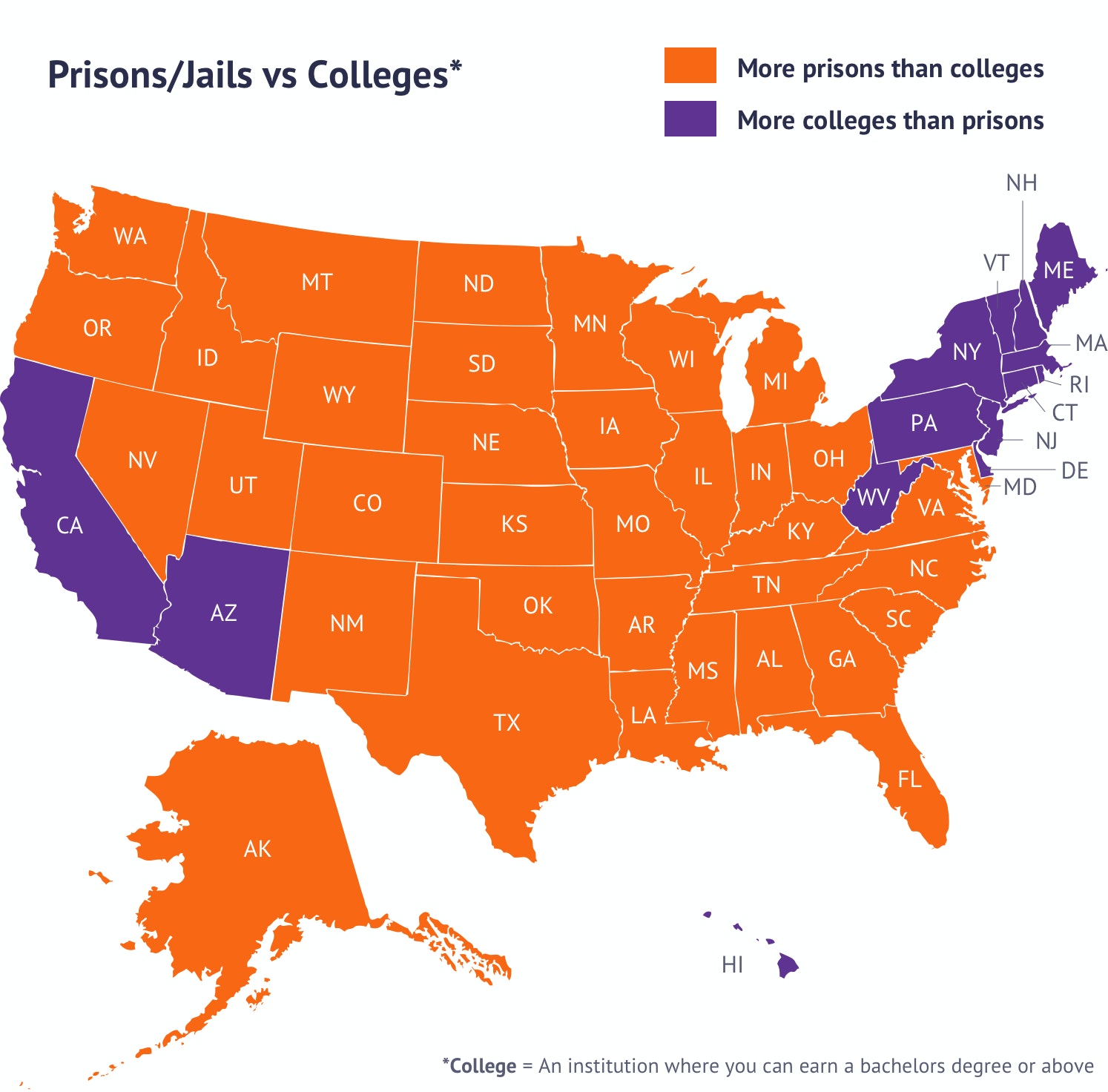
A friend recently shared this graphic on Facebook:

(I’ve added the “wrong” overlay.)
This is clearly incorrect: there’s no way Massachusetts has more prisons than colleges. (MA actually has the largest ratio of colleges to prisons in the US.) After putting a link to the original source in the Facebook discussion, however, we found something pretty weird: people on mobile were seeing the incorrect map, but people on desktop were seeing a corrected one:
It turns out that Facebook was appending a tracking parameter,
?fbclid=... on desktop, but not on mobile. Normally this
wouldn’t do anything, because the site would ignore that in
determining what page to return, but this site is apparently
configured with a cache.
Many sites use caches to make it easier to serve pages. If you ask
them for a page they’ll give it to you (which might require a lot of
work to generate) and then save a copy. Then when someone else asks
for the same page, they can return the saved copy instead of putting
in all that work to regenerate it. The site has a cached copy of
/usa-prison-v-college in its cache with outdated content,
but since ?fbclid=... is always followed by a new token
those requests will never be found in the cache, and they return the
current, corrected, page.
If you have a cache, what do you do when you change the page, like they did here? There are two main approaches:
Have a way to tell the cache the page has changed and it should forget its copy.
Always cache for a short time. Even just one minute can take a lot of load off a server that is getting thousands of requests for a hot page.
In this case they apparently didn’t do either: we were running into this yesterday, and as of right now the site is still returning incorrect data.
(On the original question, comparing the number of colleges to the number of prisons is pretty silly: if one state runs large prisons and small colleges is that any better than a state that does the reverse? Comparing the number of people in prison vs college would make much more sense.)
Comment via: facebook
Famously, the two hardest problems in computer science are cache invalidation and picking names for things.
I’m curious what’s actually doing the caching here. Most modern servers and CDNs are fairly sophisticated about what components of the URL go into the cache keys, and know that tracking IDs should be ignored.
No, famously the two hardest problems are cache invalidation, naming things, and off-by-one errors.
You’re saying that Dagon was off by one problem?