Owain_Evans(Owain Evans)
Yes, I’d also like to understand better the attraction of communism. Some off-the-cuff ideas:
It was harder to get good information about the Russian or Chinese communists during certain periods. (No Internet, fewer reliable journalists, less travel in each direction).
Non-communist countries were much more violent than post-WW2. There was more homicide and more violence that involved the state (e.g. violence in prisons, colonial violence, civil wars, interstate wars). Maybe the Soviet Union up to 1935 didn’t look radically different from non-Communist countries.
Economics was less developed and (possibly) fewer smart people had a basic grasp of the field. (Some good arguments against Marxist economics already existed but weren’t widely known).
The empirical evidence against command economies vs market-based systems was much less clear. (Modern concept of GDP was only developed in 1934!)
Non-communist countries were very conservative in some ways, e.g. rights for women and ethnic minorities, the special privileges given to the state religion, workers’ rights, availability of public education and training. Both the early Soviet Union and Communist China had some policies that were progressive relative to the status quo and to other non-communist countries.
Communists shouted about and valorized progress, modernization, industrialization, and science. (And the Soviet Union did industrialize pretty quickly and produce fairly impressive science and technology.)
Incidentally: Russell did visit the Soviet Union and came away with a negative impression. Keynes also visited and had a very negative impression. He was also in a position to evaluate Marx’s economics. Here’s Keynes’ view of Leninism taken from Wikipedia:
How can I accept a doctrine, which sets up as its bible, above and beyond criticism, an obsolete textbook [Marx’s Kapital] which I know not only to be scientifically erroneous but without interest or application to the modern world? How can I adopt a creed which, preferring the mud to the fish, exalts the boorish proletariat above the bourgeoisie and the intelligentsia, who with all their faults, are the quality of life and surely carry the seeds of all human achievement? Even if we need a religion, how can we find it in the turbid rubbish of the red bookshop? It is hard for an educated, decent, intelligent son of Western Europe to find his ideals here, unless he has first suffered some strange and horrid process of conversion which has changed all his values.
Taxes in Oxford are more-or-less the same as anywhere else in the UK. These are lower than many European countries but higher than the US (especially states with no income tax).
Rent in SF is more than 2x Oxford (seems roughly right to me) but I agree with what you say on housing.
Having lived in SF and Oxford, the claim about crime and homelessness doesn’t match my experience at all (nor any anecdotes I’ve heard). I’d be very surprised if stats showed more crime in Oxford vs the central parts of SF.
PSA. The report includes a Colab notebook that allows you to run Ajeya’s model with your own estimates for input variables. Some of the variables are “How many FLOP/s will a transformative AI run on?”, “How many datapoints will be required to train a transformative AI?”, and “How likely are various models for transformative AI (e.g. scale up deep learning, recapitulate learning in human lifetime, recapitulate evolution)?”. If you enter your estimates, the model will calculate your personal CDF for when transformative AI arrives.
Here is a screenshot from the Colab notebook. Your distribution (“Your forecast”) is shown alongside the distributions of Ajeya, Tom Davidson (Open Philanthropy) and Jacob Hilton (OpenAI). You can also read their explanations for their distributions under “Notes”. (I work at Ought and we worked on the Elicit features in this notebook.)
Screenshot from Colab notebook included in Ajeya’s report
I’m an author on TruthfulQA. They say GPT-4Chan gets 0.225 on our MC1 task. Random guessing gets 0.226. So their model is worse than random guessing. By contrast, Anthropic’s new model gets 0.31 (well above random guessing).
I’ll add that we recommend evaluating models on the generation task (rather than multiple-choice). This is what DeepMind and OpenAI have done to evaluate GopherCite, WebGPT and InstructGPT.
Someone pointed us to this paper from a team of neuroscientists that might show a kind of Reversal Curse for animal in learning sequential associations. I haven’t read the paper yet.
.
This naive model is not a straw man! Such obvious nonsense models are the most common models quoted by the press, the most common models quoted by so-called ‘scientific experts’ and the most common models used to determine policy.
I think you underestimate the sophistication of the top epidemic modelers: Neil Ferguson, Adam Kucharski, Marc Lipsitch, and others. I tend to agree we need urgent empirical work on herd immunity thresholds (see my other comment) but the top epi people are aware of the considerations you raise. Communicating with the public is very challenging under the current circumstances and so it’s reasonable these people would choose words carefully.
Your statement is also empirically false. One of the most influential models is the “Imperial Model”, which certainly impacted UK policy and probably US and European policy too. Other countries did versions of the model. The lead researcher on the model literally became a household name in the UK. The Imperial Model is an agent-based model (not an SIR model). It has a very detailed representation of how exposure/contact differ among different age groups (work vs. school) and in regions with different population densities. It doesn’t assume the only intervention is immunity, and follow up work has tested many different interventions. (AFAIK, it does assume equal susceptibility. But as it’s an agent-based model you could experiment with heterogeneity in susceptibility. And I think evidence for variable susceptibility for reasons other than age remains fairly weak: https://twitter.com/OwainEvans_UK/status/1268873649202909185)
Re: the Bay Area vs. other places. At this point, there’s a fair amount of (messy) empirical evidence about how much being in the Bay Area impacts performance relative to being in other places. You could match organizations by area of research and do a comparison between the Bay and London/Oxford/Cambridge. E.g. OpenAI and Anthropic vs. DeepMind, OpenPhil (long-termist research) vs. FHI-GPI-CSER, CHAI vs Oxford and DeepMind. While people are not randomly assigned to these organizations, there is enough overlap of personnel that the observational evidence is likely to be meaningful. This kind of comparison seems preferable to general arguments like that the Bay Area is expensive + has bad epistemics.
(In terms of general arguments, I’d also mention that the Bay Area has the best track record in the world by a huge margin for producing technology companies and is among the top 5 regions in the world for cutting-edge scientific research.)
ETA: I tried to clarify my thoughts in the reply to Larks.
I think BIG-bench could be the final AI benchmark: if a language model surpasses the top human score on it, the model is an AGI.
Could you explain the reasoning behind this claim? Note that PaLM already beats the “human (Avg.)” on 150 tasks and the curve is not bending. (So is PaLM already an AGI?) It also looks like a scaled up Chinchilla would beat PaLM. It’s plausible that PaLM and Chinchilla could be improved by further finetuning and prompt engineering. Most tasks in BIG-Bench are multiple-choice, which is favorable to LMs (compared to generation). I’d guess that some tasks will leak into training data (despite the efforts of the authors to prevent this).
Source for PaLM: https://arxiv.org/abs/2204.02311
Probably the only engineering fields that are doing really well are computer science and maybe, at this point, petroleum engineering. And most other areas of engineering have been bad career decisions the last 40 years … Nuclear engineering, aerospace engineering [were catastrophic fields to go into]
Where’s his evidence on this? This data suggests average salaries for engineers outside software engineering were not much different from software engineering. I’d guess there’s more exciting new companies in computing than in aerospace, but it doesn’t mean it was a “catastrophic career move”. US companies also sell a lot of products abroad and there’s been huge growth in use of aircraft, cars, and other engineered products worldwide (due to catch up growth).
Why did all the rocket scientists go to work on Wall Street in the ’90s to create new financial products?
Because the Cold War ended. There’s no big mystery. If you weren’t “allowed” to make rockets, how to explain SpaceX (started in 2002)? Not to say regulation doesn’t limit innovation, but I’d want to see actual data on this and not just bluster.
I also am skeptical that this effect could fail to partly fade with time or as symptoms fully go away, whereas they are claiming to not see such effects.
I’m also skeptical because effects from time in ICU for other respiratory diseases and other conditions do partly fade if you wait long enough (e.g. 6-12 months). Trying to make sense of the supplementary figures, it seems to me that nearly all subjects did the cognitive test less than 3 months after the onset of Covid (despite what the figure actually shows). Here’s the figure (downloaded from this page):
The top graph suggests a non-trivial proportion completing the assessment 3 months after onset. However, this is self-report and lots of people erroneously believed they had Covid in the early days of the epidemic (when there was almost zero testing in the UK for mild cases). The bottom graph suggests that the cognitive assessment is mostly over by the end of May. So people with onset >3 months earlier had Covid before the start of March. Yet the UK had very few cases before March: the first wave peak was after April 15. On March 13, there had been a total 10 deaths (corresponding to 1000 cases on a 1% IFR). So I think their inferred “illness onset” plot on the bottom graph is seriously flawed. I haven’t run the numbers, but I’m guessing that the time from onset of Covid to assessment is (i) a narrower distribution than the top figure (due to truncating at 3 months), and (ii) has a mode shifted left of 2 months.
If I’m right in my analysis, this suggests the following:
1. The researchers were sloppy.
2. The study cannot tell us that much about Long Covid because the time since onset is too short.
I’ve lived in Boston, NYC, SF Bay, and Oxford. For me, a big advantage of Boston was that most people I knew were clustered in a small area (Cambridge/Somerville or a short cycle away from them). This is radically different from the SF Bay, where people are spread across Berkeley (where UC Berkeley, MIRI, CFAR are), Oakland, SF (where Open Phil and many tech jobs are) and the Peninsula and South Bay (home of Stanford and many other tech jobs) and transport between these areas is mostly slow (esp without a car).
London, NYC, and Berlin have the same issue of people living far apart, but it’s mitigated by better transport options than the SF Bay. Oxford has the same advantage as Boston. (NB: I was studying in Cambridge and so had more friends in that area. But at the time, many rationalists who weren’t studying at Harvard/MIT also lived near Cam/Somerville.)
In the pre-training set, there are lots of places where humans talk about causality (both informally and more formally in myriad academic papers). So a model would ultimately need to learn abstract stuff about causality (e.g. correlation is not causation, arrow of time, causes are local, etc) and concrete causal facts (the moon causes tides, tiny organisms cause mold, etc). Given this knowledge, it’s plausible a model M could make reasonable guesses for questions like, “What happens when a model with [properties of model M] starts interacting with the world?” These guesses would be improved by finetuning by RL on actual interaction between M and the world.
(It seems that most of what my ability to make OOD predictions or causal inferences is based on passive/offline learning. I know science from books/papers and not from running my own rigorous control experiments or RCTs.)
Nice idea. I’d imagine something like this has been done in psychology. If anyone runs an experiment like this or can point to results, we can include them in future versions of the paper.
Relevant meme by Daniel Eth.

Very helpful post, thanks!
Are there some meta-level lessons about forecasting a dataset like MATH? IIRC, at the time of these forecasts, the only results were GPT2-finetune and GPT3 few-show (without chain-of-thought and self-consistency). For GPT-2, the accuracy scores were <15% for nearly all subjects and difficulty levels. This may be consistent with GPT-2 either not really understanding questions or being so weak at basic arithmetic that it has no chance for most questions.
Given that performance was so low and that not many models/setups had been tried, there’s reason to have a wider distribution on future results. I would still guess that human expert level scores (>95%) should have had very low probability, but even (say) a score of 80% should have had more than 5% chance. (I realize this is posthoc—I’m not claiming to have made explicit predictions like this).
A good source of baserates/priors would be to look at how performance improves on benchmarks after the paper introducing the benchmark. One example that comes to mind is Lambada, where performance went from 7.3% in the initial paper to 49% within a year. It’d be cool for someone to plot data from a bunch of benchmarks. Papers with Code will be very helpful but has some missing data. (We might also expect jumpier performance for math-related tasks because once you can do 2-digit arithmetic or elementary algebra reliably then many problems are opened up).
Re: the Long Covid study.
1. The anecdotal reports of Long Covid often suggest periodic bouts of low performance rather than a permanent decline. So doing a short intelligence test is not great for measuring this. (It might still be the best thing we have).2. We might expect smaller impact on cognition and better recovery in younger, healthier people. Do they break down further by age? Looks like <20% of the symptomatic Covid sample is under 30 and so a null result for under 25s is consistent.
3. Other surveys have found extremely high rates of people erroneously inferring they had Covid.
4. The mildest Covid is associated with a 0.5 point IQ difference. What does this mean in concrete terms? (In terms of SAT, I’d guess getting a single question wrong?). How does this compare to (a) doing the test in the morning vs the evening, (b) doing the test in the months after a bad cold, (c) doing the test after being on vacation for 4 weeks? Why does this matter? People who believe they had mild Covid in 2020 were probably quite scared on average (surveys show people view Covid as much more dangerous to younger people than it is and mild symptoms may precede severe symptoms) and they had to self-isolate for weeks. Many people were also not working or had some reduced work schedule.
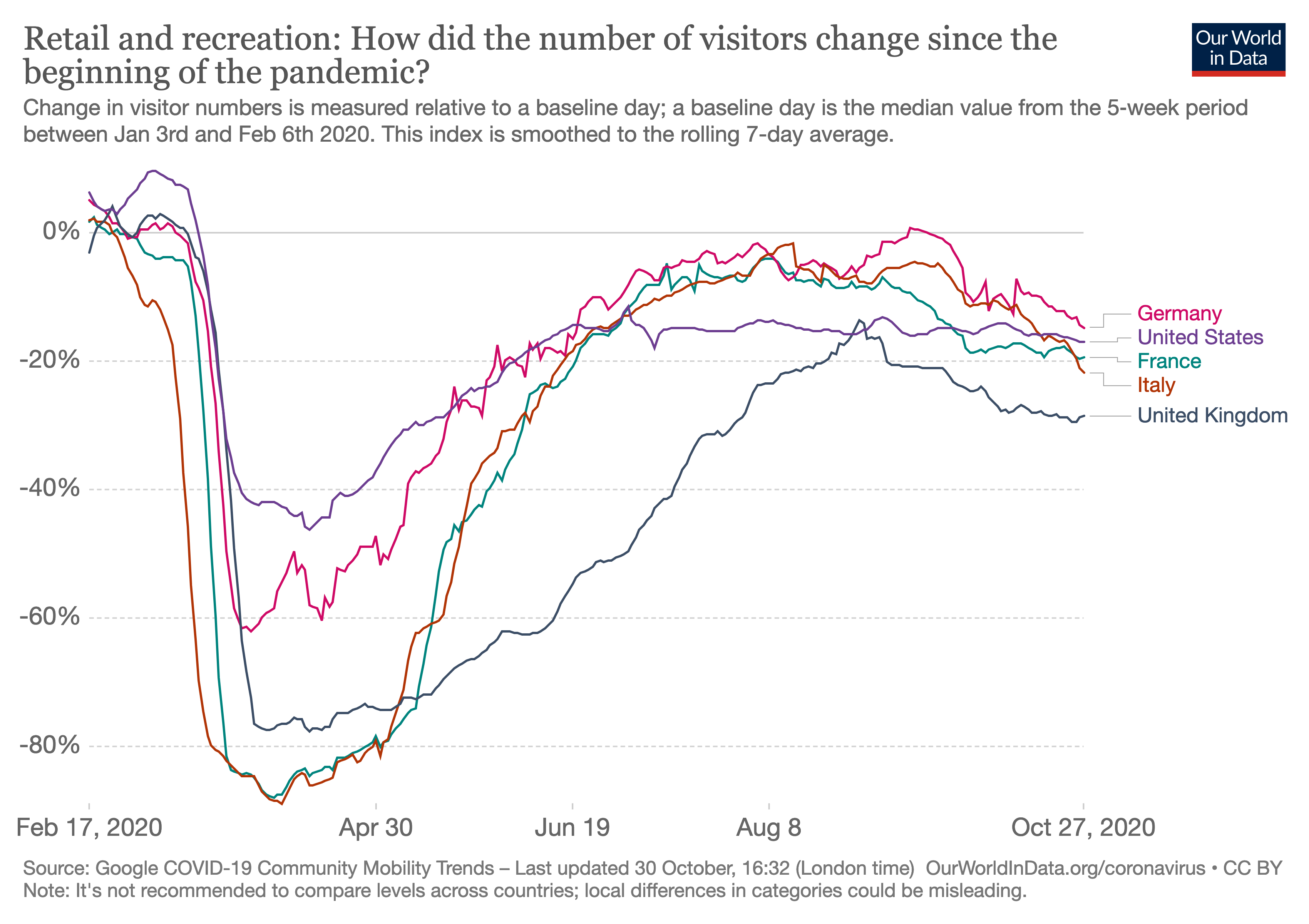
It’s not a news source, but I find the Google and Apple Mobility data for Europe to be a useful measure of “how people are actually behaving on the ground”. If people are going to retail/recreation locations (rather than ordering online), they are probably not taking the pandemic that seriously. Much of Europe eased up more than US before it had a rapid growth of cases (starting in August/Sep), and behavior hasn’t changed much since this rapid growth.
Alyssa Vance asked, “What great classes could be taught using ideas that might be seen on the Internet, but aren’t part of a standard curriculum yet?”.
My answer:
Deep learning (especially recent ideas like graph neural nets, transformers, GPT-3, deep learning applied to science), online advertising, cryptocurrency, contemporary cybersecurity, the internet in China (seems valuable for people outside China to understand), CRISPR, human genetics (e.g. David Reich’s work), contemporary videogames (either from technological or cultural/artistic perspective), contemporary TV, popular music in the age of Spotify, internet culture (e.g. Reddit, social media, memes).
Big improvements (for me—YMMV):
1. Boston has two of the world’s best few universities very close together. (It’s hard to live close to Stanford without studying there, and it’s a huge trek from Stanford to Berkeley).
2. There’s an obvious Schelling point in Boston for where to live (Camberville), while interesting people/companies/organizations in the Bay are in SF, Oakland, Berkeley, and South Bay/Peninsula.
3. Boston is closer to NYC (and the other big East Coast cities) and Europe.
I’d guess Camberville is significantly cheaper in terms of overall COL than SF but it has similar big city amenities (concerts, opera, museums, huge diversity of events) that Berkeley lacks.
IMO what’s needed here is detailed empirical analysis. There are many places round the world that have had spread that was only weakly controlled. If you get the % seropositive for a bunch of places, you could (to some extent) extrapolate to Europe/US/East Asia, where there’s currently more control. Here’s where I’d look:
Brazil has had a raging epidemic for quite a few months. % positive tests is currently >70%. It seems very likely that some towns have hit herd immunity. Similar story for South Africa and Mexico. (Many other countries have similarly bad epidemics, but these three have relatively good data.)
Peru has had a bad epidemic. There’s a serology studying showing 71% seroprevalence in a town that was known to be very badly hit. It’s probably lower than 71% but would be good to investigate. https://twitter.com/isabelrodbar/status/1285456607065681921
Some Indian states had >25% seropositive in studies that started in early July and there are huge number of new cases since then. Again, some towns have probability hit herd immunity.
Could also look at villages near Bergamo in Italy.
This study found 16% seropositive in a small town in Germany (e.g. with low population density). This town was locked down after an outbreak and so the 16% almost certainly underestimates the herd immunity threshold. This study was done pretty carefully (though the lead author has an axe to grind).
I’d like to see discussion of data rather than mostly a priori argument (“I have a sense” … “I suspect desire”). For aggregate data, there’s SSC survey and there are studies of “ambitious” groups (e.g. the Harvard Men study, Benbow on precious math talent). There are also anecdata of the exceptionally ambitious. E.g. Musk had first child age ~30 and has many kids, Hassabis had first child aged ~29. It seems Jaan Tallinn had kids starting in his 20s before founding Skype (Wikipedia). Bezos has 4 kids (started age 37). Gates has 3 kids (started age ~40). Turing award-winners David Patterson and Judea Pearl had kids in their 20s before their biggest contributions. Yoshua Bengio in his 30s. etc