩=Qh≤tUπ|ψt−1⟩ for t>0 recursively. Then according to the Copenhagen interpretation, the probability of observing h is Cop(h|π)=∥|ψn⟩∥2.
Lemma 4.11. Collapsing at each step is the same as collapsing at the end, that is |ψt⟩=Qh≤tUtπ|ψ0⟩.
Proof. The claim is true for t=0,1 by definition. Assume it’s true for t−1, so |ψt−1⟩=Qh≤t−1Ut−1π|ψ0⟩. Let’s write Ut−1π|ψ0⟩=∑τ∈Tp∣∣ψgτ⟩⊗|φeτ⟩, so |ψt−1⟩=∑τ∈Tphist(τ)=h≤t−1∣∣ψgτ⟩⊗|φeτ⟩. Then if a=π(obs(h≤t−1))∈A, we have |ψt⟩=∑τ∈Tphist(τ)=h≤t∣∣ψgτ⟩⊗Ph(t)Ua|φeτ⟩, while Utπ|ψ0⟩=∑τ∈Tpo∈O∣∣ψgmem(τ,(o,a))⟩⊗PoUπ(hist(τ))|φeτ⟩. Now Qh≤t∣∣ψgmem(τ,(o,a))⟩=0 unless (o,a)=h(t) and hist(τ)=h≤t−1, hence Qh≤tUtπ|ψ0⟩=|ψt⟩ as claimed.□
4.2. Relating the two interpretations
Since Θ∗U∈□elΓ, we can take expectations of functions f:elΓ→[0,1], in particular indicator functions χq for q⊂elΓ.
Definition 4.12. For a policy π∈Γ, and a tuple of observations h∈On, define αh|π={γ∈Γ|γ(h)=π(h)}⊂Γ, and let qh|π={(π,α)∈elΓ|α⊂αh|π}⊂elΓ.
Remark 4.13. In what follows we’ll assume |A|>1. This assures that the set of policies is richer than the set of histories (i.e. |Γ|>|O≤T|). Much of the following fails in the degenerate case |A|=1.
When considering the infra-Bayesian physicalist interpretation of a quantum event h, we’ll consider the expected value EΘ∗U[χπ(1−χqh|π)]. As defined in Definition 4.6, ΘU can be thought of as the infra-belief ⊤Γ⋉βU∈□(Γ×ΦU), which is a joint belief over the computational-physical world, with complete Knightian uncertainty over the policy of the agent (as a representation of “free will”), and for each policy the corresponding belief about the physical world is as given by the unitary quantum evolution of the agent-environment system under the given policy. The bridge transform Θ∗U∈□elΓ of ΘU then packages the relevant beliefs about which computational facts are manifest in the physical world. The subset αh|π corresponds to the proposition “the policy outputs action a=π(h) upon observing h”, and hence qh|π corresponds to the belief “the physical world witnesses the output of the policy on h to be a=π(h) (which is to say there’s a version of the agent instantiated in the physical world that observed history h, and acted a)”. We’ll be investigating various claims about the quantity EΘ∗U[χπ(1−χqh|π)], which is the ultraprobability (i.e. the highest probability for the given Knightian uncertainty) of the agent following policy π and h not being observed (i.e. no agent being instantiated acting on history h).
Remark 4.14. It might at first seem more natural to consider the complement instead, that is χπχqh|π, which corresponds to the agent following policy π, and history h being observed. However, it turns out that EΘ∗U[χπχqh|π]=1 always. This can be understood intuitively via refinement (see Lemma 3.14): we can always extend our model of the physical world to include a copy of the agent instantiated on history h, so the highest probability of h being observed will be 1. This is also related to the monotonicity principle discussed in [IBP]. Thus although at first glance this might seem less natural, in our setup it’s more meaningful to study the ultraprobability of the complement, i.e. of h not being observed. Note that since we’re working with convex instead of linear expectation functionals (see Lemma 3.7), the complementary ultraprobabilities will typically sum to something greater than one.
We first state Claims 4.15 and 4.17 relating the IBP and Copenhagen interpretations “on the nose”, which both turn out to be false in general. Then we state the weaker Theorem 4.19, which is true, and establishes a form of asymptotic relationship between the two interpretations.
Claim 4.15. The two interpretations agree on the probability that a certain history is not realized given a policy. That is,
EΘ∗U[χπ(1−χqh|π)]=1−Cop(h|π).
This claim turns out to be false in general, and we give a counterexample in Counterexample 5.3. Note, however, that the claim seems to be true in the limit with many actions (i.e. |A|→∞), which would warrant further study. Now consider the following definition concerning two copies of the agent being instantiated.
Definition 4.18. For a policy π∈Γ, and two tuples of observations h1,h2∈On, define αh1,h2|π={γ∈Γ|γ(hi)=π(hi) for i=1,2}⊂Γ, and let qh1,h2|π={(π,α)∈elΓ|α⊂αh1,h2|π}⊂elΓ.
Claim 4.17. There is only one copy of the agent (i.e. the agent is not instantiated on multiple histories, there are no “many worlds”). That is, if neither of h1,h2∈On is a prefix of the other, then EΘ∗U[χπ(1−χqh1,h2|π)]=1.
This claim is the relative counterpart of Claims 4.15 and fails as well in general (see Counterexample 5.5). Again, however, this claim might hold in the |A|→∞ limit.
Definition 4.18. An event is a subset of histories E⊂OT. We define the corresponding qE|π=⋃h∈Eqh|π⊂elΓ, and Cop(E|π)=∑h∈ECop(h|π).
Theorem 4.19. The ultraprobability of an agent not being instantiated on a certain event can be bounded via functions of the (Copenhagen) probability of the event. More precisely,
1−√(2−Cop(E|π))Cop(E|π)≤EΘ∗U[χπ(1−χqE|π)]≤1−Cop(E|π).
Due to the failure of Claims 4.15 and 4.17, we can think of the infra-Bayesian physicalist setup as a form of many-worlds interpretation. However, since √(2−Cop(E|π))Cop(E|π)→0 as Cop(E|π)→0, the above Theorem 4.19 shows statistical consistency with the Copenhagen interpretation in the sense that observations that are unlikely according to the Born rule have close to 1 ultraprobability of not being instantiated (while very likely observations have close to 0 ultraprobability of uninstantiation).
Remark 4.20. For simplicity we assumed E only contains entire histories (i.e. ones of maximal length T). It’s easy to modify the definitions to account for partial histories. The inequalities in Theorem 4.19 remain true even if E includes partial histories, and the proofs are easy to adjust. We avoid doing this here in order to keep the notation cleaner. However, it’s worth noting some important points here. For a partial history h, let H⊂OT be the set of all completions of h, i.e.H={~h∈OT:h⊏~h}. Then we have Cop(h|π)=Cop(H|π)=∑~h∈HCop(~h|π). On the other hand,
qh|π≠qH|π=⋃~h∈Hq~h|π, so there is an important difference here between the two interpretations, which would warrant further discussion. In particular, under the infra-Bayesian physicalist interpretation it can happen that EΘ∗U[χπ(1−χqH|π)]>EΘ∗U[χπ(1−χqh|π)] for a partial history h and its set of completions H. This could be loosely interpreted as Everett branches “disappearing”, as the ultraprobability of an agent not being instantiated on the partial history h is less than that of the agent not being instantiated on any completion of that history.
4.3. Decision theory
To shed more light on the way the infra-Bayesian physicalist interpretation functions, it is interesting to consider the decision theory of the framework, along with the epistemic considerations above.
Definition 4.21. Consider a loss function L:D→R≥0, where D=ET is the set of destinies. We can then construct the physicalized loss function (cf. [IBP Definition 3.1])
Lphys:elΓ→R≥0, given by Lphys(γ,α)=minh∈Xαmaxd∈Dh⊏dL(d), where Xα is the set of histories witnessed by α, that is Xα={h∈E≤T|∀ga⊏h,∀~γ∈α:~γ(obs(g))=a}. Note that in our simplified context, Lphys(γ,α) doesn’t depend on γ.
Definition 4.22. We can define the worst-case expected physicalized loss associated to a policy π by LIBP(π)=EΘ∗U[χπ⋅Lphys]. Under the Copenhagen model, we would instead simply consider LCop(π)=ECop[L|π]=∑d∈DCop(d|π)L(d).
Remark 4.23. Given a policy π∈Γ, we can consider the set of “fair” counterfactuals (cf. [IBP Definition 1.5])
Cπfair={(γ,α)∈elΓ|∀h∈O≤T:(∀~γ∈α,∀~h⊏h:~γ(~h)=γ(~h))⟹γ(h)=π(h)}, i.e. where if α witnesses the history h, then γ agrees with π on that history. This definition is in contrast with the “naive” counterfactuals we considered above (when writing χπ):
Cπnaive={(γ,α)∈elΓ|γ=π}. In Definition 4.22 above, and generally whenever we use χπ, we could have used the indicator function of Cπfair instead. The choice of counterfactuals affects the various expected values, however, all of the theorems in this article remain true (and Claims 4.15 and 4.17 remain false) for both naive and fair counterfactuals. We thus work with naive counterfactuals for the sake of simplicity.
Similarly to Section 4.2, the “on the nose” claim relating the two interpretations fails, but we have an asymptotic relationship which holds.
Claim 4.24. The two interpretations agree on the loss of any policy:
LIBP(π)=LCop(π).
Again, this turns out to be false, and we give a simple counterexample in Counterexample 5.6.
To allow discussing the asymptotic behavior, assume now that we incur a loss at each timestep, given by ℓ:E=O×A→R≥0, and we consider the total loss L=T∑t=1ℓt:D→R≥0. We might hope that we could have at least the following.
Claim 4.25. The two interpretations agree on the loss of any policy asymptotically:
LIBP(π)∼LCop(π), i.e. the difference is bounded sublinearly in T.
This claim is still false in general for essentially the same reason as Claim 4.24 since certain policies might involve a one-off step that then affect the entire asymptotic loss. We give a detailed explanation in Counterexample 5.7. We do however have the following.
Theorem 4.26. If the resulting MDP is communicating (see Definition 7.8), then for any policy π we have LCop(π∗)−o(T)≤LIBP(π)≤LCop(π), where π∗ is a Copenhagen-optimal policy. In particular, optimal losses for the IBP and Copenhagen frameworks agree asymptotically.
We’ll look at a few concrete examples in detail, firstly to gain some insight into how Claims 4.15 and 4.17 fail in general, and secondly to see how our framework operates in the famously puzzling Wigner’s friend scenario.
5.1. Counterexamples
We’ll construct simple counterexamples to Claims 4.15 and 4.17 in the smallest non-degenerate case, i.e. when |O|=2 and |A|=2, and T=1. Let O={o0,o1} and A={a0,a1}. There are four policies in this case (ignoring the value of the policies on the empty input, which is irrelevant in our setting, see Remark 2.8), which we’ll abbreviate as π00,π01,π10,π11, where πij(o0)=aiπij(o1)=aj. Assume h=o0, and π=π00, so αh|π={π00,π01}.
Lemma 5.1. For ρ∈ΔcelΓ×Φ, we have ρ∈Br(Θ) if and only if for each s:Γ→Γ and g:Γ×Φ→[0,1]Eρ[~g]≤EΘ[g], where ~g:elΓ×Φ→[0,1] is given by γ,α,x↦χs(γ)∈α⋅g(s(γ),x).
Lemma 5.2. Let β:Γ→ΔΦ be a kernel,
Θ=⊤Γ⋉β, and Θ∗=pr∗(Br(Θ)) as above. Then EΘ∗[χπ(1−χqh|π)]=E(β(π10)+β(π11))∧β(π00)[1].
Proof. To obtain a lower bound (although we’ll only use the upper bound for the counterexample), define the contribution ρ∈Δc(elΓ×Φ) by ρ=δπ00,{π00,π10}×ϕ10+δπ00,{π00,π11}×ϕ11, where ϕ10,ϕ11∈ΔcΦ are such that ϕ10≤β(π10),ϕ11≤β(π11), and ϕ10+ϕ11=(β(π10)+β(π11))∧β(π00). One possible such choice is ϕ10=β(π10)∧β(π00)ϕ11=β(π11)∧(β(π00)−ϕ10). Then it’s easy to verify that ρ∈Br(Θ), and Eρ[χπ(1−χqh|π)]=E(β(π10)+β(π11))∧β(π00)[1].
To obtain an upper bound, fix x0∈Φ, and use Lemma 5.1 for constant s=π00, and g(γ,x)=χγ=π00⋅χx=x0.
We have ~g(γ,α,x)=χπ00∈α⋅g(π00,x)=χπ00∈α⋅χx=x0, and so
Eρ[χπ00∈α⋅χx=x0]=Eρ[~g]≤EΘ[χγ=π00⋅χx=x0]=Eβ(π00)[χx=x0].(1)
Analogously for π10 and π11 we get
Eρ[χπ10∈α⋅χx=x0]≤EΘ[χγ=π10⋅χx=x0]=Eβ(π10)[χx=x0],(2) and
Eρ[χπ11∈α⋅χx=x0]≤EΘ[χγ=π11⋅χx=x0]=Eβ(π11)[χx=x0].(3)
Now,
χπ(1−χqh|π)χx=x0≤χπ00∈α⋅χx=x0, so by (1) we get
Eρ[χπ(1−χqh|π)χx=x0]≤Eβ(π00)[χx=x0].(4)
We also have 1−χqh|π≤χπ10∈α+χπ11∈α, since π10∉α and π11∉α together would imply α⊂αh|π00. Thus
χπ(1−χqh|π)χx=x0≤(χπ10∈α+χπ11∈α)⋅χx=x0,
so adding (2) and (3), we obtain
Eρ[χπ(1−χqh|π)χx=x0]≤Eβ(π10)+β(π11)[χx=x0].(5)
Now, since both (4) and (5) hold, we get Eρ[χπ(1−χqh|π)χx=x0]≤E(β(π10)+β(π11))∧β(π00)[χx=x0]. Finally, summing over x0∈Φ we have the required upper bound EΘ∗[χπ(1−χqh|π)]=E(β(π10)+β(π11))∧β(π00)[1].□
Counterexample 5.3. Let He be a qubit state space, and ∣∣ψe0⟩=|+⟩=1√2(|0⟩+|1⟩). Let Ua0=Ua1=idHe. Let the observation P correspond to measuring the qubit, so Po0,Po1 are projections onto |0⟩ and |1⟩ respectively. Then Claim 4.15 fails in this setup.
Proof. We have |ψ0⟩=∣∣ψg0⟩⊗∣∣ψe0⟩=|0⟩⊗1√2(|0⟩+|1⟩), and so Uπ00|ψ0⟩=1√2(|o0a0⟩⊗|0⟩+|o1a0⟩⊗|1⟩),Uπ10|ψ0⟩=1√2(|o0a1⟩⊗|0⟩+|o1a0⟩⊗|1⟩),Uπ11|ψ0⟩=1√2(|o0a1⟩⊗|0⟩+|o1a1⟩⊗|1⟩). Now consider the universal observable B which is measurement along the vector |v⟩ and its complement, where |v⟩=12√3(3|o0a0⟩⊗|0⟩+|o1a0⟩⊗|1⟩−|o0a1⟩⊗|0⟩+|o1a1⟩⊗|1⟩) I.e. we have VB={v,v⊥}, and QB(v)=Pv,QB(v⊥)=Pv⊥, where Pv, Pv⊥ are projections in H=Hg⊗He onto |v⟩ and its ortho-complement respectively. Then we have the following values for βB for the various policies:
π00
π10
π11
βB(v)
2⁄3
0
0
βB(v⊥)
1⁄3
1
1
This can be seen by noticing that |v⟩ is perpendicular to both Uπ10|ψ0⟩ and Uπ11|ψ0⟩, while ⟨v∣∣Uπ00ψ0⟩=2√6, so βB(v|π00)=|⟨v∣∣Uπ00ψ0⟩|2=23. This means that for this B we have (βB(π10)+βB(π11))∧βB(π00)[1]=1/3. If FB={B}, by Lemma 5.2 we have EΘ∗FB[χπ(1−χqh|π)]=E(βB(π10)+βB(π11))∧βB(π00)[1]=1/3. Now, by definition Θ∗U⊂Θ∗FB, so we also have EΘ∗U[χπ(1−χqh|π)]≤1/3<1−Cop(h|π)=12.□
Although we won’t need the exact value here, we remark to the interested reader that in the above setup of Counterexample 5.3, the ultraprobability attains the lower bound of Theorem 4.19, that is EΘ∗U[χπ(1−χqh|π)]=1−√3/4≈0.134.
We can extend the above counterexample to apply to Claim 4.17, via the following.
Lemma 5.4. Let β:Γ→ΔΦ be a kernel,
Θ=⊤Γ⋉β, and Θ∗=pr∗(Br(Θ)) as above. Then for h1=o0, h2=o1,
EΘ∗[χπ(1−χqh1,h2|π)]=E(β(π10)+β(π01)+β(π11))∧β(π00)[1].
Proof. Consider projecting onto the three vectors |v1⟩=Uπ00|ψ0⟩=1√2(|o0a0⟩⊗|0⟩+|o1a0⟩⊗|1⟩),|v2⟩=Uπ11|ψ0⟩=1√2(|o0a1⟩⊗|0⟩+|o1a1⟩⊗|1⟩), and |v3⟩=1√2(Uπ01|ψ0⟩−Uπ10|ψ0⟩)=12(|o0a0⟩⊗|0⟩−|o1a0⟩⊗|1⟩+|o0a1⟩⊗|0⟩−|o1a1⟩⊗|1⟩). Then the corresponding probabilities are
π00
π01
π10
π11
βB(v1)
1
1⁄4
1⁄4
0
βB(v2)
0
1⁄2
1⁄2
0
βB(v3)
0
1⁄4
1⁄4
1
So we have E(βB(π10)+βB(π01)+βB(π11))∧βB(π00)[1]=1/2<1. Then again, by refinement, this implies that EΘ∗[χπ(1−χqh1,h2|π)]≤1/2<1 as well. □
Counterexample 5.6. Claim 4.24 fails in the setup of Counterexample 5.3, with loss given by ℓ:O×A→R≥0,ℓ(o,a)={0 if o=o01 if o=o1.
Proof. In this case Lphys(γ,α)={0 if ∀~γ∈α:~γ(o0)=γ(o0)1 otherwise. Notice that for this Lphys we actually have χπ⋅Lphys=χπ(1−χqo0|π), so by the considerations in Counterexample 5.3, we also have (for any policy π)
LIBP(π)≤1/3<1/2=LCop(π), showing failure of Claim 4.24. □
Counterexample 5.7. The setup of Counterexample 5.6, run over time horizon T instead of just a single timestep shows the failure of the asymptotic claim Claim 4.25 in general.
Proof. The point is that in this setup the entire loss is determined by the outcome of the first observation: if we observe o0, we’ll incur 0 loss during the entire time, while if we observe o1 first, we’re “stuck” in that state, and hence incur a total loss equal to T. Due to this, we have LIBP(π)≤T3⋦T2=LCop(π), for any policy π. □
Note that in the above setup, we get “stuck” in the states after the initial observation because the MDP itself is not communicating. However, even for communicating MDPs (for example if we choose Ua1 to be a rotation by π/4) certain policies will get stuck (for example the policy that always chooses a0 corresponding to Ua0=id). So we see this behavior whenever the asymptotic loss is dependent on a few initial steps. On the other hand, for example if π is a stationary policy, and the resulting Markov chain is irreducible, then we can obtain a concentration bound on the loss (e.g. via the central limit theorem, [Dur96[2], 5.6.6.]), and use an argument similar to Theorem 7.21 to show that LIBP and LCop indeed agree asymptotically under such assumptions.
5.2. Wigner’s friend
We’ll consider a scenario originally attributed to Wigner, and we’ll work in an extension of the setting introduced in [BB19[3]]. For brevity, we’ll omit detailed computations in this section and focus on the higher level ideas instead. Consider a joint system consisting of three parts, a spin-12 particle S, a friend F in a lab, making observations of S, and Wigner W making observations of the lab (the joint friend-particle system FS).
Let the observation and action sets of the agents F and W be OF={oF0,oF1},AF={aF0,aF1},OW={L+00,L−00,L+11,L−11},AW={aW0,aW1}, respectively. Assume the state spaces for F and W are given by their individual memory tape states HF and HW as described in Section 2. Suppose the spin-12 particle is initially in the state ∣∣ψS0⟩=|+⟩=1√2(|0⟩+|1⟩)∈HS. The friend then measures S in the {|0⟩,|1⟩} basis, and performs an action aF∈AF according to the policy πF∈ΓF=AOFF. The lab L=FS then evolves unitarily to the state |ψL⟩=1√2(∣∣oF0πF(oF0)⟩F|0⟩S+∣∣oF1πF(oF1)⟩F|1⟩S), where oF0,oF1∈OF correspond to F observing 0 or 1 respectively. Finally, suppose Wigner measures the lab L=FS in the following basis: ∣∣L+00⟩=1√2(∣∣oF0aF0⟩F|0⟩S+∣∣oF1aF0⟩F|1⟩S),∣∣L−00⟩=1√2(∣∣oF0aF0⟩F|0⟩S−∣∣oF1aF0⟩F|1⟩S),∣∣L+11⟩=1√2(∣∣oF0aF1⟩F|0⟩S+∣∣oF1aF1⟩F|1⟩S),∣∣L−11⟩=1√2(∣∣oF0aF1⟩F|0⟩S−∣∣oF1aF1⟩F|1⟩S). So the two L00 vectors correspond to states of the lab where the action of F was aF0 (regardless of observation), and L11 vectors correspond to states where the action was a1. Technically these four vectors are not a basis of the full HL=HF⊗HS, since dim(HL)=8. Nevertheless, |ψL⟩ always falls within the four dimensional subspace spanned by these. If we wanted to be more precise, we could add further observation(s) to OW, corresponding to the complement of this four dimensional subspace, but this wouldn’t affect our discussion here, and would introduce additional notation.
Now let’s assume F follows the constant policy πF00(oFi)=aF0 (for i=0,1). Then Wigner will observe L+00 with probability 1. Yet, if the friend F believes that having observed oFi, the state of the lab collapsed to ∣∣oFiaF0⟩F|i⟩S, then the friend would expect Wigner to observe L+00 or L−00 with probability 12 each. Thus, within collapse theories we have an apparent conflict between the predictions of Wigner and the friend.
We can model this scenario within IBP by taking Γ=ΓF×ΓW=AOFF×AOWW be the pairs of policies of Wigner and the friend. Analogously to Definition 4.6 we can define ΦU as the joint outcome of all observables on the joint triple system WFS, a kernel βU:Γ→□ΦU, and the corresponding belief ΘU=⊤Γ⋉βU∈□(Γ×ΦU), and its projected bridge transform Θ∗U∈□elΓ. To be more precise we would again build this out of finite subsets of U, as in Definition 4.7.
Given this setup, we can write down various definitions. For hW∈OW, let αhW|πW={(γF,γW)∈Γ|γW(hW)=πW(hW)}∈2Γ,qhW|πW={α∈2Γ|α⊂αhW|πW}⊂2Γ. Then we can compute EΘ∗U[χπF00,πW(1−χqL+00|πW)]=0, i.e. the observation L+00 of Wigner is certain to be instantiated if F follows the policy πF00.
We can also write down other quantities, for example for hF∈OF, hW∈OW, we can define αhF,hW|πF,πW={(γF,γW)∈Γ|γW(hW)=πW(hW),γF(hF)=πF(hF)}∈2Γ, and the analogous qhF,hW|πF,πW. The quantity EΘ∗U[χπF00,πW(1−χqo0,L+00|πF00,πW)] would then be the ultraprobability of the pair (W observing L+00, F observing o0) being uninstantiated. We can estimate the value of this ultraprobability using techniques similar to Section 6 to be around 0.35.
This setting is helpful to differentiate the decision theory of IBP from a collapse theory. For example, consider a loss function ℓ:OW→R≥0 that depends only on Wigner’s observation, with values: ℓ(L+00)=0,ℓ(L−00)=1,ℓ(L+11)=0.1,ℓ(L−11)=0.1. Now suppose the friend is trying to minimize ℓ.[4] Then assuming a unitary evolution of the lab, clearly πF00 is the optimal policy. However, if the friend assumes a collapse of the lab after her observation, then always choosing action aF1∈AF avoids ever having an overlap with the high-loss L−00, making the constant aF1 policy πF11∈ΓF optimal under the collapse interpretation.
We can consider this decision problem within IBP by working with the physicalized loss function ℓphys:elΓ→R≥0
(cf. Definition 4.21), given by [5]ℓphys(γ,α)=⎧⎪
⎪
⎪
⎪⎨⎪
⎪
⎪
⎪⎩0 if ∀~γ∈α:~γW(L+00)=γW(L+00)0.1 else if ∀~γ∈α:~γW(L+11)=γW(L+11)0.1 else if ∀~γ∈α:~γW(L−11)=γW(L−11)1 otherwise.
Then in IBP the friend would look for the policy minimizing the loss ℓIBP(πF)=EΘ∗U[χπF⋅ℓphys]. We can verify that the minimal loss ℓIBP(πF)=0 occurs exactly when πF=πF00 as expected, in contrast with the collapse interpretation.
6. Bounds on the ultraprobabilities
We’ll make use of the following observation.
Lemma 6.1. For a given history h∈Ot, if two policies π1,π2∈Γ agree on all prefixes of h, i.e.
π1(~h)=π2(~h) for all ~h⊏h, then QhUtπ1|ψ0⟩=QhUtπ2|ψ0⟩, where Qh is the projection corresponding to the observation obs(τ)=h, i.e. the memory tape having recorded h.
Proof. For t=1 we have Uπ1|ψ0⟩=∑o∈O|oπ1(o)⟩⊗Uπ1(o)Po∣∣ψe0⟩, and similarly for π2. Now for h=oi we have QhUπ1|ψ0⟩=|oiπ1(oi)⟩⊗Uπ1(oi)Poi∣∣ψe0⟩=QhUπ2|ψ0⟩, since π1(h)=π2(h) by assumption. For t>1 we can proceed by induction, using Lemma 4.11. □
6.1. Upper bound
To prove an upper bound on the expectation value, we can coarsen our set of physical states to only include measurements of the memory tape.
Let D=ET⊂TpT be the set of destinies.
Definition 6.2. Let BD be the universal observable corresponding to reading the destiny off the memory tape at time tBD=T. That is, VBD=D, and for d∈DQBD(d):Hg→Hg is given by ∣∣ψgτ⟩⊗|ψe⟩↦{∣∣ψgτ⟩⊗|ψe⟩if τ=d0otherwise.
Definition 6.3. Let Q⊂Γ×D be the relation of a destiny being compatible with a policy. That is,
(π,d)∈Q for d=(o1,a1,…,oT,aT) if and only if ai=π(o1,…,oi) for each 1≤i≤T.
Let FD={BD}, and note that ΦFD=VBD=D. Let βFD:Γ→ΔD be the corresponding kernel.
Lemma 6.4. The kernel βFD:Γ→ΔD is a PoCK for Q.
Proof. This is essentially saying that whenever π1,π2∈Γ are both compatible with a destiny d∈D, then βFD(d|π1)=βFD(d|π2). This claim follows by Lemma 6.1. □
Lemma 6.5. The bridge transform equals Br(ΘFD)=[⊤Γ⋉(Q−1⋊βFD)]↓. In particular, for a monotone increasing (in 2Γ) function f:Γ×2Γ→[0,1], we have EΘ∗FD[f]=maxγ∈ΓEβFD(γ)[f(γ,−)∘Q−1].(1)
For g=χqE|π (note that g is monotone decreasing) and d∈D we have g(γ,−)∘Q−1(d)=1 if
γ=π,
π∈Q−1(d), and
Q−1(d)⊂αh|π for some h∈E.
Lemma 6.6. We have Q−1(d)⊂αh|π if and only if h=obs(d) and aT=π(h) (where d=(o1,a1,…,oT,aT) as before).
Proof. If h=obs(d) and aT=π(h), then (γ,d)∈Q implies γ(h)=aT=π(h), so Q−1(d)⊂αh|π.
For the converse, assume Q−1(d)⊂αh|π. First choose γ∈Q−1(d) (which is always non-empty). In particular γ(h)=aT, so γ∈αh|π means π(h)=aT as well.
Now assume h≠obs(d). Then choose γ′∈Γ as follows. For ~h∈O≤T, let γ′(~h)=⎧⎪⎨⎪⎩ai if ~h=(o1,…,oi)~aT≠aT if ~h=ha1(arbitrary) otherwise. Then γ′∈Q−1(d)∖αh|π, contradiction. □
We therefore have EβFD(γ)[χqE|π(γ,−)∘Q−1]=⎧⎪
⎪⎨⎪
⎪⎩∑h∈E∑d∈Q(π)h=obs(d)βFD(π)(d)if γ=π0otherwise. Here ∑h∈E∑d∈Q(π)h=obs(d)βFD(π)(d)=Cop(E|π), so by applying (1) of Lemma 6.5 to the monotone increasing f=χπ(1−χqE|π), we have EΘ∗FD[χπ(1−χqE|π)]=1−Cop(E|π), since χπ(γ,α)=0 whenever γ≠π so the maxγ∈Γ is attained when γ=π. Since Θ∗U⊂Θ∗FD by definition, we have
Proposition 6.7.
EΘ∗U[χπ(1−χqE|π)]≤1−Cop(E|π).
6.2. Lower bound
Definition 6.8. For ease of notation we’ll write CE|π:=1−√(2−Cop(E|π))Cop(E|π).
Theorem 6.9. We have a lower bound EΘ∗U[χπ(1−χqE|π)]≥CE|π.
Proof. We’ll exhibit a contribution ρE|π∈ΔcelΓ
(Definition 6.12) such that ρE|π∈Θ∗U
(Proposition 6.18). The constructed ρE|π has (Lemma 6.13)
EρE|π[χπ(1−χqE|π)]=CE|π, which in turn will show that EΘ∗U[χπ(1−χqE|π)]=maxρ∈Θ∗UEρ[χπ(1−χqE|π)]≥EρE|π[χπ(1−χqE|π)]=CE|π.□
The rest of this section is dedicated to spelling out the results that are used in the proof outline above.
Lemma 6.10. Let |a⟩,|b⟩,|c⟩ be a set of three orthonormal vectors, and |ϕ⟩=α|a⟩+β|b⟩,|ψ⟩=α|a⟩+β|c⟩, where α,β∈C with |α|2+|β|2=1. Then the trace distance between the density matrices ρ=|ϕ⟩⟨ϕ| and σ=|ψ⟩⟨ψ| is dtr(ρ,σ)=12∥ρ−σ∥1=√1−|α|4.
Proof. In the basis given by |a⟩,|b⟩,|c⟩, the matrix of ρ−σ is ⎛⎜
⎜⎝|α|2α¯β0¯αβ|β|20000⎞⎟
⎟⎠−⎛⎜
⎜⎝|α|20α¯β000¯αβ0|β|2⎞⎟
⎟⎠=⎛⎜
⎜⎝0α¯β−α¯β¯αβ|β|20−¯αβ0−|β|2.⎞⎟
⎟⎠ The eigenvalues of this (rank 2) matrix are 0, and ±√1−|α|4, so the sum of the absolute values of the eigenvalues is ∥ρ−σ∥1=0+√1−|α|4+√1−|α|4=2√1−|α|4.□
Lemma 6.11. For two policies π1,π2, let Π12={d∈OT:∀h⊏d,π1(h)=π2(h)},E12=OT∖Π12. Then for any B∈U,
EβB(π1)∧βB(π2)[1]≥CE12|π1.
Proof. Roughly speaking, since π1 and π2 only differ outside of Π12, if the event Π12 was observed then π1 and π2 behave identically. More precisely, let hB∈OtB be a sequence of observations up to time tB. Then, if hB⊏d for some d∈Π12, by Lemma 6.1 we have QhBUtBπ1|ψ0⟩=QhBUtBπ2|ψ0⟩.(1) Without loss of generality we’ll assume tB=T from now on. Now,
UTπ1|ψ0⟩=∑h∈OTQhUTπ1|ψ0⟩=∑h∈Π12QhUTπ1|ψ0⟩+∑h∈OT∖Π12QhUTπ1|ψ0⟩, and similarly for π2. Write |π1∩π2⟩:=∑h∈Π12QhUTπ1|ψ0⟩=∑h∈Π12QhUTπ2|ψ0⟩, where the two sums are equal by (1). Also write |π1∖π2⟩:=∑h∈OT∖Π12QhUTπ1|ψ0⟩, and |π2∖π1⟩:=∑h∈OT∖Π12QhUTπ2|ψ0⟩, so that UTπ1|ψ0⟩=|π1∩π2⟩+|π1∖π2⟩, and UTπ2|ψ0⟩=|π1∩π2⟩+|π2∖π1⟩. The three vectors |π1∩π2⟩,
|π1∖π2⟩, |π2∖π1⟩ are orthogonal (since all of their Hg components are), and ∥|π1∩π2⟩∥2=∑h∈Π12∥QhUTπ1|ψ0⟩∥2=∑h∈Π12Cop(h|π1)=Cop(Π12|π1). From this, using Lemma 6.10, we can compute the trace distance between ρπ1=∣∣UTπ1ψ0⟩⟨UTπ1ψ0∣∣ and ρπ2=∣∣UTπ2ψ0⟩⟨UTπ2ψ0∣∣ to be dtr(ρπ1,ρπ2)=12∥ρπ1−ρπ2∥1=√1−∥|π1∩π2⟩∥4=√1−Cop(Π12|π1)2.
Now, for any measurement QB, if we write βB(v|π1)=∥QB(v)UTπ1|ψ0⟩∥2 for the distribution of outcomes, where v∈VB. Then the total variation distance between the distributions βB(−|π1) and βB(−|π2) is bounded above by the trace distance. That is,
dTV(βB(−|π1),βB(−|π2))=12∑v∈VB|βB(v|π1)−βB(v|π2)|≤dtr(ρπ1,ρπ2). So the overlap is bounded below as claimed EβB(π1)∧βB(π2)[1]=1−dTV(βB(−|π1),βB(−|π2))≥1−dtr(ρπ1,ρπ2)=1−√1−Cop(Π12|π1)2=CE12|π1.□
Definition 6.12. Given a policy π and an event E⊂OT, choose ~πE∈Γ such that ~πE(h)≠π(h) whenever ∀d∈D:h⊏d⟹d∈E~πE(h)=π(h) otherwise. Note that we are using |A|>1 here to allow the choice satisfying the first condition. That is, ~πE agrees with π on all histories except for the ones whose completions all lie in E. Let ρE|π=CE|π⋅δπ,{π,~πE}∈ΔcelΓ.
Lemma 6.13. We have EρE|π[χπ(1−χqE|π)]=CE|π.
Proof. The claim follows since {π,~πE}⊄αh|π for any h∈E. □
Definition 6.14. Let ϕB=CE|πEβB(π)∧βB(~πE)[1]βB(π)∧βB(~πE).
Lemma 6.15. The contribution ϕB has mass CE|π, i.e.
EϕB[1]=CE|π. Moreover,
ϕB≤βB(π)∧βB(~πE).
Proof. The mass follows from the definition. The inequality in the second claim follows by taking π1=π and π2=~πE in Lemma 6.11, and noticing that the E12 in the lemma equals E in this case. □
Lemma 6.16. For finite F⊂U, let ϕF=1C|F|−1E|π∏B∈FϕB∈ΔcΦF. Then ϕF∈βF(π)∩βF(~πE)⊂ΔcΦF.
Proof. For any f∈F, consider the projection prf:ΦF=∏B∈FVB→Vf. Then under (prf)∗:ΔcΦF→ΔcVf we have (prf)∗(ϕF)=1C|F|−1E|πϕf∏B∈F∖{f}EϕB[1]=C|F|−1E|πC|F|−1E|πϕf=ϕf≤βf(π)∧βf(~πE), where the last inequality follows from Lemma 6.15. Since this is true for all f, we have ϕF∈⋈B∈FβB(π)=βF(π)∈□ΦF, and also ϕF∈βF(~πE), hence ϕF∈βF(π)∩βF(~πE). □
Proposition 6.17. For each finite F⊂U, we have δπ,{π,~πE}×ϕF∈Br(ΘF)⊂Δc(elΓ×ΦF), and hence ρE|π=CE|π⋅δπ,{π,~πE}∈pr∗(Br(ΘF))=Θ∗F.
Proof. Let s:Γ→Γ be an endomorphism of the computational universe. We need to verify that for any such s, under the composite
we have ~s(δπ,{π,~πE}×ϕF)∈ΘF. Since ρE|π=CE|π⋅δπ,{π,~πE}, we have χelΓ≠0 only when s(π)=π or s(π)=~πE. For these cases, we have
If s(π)=π, then ~s(δπ,{π,~πE}×ϕF)=δπ×ϕF∈ΘF,
since ϕF∈βF(π) by Lemma 6.16.
If s(π)=~πE, then ~s(δπ,{π,~πE}×ϕF)=δ~πE×ϕF∈ΘF,
since ϕF∈βF(~πE) as well by Lemma 6.16.
□
Proposition 6.18. We have ρE|π=CE|π⋅δπ,{π,~πE}∈Θ∗U.
Theorem 7.1. For any policy π,
LIBP(π)≤LCop(π), where the two sides are as in Definition 4.22.
Proof. Using the notation from Section 6, we can apply (1) of Lemma 6.5 to the monotone increasing f=χπ⋅Lphys, to get EΘ∗FD[χπ⋅Lphys]=EβFD(π)[Lphys∘Q−1], since the maximum over γ∈Γ is attained when γ=π, due to the χπ factor. We have that
commutes, i.e. L=Lphys∘Q−1. To see this, note that h∈XQ−1(d) if and only if h⊏d, by an argument analogous to Lemma 6.6, hence Lphys(Q−1(d))=minh⊏dmax~d⊐hL(d)=L(d). Therefore,
EβFD(π)[Lphys∘Q−1]=EβFD(π)[L]=LCop(π), and so by refinement LIBP(π)=EΘ∗U[χπ⋅Lphys]≤EΘ∗FD[χπ⋅Lphys]=LCop(π).□
7.2. Asymptotic behavior of communicating MDPs
This section introduces some general definitions and lemmas in the theory of Markov decision processes. Our main goal here is to state and prove Proposition 7.17, concerning the asymptotic behavior of a communicating MDP. None of these results are to be considered original, but are intended as an overview for the reader, as well as a way to establish the exact form of an asymptotic bound that we need (which we couldn’t find verbatim in the literature).
Definition 7.2. Let a finite Markov decision process (MDP) be given by the following data (cf. [Put94[6] Section 2.1]).
A finite set of states S,
a finite set of actions A,
a transition kernel κ:S×A→ΔS,
and a loss function ℓ:S×A→R.
Remark 7.3. The above setting is not the most general one (for example, we could let the set of actions As depend on the state, or allow the loss function ℓ:S×A→ΔR to be stochastic). The simplifying assumptions we make in the above definition are mostly for the ease of discussion rather than strictly necessary. Some of the results might need additional assumptions in the more general setting, e.g. for Proposition 7.17 we might want to assume that a stochastic ℓ is still bounded.
Definition 7.4. For t∈N, let Ht=(S×A)t×S be the set of histories up to time t,
H=⨆t<THt be histories up to some time horizon T, and Γ=(ΔA)H be the set of (randomized, history-dependent, cf. [Put94[6:1] Section 2.1.4]) policies.
Remark 7.5. We allow randomized policies here, simply because our discussion in this subsection fits naturally with that generality, and also since it seems common to do so in the classical MDP literature. Note however that optimal policies for an MDP can always be chosen to be deterministic, so our discussion is still compatible with the quantum case, where we only allowed deterministic policies (cf. Remark 2.3).
Definition 7.6 (Time evolution of an MDP). For a given policy π:H→ΔA, and an initial state h0∈ΔS, we can define recursively for each t∈N a distribution σπt∈ΔHt as follows. Take σπ0=h0, and consider Htπt−→ΔA. We can then form απt=σπt⋉πt∈Δ(S×A)t+1. Now we can compose (S×A)t+1prt+1−−−→S×Aκ→ΔS, where pri is projection onto the ith factor. Then we can let σπt+1=απt⋉[κ∘prt+1]∈ΔHt+1. We let σπ|σ0:=σπT be the resulting distribution on destinies D=HT,
σπ|σ0∈ΔD. More generally, we can begin with a condition at time k, given by hk∈ΔHk, and follow the time evolution above to a distribution σπ|hk∈ΔD. For a subset U⊂D, we’ll write Pπ[U|hk] for the probability of U, and for a function f:D→R, we’ll write Eπ[f|hk] for the expected value of f with respect to σπ|hk.
Definition 7.7. For t=1,…,T, define ℓt:D→R by ℓt(d)=ℓ(prt(d)). and let Lt:D→R be the total loss Lt=T∑τ=tℓτ.
Definition 7.8. We call an MDP communicating (cf [Put94[6:2] Section 8.3]), if for any pair of states s1,s2∈S, there exists a policy π∈Γ and a time n∈N such that Pπ[prSn(d)=s2|δs1]>0, where prSn extracts the nth state of a destiny. Roughly speaking, a communicating MDP allows navigating between any two states with non-zero probability.
We now have all the definitions involved Proposition 7.17, our main result in this section. In the following, we’ll introduce various definitions and lemmas that we’ll make use of in the proof.
Definition 7.9. For a destiny d∈D and a state s∈S, define θs:D→Z+ by θs(d)=min({θ∈Z+:prSθ(d)=s}∪{T+1}), that is the first time at which state s occurs (or T+1 if s doesn’t occur). Let Arr:S×S→R be given by Arr(s1,s2)=minπ∈ΓEπ[θs2|δs1], that is the minimum expected arrival time to s2, starting from s1.
Lemma 7.10. For a communicating MDP, there is a constant N such that for any time horizon T, Arr(s1,s2)≤N, for all s1,s2∈S.
Proof. Let s1,s2∈S be two states where the maximum maxsi∈SArr(s1,s2) is attained. Since the MDP is communicating, there exists a policy π∈Γ and a time n∈N such that Pπ[prSn(d)=s2|δs1]=p>0. Following this π for n timesteps (assuming n<T, otherwise Arr(s1,s2)≤n/p trivially), we get
Arr(s1,s2)≤∑~s∈SPπ[prSn(d)=~s|δs1](Arr(~s,s2)+n),(1)
by conditioning the state we land on on the nth step. Now,
∑~s∈SPπ[prSn(d)=~s|δs1](Arr(~s,s2)+n)≤⎛⎝∑~s∈S∖{s2}Pπ[prSn(d)=~s|δs1](Arr(~s,s2)+n)⎞⎠+pn≤(1−p)(Arr(s1,s2)+n)+pn,(2)(3)
where (2) follows from the assumption on the policy π arriving to s2 with probability p after n steps, and (3) follows from our assumption on Arr(s1,s2) being maximal (so Arr(~s,s2)≤Arr(s1,s2)). Combining with (1), we get Arr(s1,s2)≤(1−p)(Arr(s1,s2)+n)+pn, so Arr(s1,s2)≤np.□
Definition 7.11. For t∈Z+, let the value functionVt:D→R be given by Vt(d)=minπ∈ΓEπ[Lt|δpr<t(d)], i.e. the minimal expected remaining loss after time t, assuming the state at time t agrees with d. Here pr<t:D→Ht−1 truncates to an initial history.
Remark 7.12. As defined above, the value function depends on the entire history pr<t(d)∈(S×A)t−1×S=Ht−1, up to time t. It turns out (see [Put94[6:3] Theorem 4.4.2.]) that in fact it’s determined by the last state,
st=prSt(d), of this history. By slight abuse of notation, we’ll write Vt:S→R for the resulting function as well.
Lemma 7.13. For a communicating MDP, there exists a constant K, such that for any time horizon T,
maxs∈SVt(s)−mins∈SVt(s)≤K.
Proof. Let s1∈argmaxs∈SVt(s), and s2∈argmins∈SVt(s). By Lemma 7.10,
Arr(s1,s2)≤N, and let π12 be a policy that attains Arr(s1,s2)=minπ∈ΓEπ[θs2|δs1]. Let π∗2 be a policy that attains Vt(s2)=minπ∈ΓEπ[Lt|σt=δs2]. Now construct a policy ~π=‘‘π12⊔π∗2" as follows. In words, ~π follows π12 from s1 until arriving at s2, and from then on follows π∗2. Formally, we can write for a history h∈H, ~π(h)={π12(pr≥t(h)) if prSi(h)≠s2 for any t≤iπ∗2(pr≥k(h)) where k∈N is smallest such that prSt+k(h)=s2. (Note that we use pr≥i as a way of shifting the history in time, for example pr≥3(s1a1s2a2s3a3s4a4s5)=s3a3s4a4s5.) Now, we have Vt(s1)≤E~π[Lt|σt=δs1], and we can write Lt(d)=k−1∑τ=0ℓt+τ+Lt+k, where k∈N is smallest such that prSt+k(d)=s2. Here k−1∑τ=0ℓt+τ≤k⋅maxℓ,Lt+k≤Lt−k⋅minℓ, so E~π[Lt|σt=δs1]≤E~π[θs2|δs1]⋅maxℓ+E~π[Lt|δs2]−E~π[θs2|δs1]⋅minℓ=Eπ∗2[Lt|δs2]+Eπ12[θs2|δs1](maxℓ−minℓ)=Vt(s2)+Arr(s1,s2)(maxℓ−minℓ)≤Vt(s2)+K,
for K=N(maxℓ−minℓ), where N is as in Lemma 7.10. To summarize in words, starting from s1 we can make it to s1 in at most N expected timesteps, accumulating at most N⋅maxℓ loss in expectation. Then we can follow the optimal policy starting at time t+k from s2, and accumulate Vt+k(s2) loss, which is at most k⋅minℓ different from Vt(s2). Putting these together, we get Vt(s1)−Vt(s2)≤K=N(maxℓ−minℓ). □
Lemma 7.14. For any policy π, and any d∈D,
Vt(d)≤Eπ[ℓt+Vt+1|δpr<t(d)].
Proof. By the optimality of Vt(d), we have Vt(d)=mina∈Aqt(st,a), where st=prSt(d) is the tth state, and qt(st,a)=ℓ(st,a)+∑st+1∈SPκ[st+1|st,a]Vt+1(st+1). On the other hand,
Eπ[ℓt+Vt+1|δpr<t(d)]=Ea∼π(d<t)[q(st,a)], i.e. the expected value of qt(st,a) when the action a is distributed according to the policy π(d<t)∈ΔA. The inequality now follows. □
Definition 7.15. Let Dt=ℓt−Vt+Vt+1:D→R.
Lemma 7.16. We have for any policy π and initial state hk∈ΔHk with k<t,
Eπ[Dt|hk]≥0, and |Dt|≤C, for C=maxℓ−minℓ+K, where K is as in Lemma 7.13.
Proof. Since, by Lemma 7.14 we have Eπ[Dt|δh]≥0 for any history h∈Ht−1, the same holds for any distribution of histories, in particular also for the σπt−1∈ΔHt−1 given by the time evolution of hk. We also have mins∈SVt(s)≤Vt≤maxs∈SVt(s),mins∈SVt(s)−maxℓ≤Vt+1≤maxs∈SVt(s)−minℓ, from which |Dt|≤C follows. □
Proposition 7.17. For a communicating MDP, there is a constant C such that for any policy π and initial state h0,
Pπ[L1≤L∗−ϵ|h0]<δ holds whenever ϵ2>2TC2log1δ, where L∗=minπ∈ΓEπ[L1|h0] is the minimal expected loss. In words, it’s unlikely (under any policy and initial state) for the total loss to be much below the minimal expected loss.
Proof. We have L1−V1=T∑t=1Dt, where Yt=∑tτ=1Dτ is a bounded sub-martingale by Lemma 7.16, so by Azuma’s inequality we get Pπ[(L1−V1≤−ϵ)|h0]≤exp(−ϵ22TC2). Since this holds for all h0, and L∗=Eh0[V1], we also get the stated result. □
7.3. Lower bound
We can use the result above to obtain a lower bound on LIBP.
Definition 7.18. Assume we have the setup of a system given in Section 2, and furthermore that O is a complete set of observations (so each Po has a 1-dimensional image). Then given a loss function ℓ:O×A→R≥0, there’s a Markov decision process associated with this setting, where the set of states is S=O, and the transition probabilities κ:S×A→ΔS are given via the Born rule:
Pκ[o2|o1,a]=∥Po2Ua∣∣ψo1⟩∥2, where ∣∣ψo1⟩ is a unit vector in the image of Po1.
Remark 7.19. It might be interesting to also consider the case where O is incomplete. In this case there’s an associated POMDP (partially obvervable Markov decision process). Note, however that a priori this POMDP will have infinitely many states (all rays in the image of Po for each o∈O). We won’t pursue this direction here.
Remark 7.20. To understand the structure of the resulting MDP a little better, consider the following. For two observations o1,o2, let’s say that o1≥o2 (o2 can be reached from o1) if ⟨ψo2∣∣Ua∣∣ψo1⟩≠0 for some a∈A, and take the transitive closure of this relationship. The resulting relationship is in fact also symmetric and reflexive. This follows because the unitary group is compact (since we assume O is a finite and complete set of observations, so He is finite dimensional), so powers of Ua can approximate the identity and U†a=U−1 arbitrarily. Thus the MDP is a disjoint union of communicating components (the equivalence classes of the relation above). For generic {Ua:a∈A}, we’ll have a single equivalence class. Otherwise the first observation picks out a component, and the rest of the evolution remains within that component.
Theorem 7.21. If the associated MDP to a setup is communicating, then for any policy π, we have L∗−O(√TlogT)≤LIBP(π), where L∗ is the minimal Copenhagen loss (i.e.L∗=LCop(π∗) for a Copenhagen-optimal policy π∗).
Proof. For ϵ>0, consider the event E={d∈D:L(d)≤L∗−ϵ}. Choose a policy ~πE as in Definition 6.12. Then it’s easy to verify using the definition of Lphys, that
Lphys(π,{π,~πE})≥L∗−ϵ.(1)
Let p=Cop(E|π) be the Copenhagen probability that the loss is at most L∗−ϵ, given the policy π. By Proposition 7.17 we have that
p≤exp(−ϵ22TC2).(2)
for CE|π=1−√p(2−p). Therefore by (1) and (3), we have
LIBP=EΘ∗U[χπ⋅Lphys]≥(L∗−ϵ)(1−√p(2−p)).
Here p(2−p)≤2p, and using (2), we get
LIBP≥(L∗−ϵ)(1−√2exp(−ϵ24TC2)).
To obtain an O(√TlogT) bound, we can set ϵ=C√2TlogT, which gives LIBP≥(L∗−C√2TlogT)(1−√2T)=L∗−O(√TlogT), since L∗=O(T). □
Note that Theorem 4.26 implies that any Copenhagen-optimal policy is also asymptotically IBP-optimal. The converse is also true, but requires a bit more work.
Theorem 7.22. If ¯π is an IBP-optimal policy, then LCop(¯π)≤L∗+o(T), where L∗ is the Copenhagen-optimal loss.
Proof. For ϵ1,ϵ2>0, consider the events E−ϵ1={d∈D:L(d)≤L∗−ϵ1},E+ϵ2={d∈D:L(d)≤L∗+ϵ2}. On a high level, the proof goes as follows. We already know that the Copenhagen probability of E−ϵ1 is small. We’ll show that for an IBP-optimal ¯π, the complement of E+ϵ2 also has small probability, so most of the probability mass is where the loss is between L∗−ϵ1 and L∗+ϵ2, which will be sufficient to show that LCop(¯π) is not much bigger than L∗.
Choose policies ~π−ϵ1, ~π+ϵ2 corresponding to E−ϵ1 and E+ϵ2 as in Definition 6.12. Let
p1=Cop(E−ϵ1|¯π),p2=Cop(E+ϵ2|¯π),
so p2≥p1. Again, by Proposition 6.18,
C−ϵ1⋅δ¯π,{¯π,~π−ϵ1}∈Θ∗U,C+ϵ2⋅δ¯π,{¯π,~π+ϵ2}∈Θ∗U, where C−ϵ1=1−√p1(2−p1),C+ϵ2=1−√p2(2−p2).
By Lemma 6.11, Proposition 7.24 applies as well, so in this case we also have
ρ=(C−ϵ1−C+ϵ2)⋅δ¯π,{¯π,~π−ϵ1}+C+ϵ2⋅δ¯π,{¯π,~π+ϵ2}∈Θ∗U.
Hence
LIBP(¯π)=EΘ∗U[χ¯π⋅Lphys]≥Eρ[χ¯π⋅Lphys]≥(L∗−ϵ1)(√p2(2−p2)−√p1(2−p1))+(L∗+ϵ2)(1−√p2(2−p2)).(4)
Since ¯π is IBP-optimal, we have for any Copenhagen-optimal policy π∗,
LIBP(¯π)≤LIBP(π∗)≤LCop(π∗)=L∗.(5)
From (4) and (5) together we have (L∗−ϵ1)(√p2(2−p2)−√p1(2−p1))+(L∗+ϵ2)(1−√p2(2−p2))≤L∗. Rearranging, and using √p1(2−p1)≤√2exp(−ϵ214TC2) as before, we get √p2(2−p2)≥1−ϵ1+(L∗−ϵ1)√2exp(−ϵ214TC2)ϵ1+ϵ2, so choosing ϵ1=O(√2TlogT) and ϵ2=O(T5/6), we have √p2(2−p2)≥1−O(√TlogT)Θ(T5/6)=1−O(√logTT1/3). Hence p2≥1−O(4√logTT1/6). Therefore LCop(¯π)≤p2(L∗+ϵ2)+(1−p2)O(T)≤L∗+O(T5/64√logT).□
We can likely improve on the exponent of 5/6 via more sophisticated estimates, but we won’t be needing that for the current level of our discussion.
Remark 7.23. More generally, we can see that an asymptotically Copenhagen-optimal policy is also asymptotically IBP-optimal, and vice versa. In light of Remark 7.20, this remains true even when we drop the assumption of the MDP consisting of a single communicating component. Theorems 7.21 and 7.22 can be applied to each component separately, thus the optimal policies still need to agree asymptotically. The two interpretations then weigh the asymptotic losses of the components differently based on the amplitude of the components in the initial state (the IBP interpretation is more optimistic in the sense that it typically considers the lower loss branches with more weight than the Copenhagen interpretation), hence Theorems 7.21 and 7.22 fail in the case of an initial state that is the superposition of multiple communicating components, but only due to the outcome of the first observation being irreversible in this case, which doesn’t affect the claim about the optimal policies agreeing asymptotically.
We finish this section by spelling out the proof of the following.
Proposition 7.24. If π,π1,π2 are three policies such that for any B∈U,
EβB(π)∧βB(π1)[1]≥C1,EβB(π)∧βB(π2)[1]≥C2, for C1≥C2, then ρ=(C1−C2)⋅δπ,{π,π1}+C2⋅δπ,{π,π2}∈Θ∗U.
Proof. The proof is mostly analogous to Proposition 6.18, we highlight the additional ideas here. The claim reduces to Proposition 6.18 for C1=C2, so we’ll assume C1>C2 in the following. For B∈U, let (cf. Definition 6.14)
¯ϕ2B=βB(π)∧βB(π2),ϕ2B=C2E¯ϕ2B[1]¯ϕ2B, so Eϕ2B[1]=C2, and ϕ2B≤¯ϕ2B≤βB(π2), since E¯ϕ2B[1]≥C2 by assumption. Now let ¯ϕ1B=(βB(π)−ϕ2B)∧βB(π1),ϕ1B=C1−C2E¯ϕ1B[1]¯ϕ1B, so Eϕ1B[1]=C1−C2, and ϕ1B≤¯ϕ1B≤βB(π1), since E¯ϕ1B[1]≥C1−C2 by the assumption that EβB(π)∧βB(π1)[1]≥C1. Moreover, by construction ϕ1B+ϕ2B≤βB(π). We can then define for any finite F⊂U,
ϕ1F=1(C1−C2)|F|−1∏B∈Fϕ1B∈ΔcΦF,ϕ2F=1C|F|−12∏B∈Fϕ2B∈ΔcΦF, so analogously to Lemma 6.16, we have ϕ1F∈βF(π1),ϕ2F∈βF(π2),ϕ1F+ϕ2F∈βF(π). Using this, we can show that θF=δπ,{π,π1}×ϕ1F+δπ,{π,π2}×ϕ2F∈Br(ΘF)⊂Δc(elΓ×ΦF).
To see this, consider an endomorphism s:Γ→Γ, and let ~s be as in Definition 3.12. The interesting cases are the following:
If s(π)=π, then ~s(θF)=δπ×(ϕ1F+ϕ2F)∈ΘF,
since ϕ1F+ϕ2F∈βF(π) by the above.
If s(π)=πi for i=1,2, then ~s(θF)=δπi×ϕiF∈ΘF,
since ϕiF∈βF(πi) as well by the above.
Therefore pr∗(θF)=ρ∈Θ∗F. Since this is true for arbitrary F, we conclude ρ∈Θ∗U. □
8. Limitations
We mention some limitations of the setting, some of which as simply due to the toy nature of the model, others seem to be more inherent to infra-Bayesian physicalism.
8.1. Limitations of the toy setting
Although a central feature of infra-Bayesian physicalism is a lack of privilege for any observer, in the toy model we work with an explicit decomposition of the universe into agent and environment. Other toy assumptions are taking the “computational universe” Γ to consist solely of the policy, and the explicit dependence of the time evolution on the policy. In a more realistic setting we would start with a non-Cartesian (not agent-centric) description of the universe, and a rich nexus of mathematical structure encoded in Γ. The entanglement between the agent’s policy and the physical state of the universe would then be encoded implicitly via a “theory of origin” whereby the agent arises in the given universe.
To spell the above out a little more, in a more realistic setting we could take Σ={⊤,⊥}, and choose R to be a sufficiently rich set of computations to include things like
r= “a program computing the 11th decimal place digit of the amplitude squared of a certain path integral in some lattice QFT and verifying if it’s equal to 7”.
Then Γ=ΣR will contain a lot of immediately inconsistent valuations, like the one where a certain digit is both equal to 7 and to 3. However, we can take a subset Γ0⊂Γ, which is “consistent enough”, e.g. so that for every computation of the form “a certain digit in a given quantity equals i”, exactly one of i∈{0,…,9} evaluates to ⊤, all others evaluate to ⊥. We would choose Γ0 to be sufficiently small to produce a meaningful map β:Γ0→□Φ (describing a certain model of physics), e.g. so that the distribution of the momentum of a given field modeled in Φ, at a point is given as specified by the values of the computations like r above. We can then combine the mathematical/computational part of a hypothesis ΘΓ∈□Γ (supported only on the sufficiently consistent part of the computational universe Γ0⊂Γ) with β to construct a corresponding joint hypothesis Θ=ΘΓ⋉β∈□(Γ×Φ).
The notion of a “theory of origin” has not been formalized yet, but we informally discuss some ingredients here. Given the source code G of the agent, and a policy π, we can define the π-counterfactual of Θ as Θπ=(prelΓ)∗(Br(Θ))∩⊤Cπ∈□elΓ, where Cπ is the subset of universes compatible (by some notion) with the given policy π (cf. [IBP Definition 1.5], also Remark 4.23). We can then look at the diameter of these counterfactuals in some metric,
diam({Θπ:π:O∗→A}), as a measure of the extent to which the agent is realized in the given physical model (i.e. how entangled the agent’s policy is with the world). Moreover, in a more realistic setting we would expect the entanglement between the policy and the world to come from “non-contrived” reasons (as opposed to our toy model, where we just postulated the dependence of the time evolution on the policy), which could be measured by some notion of complexity of the source code G relative to the physical hypothesis β (higher relative complexity means a less contrived theory of origin).
8.2. Limitations of the broader framework
The decision theory of infra-Bayesian physicalism is based on a computationalist loss function L:elΓ→R≥0. So the value of the loss is required to be determined by the state of the computational universe plus the fact of which computations are realized in the physical universe. This can lead to non-trivial translation problems from loss functions that are specified in more traditional terms. Moreover, the computationalist loss function is required to be monotonic (see monotonicity principle in [IBP]) in the computations realized, a requirement not immediately intuitive.
If we wanted to work in a strictly subjectivist framework for the friend, we could include an additional observation of Wigner’s memory tape by the friend, and have the loss function depend on the outcome of that observation. We don’t expect this to make a significant difference for the present discussion.
We could also require that α witness F having observed something, which would correspond to adding the condition that (∀~γ∈α:~γF(o0)=γF(o0)) or (∀~γ∈α:~γF(o1)=γF(o1)). We expect this would change some of the exact expected values of the loss, but not the optimal policy in this case.
Interpreting Quantum Mechanics in Infra-Bayesian Physicalism
This work was inspired by a question by Vanessa Kosoy, who also contributed several of the core ideas, as well as feedback and mentorship.
Abstract
We outline a computationalist interpretation of quantum mechanics, using the framework of infra-Bayesian physicalism. Some epistemic and normative aspects of this interpretation are illuminated by a number of examples and theorems.
1. Introduction
Infra-Bayesian physicalism was introduced as a framework to investigate the relationship between a belief about a joint computational-physical universe and a corresponding belief about which computations are realized in the physical world, in the context of “infra-beliefs”. Although the framework is still somewhat tentative and the definitions are not set in stone, it is interesting to explore applications in the case of quantum mechanics.
1.1. Discussion of the results
Quantum mechanics has been notoriously difficult to interpret in a fully satisfactory manner. Investigating the question through the lens of computationalism, and more specifically in the setting of infra-Bayesian physicalism provides a new perspective on some of the questions via its emphasis on formalizing aspects of metaphysics, as well as its focus on a decision-theoretic approach. Naturally, some questions remain, and some new interesting questions are raised by this framework itself.
The toy setup can be described on the high level as follows (with details given in Sections 2 to 4). We have an “agent”: in this toy model simply consisting of a policy, and a memory tape to record observations. The agent interacts with a quantum mechanical “environment”: performing actions and making observations. We assume the entire agent-environment system evolves unitarily. We’ll consider the agent having complete Knightian uncertainty over its own policy, and for each policy the agent’s beliefs about the “universe” (the joint agent-environment system) is given by the Born rule for each observable, without any assumption on the correlation between observables (formally given by the free product). We can then use the key construction in infra-Bayesian physicalism — the bridge transform — to answer questions about the agent’s corresponding beliefs about what copies of the agent (having made different observations) are instantiated in the given universe.
In light of the falsity of Claims 4.15 and 4.17, we can think of the infra-Bayesian physicalist setup as a form of many-worlds interpretation. However, unlike the traditional many-worlds interpretation, we have a meaningful way of assigning probabilities to (sets of) Everett branches, and Theorem 4.19 shows statistical consistency with the Copenhagen interpretation. In contrast with the Copenhagen interpretation, there is no “collapse”, but we do assume a form of the Born rule as a basic ingredient in our setup. Finally, in contrast with the de Broglie–Bohm interpretation, the infra-Bayesian physicalist setup does not privilege particular observables, and is expected to extend naturally to relativistic settings. See also Section 8 for further discussion on properties that are specific to the toy setting and ones that are more inherent to the framework. It is worth pointing out that the author is not an expert in quantum interpretations, so a lot of opportunities are left open for making connections with the existing literature on the topic.
1.2. Outline
In Section 2 we describe the formal setup of a quantum mechanical agent-environment system. In Section 3 we recall some of the central constructions in infra-Bayesian physicalism, then in Section 4 we apply this framework to the agent-environment system. In Sections 4.2 and 4.3 we write down various statements relating quantities arising in the infra-Bayesian physicalist framework to the Copenhagen interpretation of quantum mechanics. While Section 4.2 focuses on “epistemic” statements, Section 4.3 is dedicated to the “normative” aspects. A general theme in both sections is that the stronger, “on the nose” relationships between the interpretations fail, while certain weaker “asymptotic” relationships hold. In Section 5.1 we construct counterexamples to the stronger claims, and in in Sections 6 and 7 we prove the weaker claims relating the interpretations. In Section 8 we discuss which aspects of our setup are for the sake of simplicity in the toy model, and which are properties of the broader theory.
2. Setup
First, we’ll describe a standard abstract setup for a simplified agent-environment joint system. We have the following ingredients:
A finite set A of possible actions of the agent.
A finite set O of possible observations of the agent. We’ll write E=O×A, the set of observation-action pairs.
For technical reasons it will be convenient to add a symbol 0 for “blank”, and fix a bijection E+=E⊔{0}≅Z/N preserving 0, where N=|O|⋅|A|+1. We’ll use this bijection to treat E+ as an abelian group implicitly.
A Hilbert space He corresponding to states of the environment.
Fix a finite time horizon[1] T∈N. A classical state of a cyclic, length T memory tape is a function τ:Z/T→E+. Let TpT be the set of all classical tape states.
A Hilbert space Hg with orthonormal basis ∣∣ψgτ⟩ for τ∈Tp, corresponding to the quantum state of the agent.
For each a∈A a unitary map of the environment Ua:He→He, describing the “result of the action”.
A projection-valued measure P on O, valued in He (giving projections Po:He→He for each observation o∈O).
Let H=Hg⊗He be the state space of the joint agent-environment system.
Remark 2.1. It would be interesting to consider a setting where the agent is allowed to choose the observation in each step (e.g. have the projection-valued measure P depend on the action taken). For simplicity we’ll work with a fixed observation as described above.
Definition 2.2. Let O≤T=t≤T⨆t∈NOt E≤T=t≤T⨆t∈NEt be the set of observation histories and observation-action histories respectively, i.e. finite strings of observations (resp. observation-action pairs) up to length T. There’s a natural map obs:E≤T→O≤T, extracting the string of observations from a string of observation-action pairs. We’ll call a function π:O≤T→A a policy. For two histories h1,h2 (of either type), we’ll sometimes write h1⊏h2 to mean h1 is a (not necessarily proper) prefix (i.e. initial substring) of h2.
Remark 2.3. We only consider deterministic policies here. It’s not immediately clear how one would generalize Definition 2.7 to randomized policies. In fact, we can always (and is perhaps more principled to) think of our source of randomness for a randomized policy to be included in the environment, so we don’t lose out on generality by only considering deterministic policies. For example, if the source of our randomness is a quantum coin flip, then our approach offers a convenient way of modeling this by including the coin as a factor of He, i.e. part of the environment subsystem.
Definition 2.4. For a tape state τ:Z/T→E+ and an observation-action pair ε∈E, let mem(τ,ε):Z/T→E+ be the state of the tape after writing the pair ε to the tape, defined by mem(τ,ε)(n)={τ(n−1)n≠0τ(−1)+εn=0.
Remark 2.5. Choosing a group structure on E+ is in order to make the map mem(−,ε):Tp→Tp invertible, which in turn makes the map Uoπ in Definition 2.7 unitary.
Definition 2.6. Let the “history extraction” map hist:Tp→E≤T be defined by hist(τ)=(τ(N−1),…,τ(0))∈EN, where 0≤N≤T is largest such that there’s no 0≤n<N with τ(n)=0 (i.e. so that the [0,N) portion of the tape contains no blanks).
Definition 2.7 (Time evolution of a policy). For each policy π:O≤T→A, we define the single time-step unitary evolution operator Uπ on H as the composite of an “observation” and an “action” operator Uπ=UA,π∘UO,π, where UO,π(∣∣ψgτ⟩⊗Po|ψe⟩)=∣∣ψgmem(τ,(o,a))⟩⊗Po|ψe⟩for all o∈OUA,π(∣∣ψgτ⟩⊗|ψe⟩)=∣∣ψgτ⟩⊗Ua|ψe⟩for a=π(obs(hist(τ))) The time evolution after t∈N time-steps is given by Utπ=Uπ∘…∘Uπ, i.e.Uπ composed with itself t times.
Remark 2.8. As defined above, the first step in the evolution is an observation, so we never use the value of the policy on the empty observation string. In this respect it would be more natural to start with an action instead, but it would make some of the notation and the examples more cumbersome, so we sacrifice a bit of naturality for the sake of simplicity overall.
Lemma 2.9. The operator Uπ is unitary on H.
Proof. The operator UA,π is clearly unitary since each Ua is. We can see that UO,π is unitary as follows. Choose an orthonormal basis ∣∣ψeo,i⟩ of PoHe for each o∈O, so together they form an orthonormal basis for He (note that the range of i might vary for varying o). Then ∣∣ψgτ⟩⊗∣∣ψeo,i⟩ forms an orthonormal basis for H, and UO,π permutes this basis, hence is unitary.□
3. Prerequisites
We recall some definitions and lemmas within infra-Bayesianism. This is in order to make the current article fairly self-contained, all the relevant notions here were introducted in [IBP], [BIMT] and [LBIMT]. In particular we omit proofs in this section, all the relevant proofs can be found in the articles listed.
3.1. Ultracontributions
First of all, we work with a notion of belief intended to incorporate a form of Knightian uncertainty. Formally, this means that we work with sets of distributions (or rather “contributions” turn out to be a more flexible tool).
Definition 3.1. Given a finite set X, a contribution μ is a non-negative measure on X, such that μ(X)≤1. We denote the set of contributions ΔcX. A contribution is a distribution if μ(X)=1, so we have ΔX⊂ΔcX.
There’s a natural order on ΔcX, given by pointwise comparison.
Definition 3.2. We call a subset A⊂ΔcX downward closed if for μ∈A, ν≤μ implies ν∈A.
As a subspace of RX, the set ΔcX inherits a metric and a convex structure.
Definition 3.3. We call a closed, convex, downward closed subset Θ⊂ΔcX a homogenious ulta-contribution (HUC for short). We denote the set of HUCs by □X.
We’ll work with HUCs as our central formal notion of belief in this article. The exact properties required (closed, convex and downward closed) should be illuminated by Lemma 3.6.
Definition 3.4. Given a HUC Θ∈□X, and a function f:X→[0,1], we define the expected value EΘ[f]=maxθ∈ΘEθ[f]=maxθ∈Θ∑x∈Xθ(x)f(x).
Thinking of f as a loss function, this is a worst-case expected value, given Knightian uncertainty over the probabilities.
Remark 3.5. It’s worth mentioning that the prefix “infra” originates from the concept of infradistributions, which is the notion corresponding to ultracontributions, in the dual setup of utility functions instead of loss functions. We still often use the term “infra” in phrases such as infra-belief or infra-Bayesianism, but now simply carrying the connotation of a “weaker form” of belief etc., compared to the Bayesian analog.
Lemma 3.6. For Θ∈□X, the expected value defines a convex, monotone, homogeneous functional EΘ[−]:[0,1]X→[0,1].
Lemma 3.7. There is a duality Θ↦EΘ, between □X (i.e. closed, convex, and downward closed subsets of ΔcX) and convex, monotone, and homogeneous functionals [0,1]X→[0,1].
For a functional F:[0,1]X→[0,1], the inverse map in the duality is given by F↦ΘF=⋂f:X→[0,1]{θ∈ΔcX:Eθ[f]≤F[f]}.
3.2. Some constructions
For the current article to be more self-contained, we spell out a few definitions used in this discussion.
Definition 3.8. Given a map of finite sets f:X→Y, we define the pushforward f∗:ΔcX→ΔcY to be given by the pushforward measure. We use the same notation to denote the pushforward on HUCs, f∗:□X→□Y, given by forward image, that is f∗(Θ)={f∗(θ)∈ΔcY|θ∈Θ}. Equivalently, in terms of the expectation values we have for g:Y→[0,1] Ef∗(Θ)[g]=EΘ[g∘f].
Definition 3.9. Given a collection of finite sets Xi, and HUCs Θi∈□Xi, we define the free product ⋈iΘi∈□(∏iXi) as follows. For a contribution θ∈Δc∏iXi we have θ∈⋈iΘi if and only if for each j, (prj)∗(θ)∈Θj⊂ΔcXj, where prj:∏iXi→Xj is projection onto the ith factor.
The free product thus specifies the allowed marginal values, but puts no further restriction on the possible correlations.
Definition 3.10 (Total uncertainty). The state of total (Knightian) uncertainty ⊤X∈□X is defined as ⊤X=ΔcX, i.e. the subset of all contributions.
Definition 3.11 (Semidirect product). Given a map β:X→□Y, and an element Θ∈□X, we can define the semidirect product Θ⋉β∈□(X×Y). This is easier to write down in terms of the expectation functionals, as follows. For g:X×Y→[0,1], define EΘ⋉β[g]=EΘ[Eβ(x)[g(x,−)]]. Here Eβ(x)[g(x,−)] is the function X→[0,1], whose value at x∈X is given by by taking expected value with respect to β(x)∈□Y of the function g(x,−):Y→[0,1].
As a subset of Δc(X×Y), ⊤X⋉β can be understood as the convex hull of the δx×θ for all x∈X and all θ∈β(x)⊂ΔcY. For Θ⋉β one needs to further restrict to contributions that project down into Θ⊂ΔcX.
3.3. The bridge transform
The key construction we’ll be considering in infra-Bayesian physicalism is the bridge transform. This construction is aimed at answering the question “given a belief about the joint computational-physical universe, what should our corresponding belief be about which computations are realized in the physical universe?”.
We’ll discuss these notions in a bit more detail, but for now both the physical universe Φ and the computational universe Γ are just assumed to be finite sets.
Definition 3.12. Given Θ∈□(Γ×Φ), the bridge transform of Θ, Br(Θ)∈□(Γ×2Γ×Φ) is defined as follows (cf. [IBP Definition 1.1]). For a contribution θ∈Δc(Γ×2Γ×Φ) we have θ∈Br(Θ) if and only if for any s:Γ→Γ, under the composite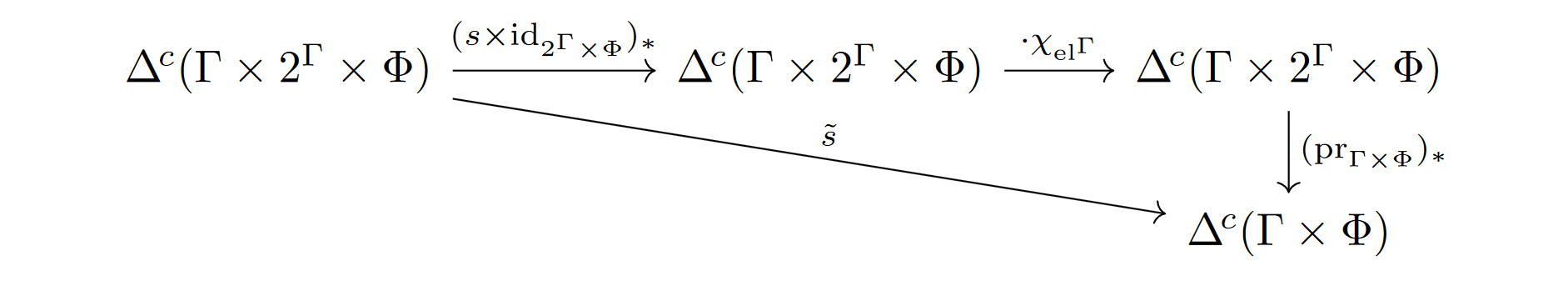
Remark 3.13. The use of all endomorphism s:Γ→Γ in Definition 3.12, although concise, doesn’t feel fully principled as of now. We would typically think of the computational universe Γ as the set of all possible assignments of outputs to programs, i.e. Γ=ΣR, for a certain output alphabet Σ, and a set of programs R (see Definition 4.1). In this context, ΓΓ feels somewhat unnatural. That being said, in the current discussion we mainly use the fact that ΓΓ acts transivitely on Γ, so it’s possible that these results would survive in some form under a modified definition of the bridge transform.
For easy reference, we spell out [IBP Proposition 2.10]:
Lemma 3.14 (Refinement). Given a mapping between physical universes f:Φ1→Φ2, we have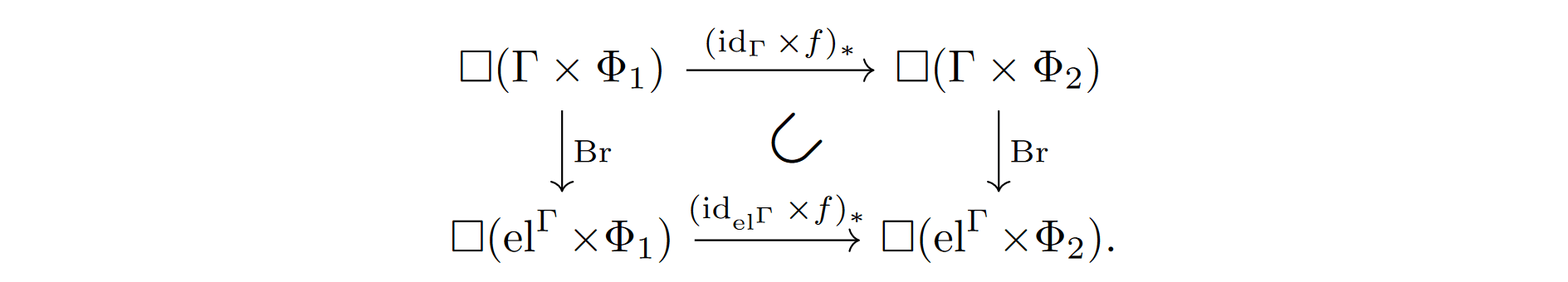
4. An infra-Bayesian physicalist interpretation
We’ll work with a certain specialized setup of [IBP].
Definition 4.1. Let the set of “programs” R=O≤T, the “output alphabet” Σ=A, and the set of “computational universe states” Γ=ΣR=AO≤T be the set of policies up to time horizon T. We’ll write elΓ={(π,α)∈Γ×2Γ:π∈α}.
Definition 4.2. Let a “universal observable” B be a triple (VB,QB,tB), where VB is a finite set (of “observation outcomes”), QB is a projection-valued measure on VB, valued in H (giving projections QB(v):H→H for each v∈VB), and an “observation time” tB∈N<T. Let U be the set of all universal observables, up to the natural notion of equivalence.
Remark: We use the term “universal observable” here to distinguish between observables of the “universe” (i.e. the joint agent-environment system) from the observations of the environment by the agent.
Definition 4.3 (Initial state). Fix a normalized (norm 1) initial state ∣∣ψe0⟩∈He of the environment, and let ∣∣ψg0⟩ be the state of the agent corresponding to an empty memory tape, i.e.τ:Z/T→E given by τ(n)=0 for all n. Let |ψ0⟩=∣∣ψg0⟩⊗∣∣ψe0⟩∈H be the initial state of the joint system.
Definition 4.4. For a policy π∈Γ, let the marginal distribution of the universal observable B be defined according to the Born rule: βB(v|π)=∥QB(v)UtBπ|ψ0⟩∥2. I.e. the norm square of the vector obtained by evolving the universe following policy π for tB time-steps from the initial state, and then projecting onto the observation subspace corresponding to the universal observation v∈VB. So βB(−|π)∈ΔVB.
Definition 4.5. Let ΦU=∏B∈UVB be the set of “all possible states of the universe” (more precisely the set of all possible outcomes of all observations on the joint agent-environment system). More generally, define ΦS analogously for any subset S⊂U.
Definition 4.6. For a finite subset F⊂U, let βF(π)=⋈B∈FβB(−|π)∈□ΦF be the free product of the βB, as defined in Definition 3.9. For varying π this defines an ultrakernel βF:Γ→□ΦF, and the associated semidirect product ΘF=⊤Γ⋉βF∈□(Γ×ΦF). Taking the bridge transform and projecting out the physical factor ΦF: □(Γ×ΦF)Br−→□(Γ×2Γ×ΦF)pr∗−−→□(Γ×2Γ), we get Θ∗F=pr∗(Br(ΘF))∈□(Γ×2Γ).
If F1⊂F2⊂U, we have a natural “refinement” map p:ΦF2→ΦF1, given by projecting out the additional factors in ΦF2. By Lemma 3.14, we have
Definition 4.7. Let Θ∗U=⋂F⊂UΘ∗F, where the intersection is over all finite subsets of U.
4.1. Copenhagen interpretation
Definition 4.8. Let h∈E≤T be an observation-action history, and denote by Qh:H→H the projection corresponding to the proposition “the memory tape recorded history h”. More precisely Qh=Qgh⊗idHe, where Qgh∣∣ψgτ⟩={∣∣ψgτ⟩if hist(τ)=h0otherwise.
Definition 4.9. Given a sequence of observation-action pairs h∈En, let h≤m∈E≤m denote the truncated history (i.e. the image under projecting out the last n−m components of En if n>m, and h itself if n≤m).
In the Copenhagen interpretation the “universe” (i.e. the joint system of the agent and the environment) collapses after each observation of the agent.
Definition 4.10. Given a policy π:O≤T→A, the initial state |ψ0⟩∈H, and a sequence of observation-action pairs h∈En, we can define |ψt⟩=Qh≤tUπ|ψt−1⟩ for t>0 recursively. Then according to the Copenhagen interpretation, the probability of observing h is Cop(h|π)=∥|ψn⟩∥2.
Lemma 4.11. Collapsing at each step is the same as collapsing at the end, that is |ψt⟩=Qh≤tUtπ|ψ0⟩.
Proof. The claim is true for t=0,1 by definition. Assume it’s true for t−1, so |ψt−1⟩=Qh≤t−1Ut−1π|ψ0⟩. Let’s write Ut−1π|ψ0⟩=∑τ∈Tp∣∣ψgτ⟩⊗|φeτ⟩, so |ψt−1⟩=∑τ∈Tphist(τ)=h≤t−1∣∣ψgτ⟩⊗|φeτ⟩. Then if a=π(obs(h≤t−1))∈A, we have |ψt⟩=∑τ∈Tphist(τ)=h≤t∣∣ψgτ⟩⊗Ph(t)Ua|φeτ⟩, while Utπ|ψ0⟩=∑τ∈Tpo∈O∣∣ψgmem(τ,(o,a))⟩⊗PoUπ(hist(τ))|φeτ⟩. Now Qh≤t∣∣ψgmem(τ,(o,a))⟩=0 unless (o,a)=h(t) and hist(τ)=h≤t−1, hence Qh≤tUtπ|ψ0⟩=|ψt⟩ as claimed.□
4.2. Relating the two interpretations
Since Θ∗U∈□elΓ, we can take expectations of functions f:elΓ→[0,1], in particular indicator functions χq for q⊂elΓ.
Definition 4.12. For a policy π∈Γ, and a tuple of observations h∈On, define αh|π={γ∈Γ|γ(h)=π(h)}⊂Γ, and let qh|π={(π,α)∈elΓ|α⊂αh|π}⊂elΓ.
Remark 4.13. In what follows we’ll assume |A|>1. This assures that the set of policies is richer than the set of histories (i.e. |Γ|>|O≤T|). Much of the following fails in the degenerate case |A|=1.
When considering the infra-Bayesian physicalist interpretation of a quantum event h, we’ll consider the expected value EΘ∗U[χπ(1−χqh|π)]. As defined in Definition 4.6, ΘU can be thought of as the infra-belief ⊤Γ⋉βU∈□(Γ×ΦU), which is a joint belief over the computational-physical world, with complete Knightian uncertainty over the policy of the agent (as a representation of “free will”), and for each policy the corresponding belief about the physical world is as given by the unitary quantum evolution of the agent-environment system under the given policy. The bridge transform Θ∗U∈□elΓ of ΘU then packages the relevant beliefs about which computational facts are manifest in the physical world. The subset αh|π corresponds to the proposition “the policy outputs action a=π(h) upon observing h”, and hence qh|π corresponds to the belief “the physical world witnesses the output of the policy on h to be a=π(h) (which is to say there’s a version of the agent instantiated in the physical world that observed history h, and acted a)”. We’ll be investigating various claims about the quantity EΘ∗U[χπ(1−χqh|π)], which is the ultraprobability (i.e. the highest probability for the given Knightian uncertainty) of the agent following policy π and h not being observed (i.e. no agent being instantiated acting on history h).
Remark 4.14. It might at first seem more natural to consider the complement instead, that is χπχqh|π, which corresponds to the agent following policy π, and history h being observed. However, it turns out that EΘ∗U[χπχqh|π]=1 always. This can be understood intuitively via refinement (see Lemma 3.14): we can always extend our model of the physical world to include a copy of the agent instantiated on history h, so the highest probability of h being observed will be 1. This is also related to the monotonicity principle discussed in [IBP]. Thus although at first glance this might seem less natural, in our setup it’s more meaningful to study the ultraprobability of the complement, i.e. of h not being observed. Note that since we’re working with convex instead of linear expectation functionals (see Lemma 3.7), the complementary ultraprobabilities will typically sum to something greater than one.
We first state Claims 4.15 and 4.17 relating the IBP and Copenhagen interpretations “on the nose”, which both turn out to be false in general. Then we state the weaker Theorem 4.19, which is true, and establishes a form of asymptotic relationship between the two interpretations.
Claim 4.15. The two interpretations agree on the probability that a certain history is not realized given a policy. That is, EΘ∗U[χπ(1−χqh|π)]=1−Cop(h|π).
This claim turns out to be false in general, and we give a counterexample in Counterexample 5.3. Note, however, that the claim seems to be true in the limit with many actions (i.e. |A|→∞), which would warrant further study. Now consider the following definition concerning two copies of the agent being instantiated.
Definition 4.18. For a policy π∈Γ, and two tuples of observations h1,h2∈On, define αh1,h2|π={γ∈Γ|γ(hi)=π(hi) for i=1,2}⊂Γ, and let qh1,h2|π={(π,α)∈elΓ|α⊂αh1,h2|π}⊂elΓ.
Claim 4.17. There is only one copy of the agent (i.e. the agent is not instantiated on multiple histories, there are no “many worlds”). That is, if neither of h1,h2∈On is a prefix of the other, then EΘ∗U[χπ(1−χqh1,h2|π)]=1.
This claim is the relative counterpart of Claims 4.15 and fails as well in general (see Counterexample 5.5). Again, however, this claim might hold in the |A|→∞ limit.
Definition 4.18. An event is a subset of histories E⊂OT. We define the corresponding qE|π=⋃h∈Eqh|π⊂elΓ, and Cop(E|π)=∑h∈ECop(h|π).
Theorem 4.19. The ultraprobability of an agent not being instantiated on a certain event can be bounded via functions of the (Copenhagen) probability of the event. More precisely, 1−√(2−Cop(E|π))Cop(E|π)≤EΘ∗U[χπ(1−χqE|π)]≤1−Cop(E|π).
Proof. We prove the upper bound in Section 6.1 and the lower bound in Section 6.2. □
Due to the failure of Claims 4.15 and 4.17, we can think of the infra-Bayesian physicalist setup as a form of many-worlds interpretation. However, since √(2−Cop(E|π))Cop(E|π)→0 as Cop(E|π)→0, the above Theorem 4.19 shows statistical consistency with the Copenhagen interpretation in the sense that observations that are unlikely according to the Born rule have close to 1 ultraprobability of not being instantiated (while very likely observations have close to 0 ultraprobability of uninstantiation).
Remark 4.20. For simplicity we assumed E only contains entire histories (i.e. ones of maximal length T). It’s easy to modify the definitions to account for partial histories. The inequalities in Theorem 4.19 remain true even if E includes partial histories, and the proofs are easy to adjust. We avoid doing this here in order to keep the notation cleaner. However, it’s worth noting some important points here. For a partial history h, let H⊂OT be the set of all completions of h, i.e.H={~h∈OT:h⊏~h}. Then we have Cop(h|π)=Cop(H|π)=∑~h∈HCop(~h|π). On the other hand, qh|π≠qH|π=⋃~h∈Hq~h|π, so there is an important difference here between the two interpretations, which would warrant further discussion. In particular, under the infra-Bayesian physicalist interpretation it can happen that EΘ∗U[χπ(1−χqH|π)]>EΘ∗U[χπ(1−χqh|π)] for a partial history h and its set of completions H. This could be loosely interpreted as Everett branches “disappearing”, as the ultraprobability of an agent not being instantiated on the partial history h is less than that of the agent not being instantiated on any completion of that history.
4.3. Decision theory
To shed more light on the way the infra-Bayesian physicalist interpretation functions, it is interesting to consider the decision theory of the framework, along with the epistemic considerations above.
Definition 4.21. Consider a loss function L:D→R≥0, where D=ET is the set of destinies. We can then construct the physicalized loss function (cf. [IBP Definition 3.1]) Lphys:elΓ→R≥0, given by Lphys(γ,α)=minh∈Xαmaxd∈Dh⊏dL(d), where Xα is the set of histories witnessed by α, that is Xα={h∈E≤T|∀ga⊏h,∀~γ∈α:~γ(obs(g))=a}. Note that in our simplified context, Lphys(γ,α) doesn’t depend on γ.
Definition 4.22. We can define the worst-case expected physicalized loss associated to a policy π by LIBP(π)=EΘ∗U[χπ⋅Lphys]. Under the Copenhagen model, we would instead simply consider LCop(π)=ECop[L|π]=∑d∈DCop(d|π)L(d).
Remark 4.23. Given a policy π∈Γ, we can consider the set of “fair” counterfactuals (cf. [IBP Definition 1.5]) Cπfair={(γ,α)∈elΓ|∀h∈O≤T:(∀~γ∈α,∀~h⊏h:~γ(~h)=γ(~h))⟹γ(h)=π(h)}, i.e. where if α witnesses the history h, then γ agrees with π on that history. This definition is in contrast with the “naive” counterfactuals we considered above (when writing χπ): Cπnaive={(γ,α)∈elΓ|γ=π}. In Definition 4.22 above, and generally whenever we use χπ, we could have used the indicator function of Cπfair instead. The choice of counterfactuals affects the various expected values, however, all of the theorems in this article remain true (and Claims 4.15 and 4.17 remain false) for both naive and fair counterfactuals. We thus work with naive counterfactuals for the sake of simplicity.
Similarly to Section 4.2, the “on the nose” claim relating the two interpretations fails, but we have an asymptotic relationship which holds.
Claim 4.24. The two interpretations agree on the loss of any policy: LIBP(π)=LCop(π).
Again, this turns out to be false, and we give a simple counterexample in Counterexample 5.6.
To allow discussing the asymptotic behavior, assume now that we incur a loss at each timestep, given by ℓ:E=O×A→R≥0, and we consider the total loss L=T∑t=1ℓt:D→R≥0. We might hope that we could have at least the following.
Claim 4.25. The two interpretations agree on the loss of any policy asymptotically: LIBP(π)∼LCop(π), i.e. the difference is bounded sublinearly in T.
This claim is still false in general for essentially the same reason as Claim 4.24 since certain policies might involve a one-off step that then affect the entire asymptotic loss. We give a detailed explanation in Counterexample 5.7. We do however have the following.
Theorem 4.26. If the resulting MDP is communicating (see Definition 7.8), then for any policy π we have LCop(π∗)−o(T)≤LIBP(π)≤LCop(π), where π∗ is a Copenhagen-optimal policy. In particular, optimal losses for the IBP and Copenhagen frameworks agree asymptotically.
Proof. See Theorem 7.1 for the upper bound and Theorem 7.21 for the lower bound. □
5. Examples
We’ll look at a few concrete examples in detail, firstly to gain some insight into how Claims 4.15 and 4.17 fail in general, and secondly to see how our framework operates in the famously puzzling Wigner’s friend scenario.
5.1. Counterexamples
We’ll construct simple counterexamples to Claims 4.15 and 4.17 in the smallest non-degenerate case, i.e. when |O|=2 and |A|=2, and T=1. Let O={o0,o1} and A={a0,a1}. There are four policies in this case (ignoring the value of the policies on the empty input, which is irrelevant in our setting, see Remark 2.8), which we’ll abbreviate as π00,π01,π10,π11, where πij(o0)=aiπij(o1)=aj. Assume h=o0, and π=π00, so αh|π={π00,π01}.
Recall [IBP Lemma 1]:
Lemma 5.1. For ρ∈ΔcelΓ×Φ, we have ρ∈Br(Θ) if and only if for each s:Γ→Γ and g:Γ×Φ→[0,1] Eρ[~g]≤EΘ[g], where ~g:elΓ×Φ→[0,1] is given by γ,α,x↦χs(γ)∈α⋅g(s(γ),x).
Lemma 5.2. Let β:Γ→ΔΦ be a kernel, Θ=⊤Γ⋉β, and Θ∗=pr∗(Br(Θ)) as above. Then EΘ∗[χπ(1−χqh|π)]=E(β(π10)+β(π11))∧β(π00)[1].
Proof. To obtain a lower bound (although we’ll only use the upper bound for the counterexample), define the contribution ρ∈Δc(elΓ×Φ) by ρ=δπ00,{π00,π10}×ϕ10+δπ00,{π00,π11}×ϕ11, where ϕ10,ϕ11∈ΔcΦ are such that ϕ10≤β(π10), ϕ11≤β(π11), and ϕ10+ϕ11=(β(π10)+β(π11))∧β(π00). One possible such choice is ϕ10=β(π10)∧β(π00) ϕ11=β(π11)∧(β(π00)−ϕ10). Then it’s easy to verify that ρ∈Br(Θ), and Eρ[χπ(1−χqh|π)]=E(β(π10)+β(π11))∧β(π00)[1]. To obtain an upper bound, fix x0∈Φ, and use Lemma 5.1 for constant s=π00, and g(γ,x)=χγ=π00⋅χx=x0. We have ~g(γ,α,x)=χπ00∈α⋅g(π00,x)=χπ00∈α⋅χx=x0, and so Eρ[χπ00∈α⋅χx=x0]=Eρ[~g]≤EΘ[χγ=π00⋅χx=x0]=Eβ(π00)[χx=x0].(1) Analogously for π10 and π11 we get Eρ[χπ10∈α⋅χx=x0]≤EΘ[χγ=π10⋅χx=x0]=Eβ(π10)[χx=x0],(2) and Eρ[χπ11∈α⋅χx=x0]≤EΘ[χγ=π11⋅χx=x0]=Eβ(π11)[χx=x0].(3)
Now, χπ(1−χqh|π)χx=x0≤χπ00∈α⋅χx=x0, so by (1) we get Eρ[χπ(1−χqh|π)χx=x0]≤Eβ(π00)[χx=x0].(4)
We also have 1−χqh|π≤χπ10∈α+χπ11∈α, since π10∉α and π11∉α together would imply α⊂αh|π00. Thus χπ(1−χqh|π)χx=x0≤(χπ10∈α+χπ11∈α)⋅χx=x0, so adding (2) and (3), we obtain Eρ[χπ(1−χqh|π)χx=x0]≤Eβ(π10)+β(π11)[χx=x0].(5) Now, since both (4) and (5) hold, we get Eρ[χπ(1−χqh|π)χx=x0]≤E(β(π10)+β(π11))∧β(π00)[χx=x0]. Finally, summing over x0∈Φ we have the required upper bound EΘ∗[χπ(1−χqh|π)]=E(β(π10)+β(π11))∧β(π00)[1]. □
Counterexample 5.3. Let He be a qubit state space, and ∣∣ψe0⟩=|+⟩=1√2(|0⟩+|1⟩). Let Ua0=Ua1=idHe. Let the observation P correspond to measuring the qubit, so Po0,Po1 are projections onto |0⟩ and |1⟩ respectively. Then Claim 4.15 fails in this setup.
Proof. We have |ψ0⟩=∣∣ψg0⟩⊗∣∣ψe0⟩=|0⟩⊗1√2(|0⟩+|1⟩), and so Uπ00|ψ0⟩=1√2(|o0a0⟩⊗|0⟩+|o1a0⟩⊗|1⟩), Uπ10|ψ0⟩=1√2(|o0a1⟩⊗|0⟩+|o1a0⟩⊗|1⟩), Uπ11|ψ0⟩=1√2(|o0a1⟩⊗|0⟩+|o1a1⟩⊗|1⟩). Now consider the universal observable B which is measurement along the vector |v⟩ and its complement, where |v⟩=12√3(3|o0a0⟩⊗|0⟩+|o1a0⟩⊗|1⟩−|o0a1⟩⊗|0⟩+|o1a1⟩⊗|1⟩) I.e. we have VB={v,v⊥}, and QB(v)=Pv, QB(v⊥)=Pv⊥, where Pv, Pv⊥ are projections in H=Hg⊗He onto |v⟩ and its ortho-complement respectively. Then we have the following values for βB for the various policies:
This can be seen by noticing that |v⟩ is perpendicular to both Uπ10|ψ0⟩ and Uπ11|ψ0⟩, while ⟨v∣∣Uπ00ψ0⟩=2√6, so βB(v|π00)=|⟨v∣∣Uπ00ψ0⟩|2=23. This means that for this B we have (βB(π10)+βB(π11))∧βB(π00)[1]=1/3. If FB={B}, by Lemma 5.2 we have EΘ∗FB[χπ(1−χqh|π)]=E(βB(π10)+βB(π11))∧βB(π00)[1]=1/3. Now, by definition Θ∗U⊂Θ∗FB, so we also have EΘ∗U[χπ(1−χqh|π)]≤1/3<1−Cop(h|π)=12. □
Although we won’t need the exact value here, we remark to the interested reader that in the above setup of Counterexample 5.3, the ultraprobability attains the lower bound of Theorem 4.19, that is EΘ∗U[χπ(1−χqh|π)]=1−√3/4≈0.134.
We can extend the above counterexample to apply to Claim 4.17, via the following.
Lemma 5.4. Let β:Γ→ΔΦ be a kernel, Θ=⊤Γ⋉β, and Θ∗=pr∗(Br(Θ)) as above. Then for h1=o0, h2=o1, EΘ∗[χπ(1−χqh1,h2|π)]=E(β(π10)+β(π01)+β(π11))∧β(π00)[1].
Proof. Analogous to Lemma 5.2. □
Counterexample 5.5. In the setup of Counterexample 5.3, Claim 4.17 fails too, that is EΘ∗[χπ(1−χqh1,h2|π)]<1.
Proof. Consider projecting onto the three vectors |v1⟩=Uπ00|ψ0⟩=1√2(|o0a0⟩⊗|0⟩+|o1a0⟩⊗|1⟩), |v2⟩=Uπ11|ψ0⟩=1√2(|o0a1⟩⊗|0⟩+|o1a1⟩⊗|1⟩), and |v3⟩=1√2(Uπ01|ψ0⟩−Uπ10|ψ0⟩)=12(|o0a0⟩⊗|0⟩−|o1a0⟩⊗|1⟩+|o0a1⟩⊗|0⟩−|o1a1⟩⊗|1⟩). Then the corresponding probabilities are
So we have E(βB(π10)+βB(π01)+βB(π11))∧βB(π00)[1]=1/2<1. Then again, by refinement, this implies that EΘ∗[χπ(1−χqh1,h2|π)]≤1/2<1 as well. □
Counterexample 5.6. Claim 4.24 fails in the setup of Counterexample 5.3, with loss given by ℓ:O×A→R≥0, ℓ(o,a)={0 if o=o01 if o=o1.
Proof. In this case Lphys(γ,α)={0 if ∀~γ∈α:~γ(o0)=γ(o0)1 otherwise. Notice that for this Lphys we actually have χπ⋅Lphys=χπ(1−χqo0|π), so by the considerations in Counterexample 5.3, we also have (for any policy π) LIBP(π)≤1/3<1/2=LCop(π), showing failure of Claim 4.24. □
Counterexample 5.7. The setup of Counterexample 5.6, run over time horizon T instead of just a single timestep shows the failure of the asymptotic claim Claim 4.25 in general.
Proof. The point is that in this setup the entire loss is determined by the outcome of the first observation: if we observe o0, we’ll incur 0 loss during the entire time, while if we observe o1 first, we’re “stuck” in that state, and hence incur a total loss equal to T. Due to this, we have LIBP(π)≤T3⋦T2=LCop(π), for any policy π. □
Note that in the above setup, we get “stuck” in the states after the initial observation because the MDP itself is not communicating. However, even for communicating MDPs (for example if we choose Ua1 to be a rotation by π/4) certain policies will get stuck (for example the policy that always chooses a0 corresponding to Ua0=id). So we see this behavior whenever the asymptotic loss is dependent on a few initial steps. On the other hand, for example if π is a stationary policy, and the resulting Markov chain is irreducible, then we can obtain a concentration bound on the loss (e.g. via the central limit theorem, [Dur96[2], 5.6.6.]), and use an argument similar to Theorem 7.21 to show that LIBP and LCop indeed agree asymptotically under such assumptions.
5.2. Wigner’s friend
We’ll consider a scenario originally attributed to Wigner, and we’ll work in an extension of the setting introduced in [BB19[3]]. For brevity, we’ll omit detailed computations in this section and focus on the higher level ideas instead. Consider a joint system consisting of three parts, a spin-12 particle S, a friend F in a lab, making observations of S, and Wigner W making observations of the lab (the joint friend-particle system FS).
Now let’s assume F follows the constant policy πF00(oFi)=aF0 (for i=0,1). Then Wigner will observe L+00 with probability 1. Yet, if the friend F believes that having observed oFi, the state of the lab collapsed to ∣∣oFiaF0⟩F|i⟩S, then the friend would expect Wigner to observe L+00 or L−00 with probability 12 each. Thus, within collapse theories we have an apparent conflict between the predictions of Wigner and the friend.
We can model this scenario within IBP by taking Γ=ΓF×ΓW=AOFF×AOWW be the pairs of policies of Wigner and the friend. Analogously to Definition 4.6 we can define ΦU as the joint outcome of all observables on the joint triple system WFS, a kernel βU:Γ→□ΦU, and the corresponding belief ΘU=⊤Γ⋉βU∈□(Γ×ΦU), and its projected bridge transform Θ∗U∈□elΓ. To be more precise we would again build this out of finite subsets of U, as in Definition 4.7.
Given this setup, we can write down various definitions. For hW∈OW, let αhW|πW={(γF,γW)∈Γ|γW(hW)=πW(hW)}∈2Γ, qhW|πW={α∈2Γ|α⊂αhW|πW}⊂2Γ. Then we can compute EΘ∗U[χπF00,πW(1−χqL+00|πW)]=0, i.e. the observation L+00 of Wigner is certain to be instantiated if F follows the policy πF00.
We can also write down other quantities, for example for hF∈OF, hW∈OW, we can define αhF,hW|πF,πW={(γF,γW)∈Γ|γW(hW)=πW(hW),γF(hF)=πF(hF)}∈2Γ, and the analogous qhF,hW|πF,πW. The quantity EΘ∗U[χπF00,πW(1−χqo0,L+00|πF00,πW)] would then be the ultraprobability of the pair (W observing L+00, F observing o0) being uninstantiated. We can estimate the value of this ultraprobability using techniques similar to Section 6 to be around 0.35.
This setting is helpful to differentiate the decision theory of IBP from a collapse theory. For example, consider a loss function ℓ:OW→R≥0 that depends only on Wigner’s observation, with values: ℓ(L+00)=0,ℓ(L−00)=1,ℓ(L+11)=0.1,ℓ(L−11)=0.1. Now suppose the friend is trying to minimize ℓ.[4] Then assuming a unitary evolution of the lab, clearly πF00 is the optimal policy. However, if the friend assumes a collapse of the lab after her observation, then always choosing action aF1∈AF avoids ever having an overlap with the high-loss L−00, making the constant aF1 policy πF11∈ΓF optimal under the collapse interpretation.
We can consider this decision problem within IBP by working with the physicalized loss function ℓphys:elΓ→R≥0 (cf. Definition 4.21), given by [5] ℓphys(γ,α)=⎧⎪ ⎪ ⎪ ⎪⎨⎪ ⎪ ⎪ ⎪⎩0 if ∀~γ∈α:~γW(L+00)=γW(L+00)0.1 else if ∀~γ∈α:~γW(L+11)=γW(L+11)0.1 else if ∀~γ∈α:~γW(L−11)=γW(L−11)1 otherwise. Then in IBP the friend would look for the policy minimizing the loss ℓIBP(πF)=EΘ∗U[χπF⋅ℓphys]. We can verify that the minimal loss ℓIBP(πF)=0 occurs exactly when πF=πF00 as expected, in contrast with the collapse interpretation.
6. Bounds on the ultraprobabilities
We’ll make use of the following observation.
Lemma 6.1. For a given history h∈Ot, if two policies π1,π2∈Γ agree on all prefixes of h, i.e. π1(~h)=π2(~h) for all ~h⊏h, then QhUtπ1|ψ0⟩=QhUtπ2|ψ0⟩, where Qh is the projection corresponding to the observation obs(τ)=h, i.e. the memory tape having recorded h.
Proof. For t=1 we have Uπ1|ψ0⟩=∑o∈O|oπ1(o)⟩⊗Uπ1(o)Po∣∣ψe0⟩, and similarly for π2. Now for h=oi we have QhUπ1|ψ0⟩=|oiπ1(oi)⟩⊗Uπ1(oi)Poi∣∣ψe0⟩=QhUπ2|ψ0⟩, since π1(h)=π2(h) by assumption. For t>1 we can proceed by induction, using Lemma 4.11. □
6.1. Upper bound
To prove an upper bound on the expectation value, we can coarsen our set of physical states to only include measurements of the memory tape.
Let D=ET⊂TpT be the set of destinies.
Definition 6.2. Let BD be the universal observable corresponding to reading the destiny off the memory tape at time tBD=T. That is, VBD=D, and for d∈D QBD(d):Hg→Hg is given by ∣∣ψgτ⟩⊗|ψe⟩↦{∣∣ψgτ⟩⊗|ψe⟩if τ=d0otherwise.
Definition 6.3. Let Q⊂Γ×D be the relation of a destiny being compatible with a policy. That is, (π,d)∈Q for d=(o1,a1,…,oT,aT) if and only if ai=π(o1,…,oi) for each 1≤i≤T.
Let FD={BD}, and note that ΦFD=VBD=D. Let βFD:Γ→ΔD be the corresponding kernel.
Lemma 6.4. The kernel βFD:Γ→ΔD is a PoCK for Q.
Proof. This is essentially saying that whenever π1,π2∈Γ are both compatible with a destiny d∈D, then βFD(d|π1)=βFD(d|π2). This claim follows by Lemma 6.1. □
Then by [IBP Proposition 4.1] we have
Lemma 6.5. The bridge transform equals Br(ΘFD)=[⊤Γ⋉(Q−1⋊βFD)]↓. In particular, for a monotone increasing (in 2Γ) function f:Γ×2Γ→[0,1], we have EΘ∗FD[f]=maxγ∈ΓEβFD(γ)[f(γ,−)∘Q−1].(1)
For g=χqE|π (note that g is monotone decreasing) and d∈D we have g(γ,−)∘Q−1(d)=1 if
γ=π,
π∈Q−1(d), and
Q−1(d)⊂αh|π for some h∈E.
Lemma 6.6. We have Q−1(d)⊂αh|π if and only if h=obs(d) and aT=π(h) (where d=(o1,a1,…,oT,aT) as before).
Proof. If h=obs(d) and aT=π(h), then (γ,d)∈Q implies γ(h)=aT=π(h), so Q−1(d)⊂αh|π.
For the converse, assume Q−1(d)⊂αh|π. First choose γ∈Q−1(d) (which is always non-empty). In particular γ(h)=aT, so γ∈αh|π means π(h)=aT as well.
Now assume h≠obs(d). Then choose γ′∈Γ as follows. For ~h∈O≤T, let γ′(~h)=⎧⎪⎨⎪⎩ai if ~h=(o1,…,oi)~aT≠aT if ~h=ha1(arbitrary) otherwise. Then γ′∈Q−1(d)∖αh|π, contradiction. □
We therefore have EβFD(γ)[χqE|π(γ,−)∘Q−1]=⎧⎪ ⎪⎨⎪ ⎪⎩∑h∈E∑d∈Q(π)h=obs(d)βFD(π)(d)if γ=π0otherwise. Here ∑h∈E∑d∈Q(π)h=obs(d)βFD(π)(d)=Cop(E|π), so by applying (1) of Lemma 6.5 to the monotone increasing f=χπ(1−χqE|π), we have EΘ∗FD[χπ(1−χqE|π)]=1−Cop(E|π), since χπ(γ,α)=0 whenever γ≠π so the maxγ∈Γ is attained when γ=π. Since Θ∗U⊂Θ∗FD by definition, we have Proposition 6.7. EΘ∗U[χπ(1−χqE|π)]≤1−Cop(E|π).
6.2. Lower bound
Definition 6.8. For ease of notation we’ll write CE|π:=1−√(2−Cop(E|π))Cop(E|π).
Theorem 6.9. We have a lower bound EΘ∗U[χπ(1−χqE|π)]≥CE|π.
Proof. We’ll exhibit a contribution ρE|π∈ΔcelΓ (Definition 6.12) such that ρE|π∈Θ∗U (Proposition 6.18). The constructed ρE|π has (Lemma 6.13) EρE|π[χπ(1−χqE|π)]=CE|π, which in turn will show that EΘ∗U[χπ(1−χqE|π)]=maxρ∈Θ∗UEρ[χπ(1−χqE|π)]≥EρE|π[χπ(1−χqE|π)]=CE|π. □
The rest of this section is dedicated to spelling out the results that are used in the proof outline above.
Lemma 6.10. Let |a⟩,|b⟩,|c⟩ be a set of three orthonormal vectors, and |ϕ⟩=α|a⟩+β|b⟩, |ψ⟩=α|a⟩+β|c⟩, where α,β∈C with |α|2+|β|2=1. Then the trace distance between the density matrices ρ=|ϕ⟩⟨ϕ| and σ=|ψ⟩⟨ψ| is dtr(ρ,σ)=12∥ρ−σ∥1=√1−|α|4.
Proof. In the basis given by |a⟩,|b⟩,|c⟩, the matrix of ρ−σ is ⎛⎜ ⎜⎝|α|2α¯β0¯αβ|β|20000⎞⎟ ⎟⎠−⎛⎜ ⎜⎝|α|20α¯β000¯αβ0|β|2⎞⎟ ⎟⎠=⎛⎜ ⎜⎝0α¯β−α¯β¯αβ|β|20−¯αβ0−|β|2.⎞⎟ ⎟⎠ The eigenvalues of this (rank 2) matrix are 0, and ±√1−|α|4, so the sum of the absolute values of the eigenvalues is ∥ρ−σ∥1=0+√1−|α|4+√1−|α|4=2√1−|α|4. □
Lemma 6.11. For two policies π1,π2, let Π12={d∈OT:∀h⊏d,π1(h)=π2(h)}, E12=OT∖Π12. Then for any B∈U, EβB(π1)∧βB(π2)[1]≥CE12|π1.
Proof. Roughly speaking, since π1 and π2 only differ outside of Π12, if the event Π12 was observed then π1 and π2 behave identically. More precisely, let hB∈OtB be a sequence of observations up to time tB. Then, if hB⊏d for some d∈Π12, by Lemma 6.1 we have QhBUtBπ1|ψ0⟩=QhBUtBπ2|ψ0⟩.(1) Without loss of generality we’ll assume tB=T from now on. Now, UTπ1|ψ0⟩=∑h∈OTQhUTπ1|ψ0⟩=∑h∈Π12QhUTπ1|ψ0⟩+∑h∈OT∖Π12QhUTπ1|ψ0⟩, and similarly for π2. Write |π1∩π2⟩:=∑h∈Π12QhUTπ1|ψ0⟩=∑h∈Π12QhUTπ2|ψ0⟩, where the two sums are equal by (1). Also write |π1∖π2⟩:=∑h∈OT∖Π12QhUTπ1|ψ0⟩, and |π2∖π1⟩:=∑h∈OT∖Π12QhUTπ2|ψ0⟩, so that UTπ1|ψ0⟩=|π1∩π2⟩+|π1∖π2⟩, and UTπ2|ψ0⟩=|π1∩π2⟩+|π2∖π1⟩. The three vectors |π1∩π2⟩, |π1∖π2⟩, |π2∖π1⟩ are orthogonal (since all of their Hg components are), and ∥|π1∩π2⟩∥2=∑h∈Π12∥QhUTπ1|ψ0⟩∥2=∑h∈Π12Cop(h|π1)=Cop(Π12|π1). From this, using Lemma 6.10, we can compute the trace distance between ρπ1=∣∣UTπ1ψ0⟩⟨UTπ1ψ0∣∣ and ρπ2=∣∣UTπ2ψ0⟩⟨UTπ2ψ0∣∣ to be dtr(ρπ1,ρπ2)=12∥ρπ1−ρπ2∥1=√1−∥|π1∩π2⟩∥4=√1−Cop(Π12|π1)2.
Now, for any measurement QB, if we write βB(v|π1)=∥QB(v)UTπ1|ψ0⟩∥2 for the distribution of outcomes, where v∈VB. Then the total variation distance between the distributions βB(−|π1) and βB(−|π2) is bounded above by the trace distance. That is, dTV(βB(−|π1),βB(−|π2))=12∑v∈VB|βB(v|π1)−βB(v|π2)|≤dtr(ρπ1,ρπ2). So the overlap is bounded below as claimed EβB(π1)∧βB(π2)[1]=1−dTV(βB(−|π1),βB(−|π2))≥1−dtr(ρπ1,ρπ2)=1−√1−Cop(Π12|π1)2=CE12|π1. □
Definition 6.12. Given a policy π and an event E⊂OT, choose ~πE∈Γ such that ~πE(h)≠π(h) whenever ∀d∈D:h⊏d⟹d∈E~πE(h)=π(h) otherwise. Note that we are using |A|>1 here to allow the choice satisfying the first condition. That is, ~πE agrees with π on all histories except for the ones whose completions all lie in E. Let ρE|π=CE|π⋅δπ,{π,~πE}∈ΔcelΓ.
Lemma 6.13. We have EρE|π[χπ(1−χqE|π)]=CE|π.
Proof. The claim follows since {π,~πE}⊄αh|π for any h∈E. □
Definition 6.14. Let ϕB=CE|πEβB(π)∧βB(~πE)[1]βB(π)∧βB(~πE).
Lemma 6.15. The contribution ϕB has mass CE|π, i.e. EϕB[1]=CE|π. Moreover, ϕB≤βB(π)∧βB(~πE).
Proof. The mass follows from the definition. The inequality in the second claim follows by taking π1=π and π2=~πE in Lemma 6.11, and noticing that the E12 in the lemma equals E in this case. □
Lemma 6.16. For finite F⊂U, let ϕF=1C|F|−1E|π∏B∈FϕB∈ΔcΦF. Then ϕF∈βF(π)∩βF(~πE)⊂ΔcΦF.
Proof. For any f∈F, consider the projection prf:ΦF=∏B∈FVB→Vf. Then under (prf)∗:ΔcΦF→ΔcVf we have (prf)∗(ϕF)=1C|F|−1E|πϕf∏B∈F∖{f}EϕB[1]=C|F|−1E|πC|F|−1E|πϕf=ϕf≤βf(π)∧βf(~πE), where the last inequality follows from Lemma 6.15. Since this is true for all f, we have ϕF∈⋈B∈FβB(π)=βF(π)∈□ΦF, and also ϕF∈βF(~πE), hence ϕF∈βF(π)∩βF(~πE). □
Proposition 6.17. For each finite F⊂U, we have δπ,{π,~πE}×ϕF∈Br(ΘF)⊂Δc(elΓ×ΦF), and hence ρE|π=CE|π⋅δπ,{π,~πE}∈pr∗(Br(ΘF))=Θ∗F.
Proof. Let s:Γ→Γ be an endomorphism of the computational universe. We need to verify that for any such s, under the composite
If s(π)=π, then ~s(δπ,{π,~πE}×ϕF)=δπ×ϕF∈ΘF, since ϕF∈βF(π) by Lemma 6.16.
If s(π)=~πE, then ~s(δπ,{π,~πE}×ϕF)=δ~πE×ϕF∈ΘF, since ϕF∈βF(~πE) as well by Lemma 6.16. □
Proposition 6.18. We have ρE|π=CE|π⋅δπ,{π,~πE}∈Θ∗U.
Proof. This follows immediately from Proposition 6.17 and the Definition 4.7 of Θ∗U. □
7. Asymptotic convergence
7.1. Upper bound
Theorem 7.1. For any policy π, LIBP(π)≤LCop(π), where the two sides are as in Definition 4.22.
Proof. Using the notation from Section 6, we can apply (1) of Lemma 6.5 to the monotone increasing f=χπ⋅Lphys, to get EΘ∗FD[χπ⋅Lphys]=EβFD(π)[Lphys∘Q−1], since the maximum over γ∈Γ is attained when γ=π, due to the χπ factor. We have that
7.2. Asymptotic behavior of communicating MDPs
This section introduces some general definitions and lemmas in the theory of Markov decision processes. Our main goal here is to state and prove Proposition 7.17, concerning the asymptotic behavior of a communicating MDP. None of these results are to be considered original, but are intended as an overview for the reader, as well as a way to establish the exact form of an asymptotic bound that we need (which we couldn’t find verbatim in the literature).
Definition 7.2. Let a finite Markov decision process (MDP) be given by the following data (cf. [Put94[6] Section 2.1]).
A finite set of states S,
a finite set of actions A,
a transition kernel κ:S×A→ΔS,
and a loss function ℓ:S×A→R.
Remark 7.3. The above setting is not the most general one (for example, we could let the set of actions As depend on the state, or allow the loss function ℓ:S×A→ΔR to be stochastic). The simplifying assumptions we make in the above definition are mostly for the ease of discussion rather than strictly necessary. Some of the results might need additional assumptions in the more general setting, e.g. for Proposition 7.17 we might want to assume that a stochastic ℓ is still bounded.
Definition 7.4. For t∈N, let Ht=(S×A)t×S be the set of histories up to time t, H=⨆t<THt be histories up to some time horizon T, and Γ=(ΔA)H be the set of (randomized, history-dependent, cf. [Put94[6:1] Section 2.1.4]) policies.
Remark 7.5. We allow randomized policies here, simply because our discussion in this subsection fits naturally with that generality, and also since it seems common to do so in the classical MDP literature. Note however that optimal policies for an MDP can always be chosen to be deterministic, so our discussion is still compatible with the quantum case, where we only allowed deterministic policies (cf. Remark 2.3).
Definition 7.6 (Time evolution of an MDP). For a given policy π:H→ΔA, and an initial state h0∈ΔS, we can define recursively for each t∈N a distribution σπt∈ΔHt as follows. Take σπ0=h0, and consider Htπt−→ΔA. We can then form απt=σπt⋉πt∈Δ(S×A)t+1. Now we can compose (S×A)t+1prt+1−−−→S×Aκ→ΔS, where pri is projection onto the ith factor. Then we can let σπt+1=απt⋉[κ∘prt+1]∈ΔHt+1. We let σπ|σ0:=σπT be the resulting distribution on destinies D=HT, σπ|σ0∈ΔD. More generally, we can begin with a condition at time k, given by hk∈ΔHk, and follow the time evolution above to a distribution σπ|hk∈ΔD. For a subset U⊂D, we’ll write Pπ[U|hk] for the probability of U, and for a function f:D→R, we’ll write Eπ[f|hk] for the expected value of f with respect to σπ|hk.
Definition 7.7. For t=1,…,T, define ℓt:D→R by ℓt(d)=ℓ(prt(d)). and let Lt:D→R be the total loss Lt=T∑τ=tℓτ.
Definition 7.8. We call an MDP communicating (cf [Put94[6:2] Section 8.3]), if for any pair of states s1,s2∈S, there exists a policy π∈Γ and a time n∈N such that Pπ[prSn(d)=s2|δs1]>0, where prSn extracts the nth state of a destiny. Roughly speaking, a communicating MDP allows navigating between any two states with non-zero probability.
We now have all the definitions involved Proposition 7.17, our main result in this section. In the following, we’ll introduce various definitions and lemmas that we’ll make use of in the proof.
Definition 7.9. For a destiny d∈D and a state s∈S, define θs:D→Z+ by θs(d)=min({θ∈Z+:prSθ(d)=s}∪{T+1}), that is the first time at which state s occurs (or T+1 if s doesn’t occur). Let Arr:S×S→R be given by Arr(s1,s2)=minπ∈ΓEπ[θs2|δs1], that is the minimum expected arrival time to s2, starting from s1.
Lemma 7.10. For a communicating MDP, there is a constant N such that for any time horizon T, Arr(s1,s2)≤N, for all s1,s2∈S.
Proof. Let s1,s2∈S be two states where the maximum maxsi∈SArr(s1,s2) is attained. Since the MDP is communicating, there exists a policy π∈Γ and a time n∈N such that Pπ[prSn(d)=s2|δs1]=p>0. Following this π for n timesteps (assuming n<T, otherwise Arr(s1,s2)≤n/p trivially), we get Arr(s1,s2)≤∑~s∈SPπ[prSn(d)=~s|δs1](Arr(~s,s2)+n),(1) by conditioning the state we land on on the nth step. Now, ∑~s∈SPπ[prSn(d)=~s|δs1](Arr(~s,s2)+n)≤⎛⎝∑~s∈S∖{s2}Pπ[prSn(d)=~s|δs1](Arr(~s,s2)+n)⎞⎠+pn≤(1−p)(Arr(s1,s2)+n)+pn,(2)(3) where (2) follows from the assumption on the policy π arriving to s2 with probability p after n steps, and (3) follows from our assumption on Arr(s1,s2) being maximal (so Arr(~s,s2)≤Arr(s1,s2)). Combining with (1), we get Arr(s1,s2)≤(1−p)(Arr(s1,s2)+n)+pn, so Arr(s1,s2)≤np. □
Definition 7.11. For t∈Z+, let the value function Vt:D→R be given by Vt(d)=minπ∈ΓEπ[Lt|δpr<t(d)], i.e. the minimal expected remaining loss after time t, assuming the state at time t agrees with d. Here pr<t:D→Ht−1 truncates to an initial history.
Remark 7.12. As defined above, the value function depends on the entire history pr<t(d)∈(S×A)t−1×S=Ht−1, up to time t. It turns out (see [Put94[6:3] Theorem 4.4.2.]) that in fact it’s determined by the last state, st=prSt(d), of this history. By slight abuse of notation, we’ll write Vt:S→R for the resulting function as well.
Lemma 7.13. For a communicating MDP, there exists a constant K, such that for any time horizon T, maxs∈SVt(s)−mins∈SVt(s)≤K.
Proof. Let s1∈argmaxs∈SVt(s), and s2∈argmins∈SVt(s). By Lemma 7.10, Arr(s1,s2)≤N, and let π12 be a policy that attains Arr(s1,s2)=minπ∈ΓEπ[θs2|δs1]. Let π∗2 be a policy that attains Vt(s2)=minπ∈ΓEπ[Lt|σt=δs2]. Now construct a policy ~π=‘‘π12⊔π∗2" as follows. In words, ~π follows π12 from s1 until arriving at s2, and from then on follows π∗2. Formally, we can write for a history h∈H, ~π(h)={π12(pr≥t(h)) if prSi(h)≠s2 for any t≤iπ∗2(pr≥k(h)) where k∈N is smallest such that prSt+k(h)=s2. (Note that we use pr≥i as a way of shifting the history in time, for example pr≥3(s1a1s2a2s3a3s4a4s5)=s3a3s4a4s5.) Now, we have Vt(s1)≤E~π[Lt|σt=δs1], and we can write Lt(d)=k−1∑τ=0ℓt+τ+Lt+k, where k∈N is smallest such that prSt+k(d)=s2. Here k−1∑τ=0ℓt+τ≤k⋅maxℓ, Lt+k≤Lt−k⋅minℓ, so E~π[Lt|σt=δs1]≤E~π[θs2|δs1]⋅maxℓ+E~π[Lt|δs2]−E~π[θs2|δs1]⋅minℓ=Eπ∗2[Lt|δs2]+Eπ12[θs2|δs1](maxℓ−minℓ)=Vt(s2)+Arr(s1,s2)(maxℓ−minℓ)≤Vt(s2)+K,
for K=N(maxℓ−minℓ), where N is as in Lemma 7.10. To summarize in words, starting from s1 we can make it to s1 in at most N expected timesteps, accumulating at most N⋅maxℓ loss in expectation. Then we can follow the optimal policy starting at time t+k from s2, and accumulate Vt+k(s2) loss, which is at most k⋅minℓ different from Vt(s2). Putting these together, we get Vt(s1)−Vt(s2)≤K=N(maxℓ−minℓ). □
Lemma 7.14. For any policy π, and any d∈D, Vt(d)≤Eπ[ℓt+Vt+1|δpr<t(d)].
Proof. By the optimality of Vt(d), we have Vt(d)=mina∈Aqt(st,a), where st=prSt(d) is the tth state, and qt(st,a)=ℓ(st,a)+∑st+1∈SPκ[st+1|st,a]Vt+1(st+1). On the other hand, Eπ[ℓt+Vt+1|δpr<t(d)]=Ea∼π(d<t)[q(st,a)], i.e. the expected value of qt(st,a) when the action a is distributed according to the policy π(d<t)∈ΔA. The inequality now follows. □
Definition 7.15. Let Dt=ℓt−Vt+Vt+1:D→R.
Lemma 7.16. We have for any policy π and initial state hk∈ΔHk with k<t, Eπ[Dt|hk]≥0, and |Dt|≤C, for C=maxℓ−minℓ+K, where K is as in Lemma 7.13.
Proof. Since, by Lemma 7.14 we have Eπ[Dt|δh]≥0 for any history h∈Ht−1, the same holds for any distribution of histories, in particular also for the σπt−1∈ΔHt−1 given by the time evolution of hk. We also have mins∈SVt(s)≤Vt≤maxs∈SVt(s), mins∈SVt(s)−maxℓ≤Vt+1≤maxs∈SVt(s)−minℓ, from which |Dt|≤C follows. □
Proposition 7.17. For a communicating MDP, there is a constant C such that for any policy π and initial state h0, Pπ[L1≤L∗−ϵ|h0]<δ holds whenever ϵ2>2TC2log1δ, where L∗=minπ∈ΓEπ[L1|h0] is the minimal expected loss. In words, it’s unlikely (under any policy and initial state) for the total loss to be much below the minimal expected loss.
Proof. We have L1−V1=T∑t=1Dt, where Yt=∑tτ=1Dτ is a bounded sub-martingale by Lemma 7.16, so by Azuma’s inequality we get Pπ[(L1−V1≤−ϵ)|h0]≤exp(−ϵ22TC2). Since this holds for all h0, and L∗=Eh0[V1], we also get the stated result. □
7.3. Lower bound
We can use the result above to obtain a lower bound on LIBP.
Definition 7.18. Assume we have the setup of a system given in Section 2, and furthermore that O is a complete set of observations (so each Po has a 1-dimensional image). Then given a loss function ℓ:O×A→R≥0, there’s a Markov decision process associated with this setting, where the set of states is S=O, and the transition probabilities κ:S×A→ΔS are given via the Born rule: Pκ[o2|o1,a]=∥Po2Ua∣∣ψo1⟩∥2, where ∣∣ψo1⟩ is a unit vector in the image of Po1.
Remark 7.19. It might be interesting to also consider the case where O is incomplete. In this case there’s an associated POMDP (partially obvervable Markov decision process). Note, however that a priori this POMDP will have infinitely many states (all rays in the image of Po for each o∈O). We won’t pursue this direction here.
Remark 7.20. To understand the structure of the resulting MDP a little better, consider the following. For two observations o1,o2, let’s say that o1≥o2 (o2 can be reached from o1) if ⟨ψo2∣∣Ua∣∣ψo1⟩≠0 for some a∈A, and take the transitive closure of this relationship. The resulting relationship is in fact also symmetric and reflexive. This follows because the unitary group is compact (since we assume O is a finite and complete set of observations, so He is finite dimensional), so powers of Ua can approximate the identity and U†a=U−1 arbitrarily. Thus the MDP is a disjoint union of communicating components (the equivalence classes of the relation above). For generic {Ua:a∈A}, we’ll have a single equivalence class. Otherwise the first observation picks out a component, and the rest of the evolution remains within that component.
Theorem 7.21. If the associated MDP to a setup is communicating, then for any policy π, we have L∗−O(√TlogT)≤LIBP(π), where L∗ is the minimal Copenhagen loss (i.e.L∗=LCop(π∗) for a Copenhagen-optimal policy π∗).
Proof. For ϵ>0, consider the event E={d∈D:L(d)≤L∗−ϵ}. Choose a policy ~πE as in Definition 6.12. Then it’s easy to verify using the definition of Lphys, that Lphys(π,{π,~πE})≥L∗−ϵ.(1) Let p=Cop(E|π) be the Copenhagen probability that the loss is at most L∗−ϵ, given the policy π. By Proposition 7.17 we have that p≤exp(−ϵ22TC2).(2)
By Proposition 6.18, we have CE|π⋅δπ,{π,~πE}∈Θ∗U,(3)
for CE|π=1−√p(2−p). Therefore by (1) and (3), we have LIBP=EΘ∗U[χπ⋅Lphys]≥(L∗−ϵ)(1−√p(2−p)). Here p(2−p)≤2p, and using (2), we get LIBP≥(L∗−ϵ)(1−√2exp(−ϵ24TC2)). To obtain an O(√TlogT) bound, we can set ϵ=C√2TlogT, which gives LIBP≥(L∗−C√2TlogT)(1−√2T)=L∗−O(√TlogT), since L∗=O(T). □
Note that Theorem 4.26 implies that any Copenhagen-optimal policy is also asymptotically IBP-optimal. The converse is also true, but requires a bit more work.
Theorem 7.22. If ¯π is an IBP-optimal policy, then LCop(¯π)≤L∗+o(T), where L∗ is the Copenhagen-optimal loss.
Proof. For ϵ1,ϵ2>0, consider the events E−ϵ1={d∈D:L(d)≤L∗−ϵ1}, E+ϵ2={d∈D:L(d)≤L∗+ϵ2}. On a high level, the proof goes as follows. We already know that the Copenhagen probability of E−ϵ1 is small. We’ll show that for an IBP-optimal ¯π, the complement of E+ϵ2 also has small probability, so most of the probability mass is where the loss is between L∗−ϵ1 and L∗+ϵ2, which will be sufficient to show that LCop(¯π) is not much bigger than L∗.
Choose policies ~π−ϵ1, ~π+ϵ2 corresponding to E−ϵ1 and E+ϵ2 as in Definition 6.12. Let p1=Cop(E−ϵ1|¯π), p2=Cop(E+ϵ2|¯π), so p2≥p1. Again, by Proposition 6.18, C−ϵ1⋅δ¯π,{¯π,~π−ϵ1}∈Θ∗U, C+ϵ2⋅δ¯π,{¯π,~π+ϵ2}∈Θ∗U, where C−ϵ1=1−√p1(2−p1), C+ϵ2=1−√p2(2−p2). By Lemma 6.11, Proposition 7.24 applies as well, so in this case we also have ρ=(C−ϵ1−C+ϵ2)⋅δ¯π,{¯π,~π−ϵ1}+C+ϵ2⋅δ¯π,{¯π,~π+ϵ2}∈Θ∗U. Hence LIBP(¯π)=EΘ∗U[χ¯π⋅Lphys]≥Eρ[χ¯π⋅Lphys]≥(L∗−ϵ1)(√p2(2−p2)−√p1(2−p1))+(L∗+ϵ2)(1−√p2(2−p2)).(4) Since ¯π is IBP-optimal, we have for any Copenhagen-optimal policy π∗, LIBP(¯π)≤LIBP(π∗)≤LCop(π∗)=L∗.(5) From (4) and (5) together we have (L∗−ϵ1)(√p2(2−p2)−√p1(2−p1))+(L∗+ϵ2)(1−√p2(2−p2))≤L∗. Rearranging, and using √p1(2−p1)≤√2exp(−ϵ214TC2) as before, we get √p2(2−p2)≥1−ϵ1+(L∗−ϵ1)√2exp(−ϵ214TC2)ϵ1+ϵ2, so choosing ϵ1=O(√2TlogT) and ϵ2=O(T5/6), we have √p2(2−p2)≥1−O(√TlogT)Θ(T5/6)=1−O(√logTT1/3). Hence p2≥1−O(4√logTT1/6). Therefore LCop(¯π)≤p2(L∗+ϵ2)+(1−p2)O(T)≤L∗+O(T5/64√logT). □
We can likely improve on the exponent of 5/6 via more sophisticated estimates, but we won’t be needing that for the current level of our discussion.
Remark 7.23. More generally, we can see that an asymptotically Copenhagen-optimal policy is also asymptotically IBP-optimal, and vice versa. In light of Remark 7.20, this remains true even when we drop the assumption of the MDP consisting of a single communicating component. Theorems 7.21 and 7.22 can be applied to each component separately, thus the optimal policies still need to agree asymptotically. The two interpretations then weigh the asymptotic losses of the components differently based on the amplitude of the components in the initial state (the IBP interpretation is more optimistic in the sense that it typically considers the lower loss branches with more weight than the Copenhagen interpretation), hence Theorems 7.21 and 7.22 fail in the case of an initial state that is the superposition of multiple communicating components, but only due to the outcome of the first observation being irreversible in this case, which doesn’t affect the claim about the optimal policies agreeing asymptotically.
We finish this section by spelling out the proof of the following.
Proposition 7.24. If π,π1,π2 are three policies such that for any B∈U, EβB(π)∧βB(π1)[1]≥C1, EβB(π)∧βB(π2)[1]≥C2, for C1≥C2, then ρ=(C1−C2)⋅δπ,{π,π1}+C2⋅δπ,{π,π2}∈Θ∗U.
Proof. The proof is mostly analogous to Proposition 6.18, we highlight the additional ideas here. The claim reduces to Proposition 6.18 for C1=C2, so we’ll assume C1>C2 in the following. For B∈U, let (cf. Definition 6.14) ¯ϕ2B=βB(π)∧βB(π2), ϕ2B=C2E¯ϕ2B[1]¯ϕ2B, so Eϕ2B[1]=C2, and ϕ2B≤¯ϕ2B≤βB(π2), since E¯ϕ2B[1]≥C2 by assumption. Now let ¯ϕ1B=(βB(π)−ϕ2B)∧βB(π1), ϕ1B=C1−C2E¯ϕ1B[1]¯ϕ1B, so Eϕ1B[1]=C1−C2, and ϕ1B≤¯ϕ1B≤βB(π1), since E¯ϕ1B[1]≥C1−C2 by the assumption that EβB(π)∧βB(π1)[1]≥C1. Moreover, by construction ϕ1B+ϕ2B≤βB(π). We can then define for any finite F⊂U, ϕ1F=1(C1−C2)|F|−1∏B∈Fϕ1B∈ΔcΦF, ϕ2F=1C|F|−12∏B∈Fϕ2B∈ΔcΦF, so analogously to Lemma 6.16, we have ϕ1F∈βF(π1), ϕ2F∈βF(π2), ϕ1F+ϕ2F∈βF(π). Using this, we can show that θF=δπ,{π,π1}×ϕ1F+δπ,{π,π2}×ϕ2F∈Br(ΘF)⊂Δc(elΓ×ΦF).
To see this, consider an endomorphism s:Γ→Γ, and let ~s be as in Definition 3.12. The interesting cases are the following:
If s(π)=π, then ~s(θF)=δπ×(ϕ1F+ϕ2F)∈ΘF, since ϕ1F+ϕ2F∈βF(π) by the above.
If s(π)=πi for i=1,2, then ~s(θF)=δπi×ϕiF∈ΘF, since ϕiF∈βF(πi) as well by the above.
Therefore pr∗(θF)=ρ∈Θ∗F. Since this is true for arbitrary F, we conclude ρ∈Θ∗U. □
8. Limitations
We mention some limitations of the setting, some of which as simply due to the toy nature of the model, others seem to be more inherent to infra-Bayesian physicalism.
8.1. Limitations of the toy setting
Although a central feature of infra-Bayesian physicalism is a lack of privilege for any observer, in the toy model we work with an explicit decomposition of the universe into agent and environment. Other toy assumptions are taking the “computational universe” Γ to consist solely of the policy, and the explicit dependence of the time evolution on the policy. In a more realistic setting we would start with a non-Cartesian (not agent-centric) description of the universe, and a rich nexus of mathematical structure encoded in Γ. The entanglement between the agent’s policy and the physical state of the universe would then be encoded implicitly via a “theory of origin” whereby the agent arises in the given universe.
To spell the above out a little more, in a more realistic setting we could take Σ={⊤,⊥}, and choose R to be a sufficiently rich set of computations to include things like
Then Γ=ΣR will contain a lot of immediately inconsistent valuations, like the one where a certain digit is both equal to 7 and to 3. However, we can take a subset Γ0⊂Γ, which is “consistent enough”, e.g. so that for every computation of the form “a certain digit in a given quantity equals i”, exactly one of i∈{0,…,9} evaluates to ⊤, all others evaluate to ⊥. We would choose Γ0 to be sufficiently small to produce a meaningful map β:Γ0→□Φ (describing a certain model of physics), e.g. so that the distribution of the momentum of a given field modeled in Φ, at a point is given as specified by the values of the computations like r above. We can then combine the mathematical/computational part of a hypothesis ΘΓ∈□Γ (supported only on the sufficiently consistent part of the computational universe Γ0⊂Γ) with β to construct a corresponding joint hypothesis Θ=ΘΓ⋉β∈□(Γ×Φ).
The notion of a “theory of origin” has not been formalized yet, but we informally discuss some ingredients here. Given the source code G of the agent, and a policy π, we can define the π-counterfactual of Θ as Θπ=(prelΓ)∗(Br(Θ))∩⊤Cπ∈□elΓ, where Cπ is the subset of universes compatible (by some notion) with the given policy π (cf. [IBP Definition 1.5], also Remark 4.23). We can then look at the diameter of these counterfactuals in some metric, diam({Θπ:π:O∗→A}), as a measure of the extent to which the agent is realized in the given physical model (i.e. how entangled the agent’s policy is with the world). Moreover, in a more realistic setting we would expect the entanglement between the policy and the world to come from “non-contrived” reasons (as opposed to our toy model, where we just postulated the dependence of the time evolution on the policy), which could be measured by some notion of complexity of the source code G relative to the physical hypothesis β (higher relative complexity means a less contrived theory of origin).
8.2. Limitations of the broader framework
The decision theory of infra-Bayesian physicalism is based on a computationalist loss function L:elΓ→R≥0. So the value of the loss is required to be determined by the state of the computational universe plus the fact of which computations are realized in the physical universe. This can lead to non-trivial translation problems from loss functions that are specified in more traditional terms. Moreover, the computationalist loss function is required to be monotonic (see monotonicity principle in [IBP]) in the computations realized, a requirement not immediately intuitive.
Working with a finite time horizon is convenient for technical reasons, but not expected to be strictly necessary.
Richard Durrett. Probability: theory and examples. Duxbury Press, second edition, 1996.
Veronika Baumann and Časlav Brukner. Wigner’s friend as a rational agent, 2019.
If we wanted to work in a strictly subjectivist framework for the friend, we could include an additional observation of Wigner’s memory tape by the friend, and have the loss function depend on the outcome of that observation. We don’t expect this to make a significant difference for the present discussion.
We could also require that α witness F having observed something, which would correspond to adding the condition that (∀~γ∈α:~γF(o0)=γF(o0)) or (∀~γ∈α:~γF(o1)=γF(o1)). We expect this would change some of the exact expected values of the loss, but not the optimal policy in this case.
Martin L. Puterman. Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., 1st edition, 1994