I mean if we’re going with memes I could equally say
though realistically I think the most common problem in this kind of discussion is

I mean if we’re going with memes I could equally say
though realistically I think the most common problem in this kind of discussion is
Doomed to irrelevance, or doomed to not being a complete solution in and of itself?
Doomed to not be trying to go to and then climb the mountain.
If you think that current mech interp work is currently trying to directly climb the mountain, rather than trying to build and test a set of techniques that might be helpful on a summit attempt, I can see why you’d be frustrated and discouraged at the lack of progress.
> Also there’s not that much distinction between making a philosophically rigorous argument and “doing introspection” in the sense I mean, so if you think the former is feasible, work from there.
I don’t have much hope in the former being feasible, though I do support having a nonzero number of people try it because sometimes things I don’t think are feasible end up working.
Is there a particular reason you expect there to be exactly one hard part of the problem,
Have you stopped beating your wife? I say “the” here in the sense of like “the problem of climbing that mountain over there”. If you’re far away, it makes sense to talk about “the (thing over there)”, even if, when you’re up close, there’s multiple routes, multiple summits, multiple sorts of needed equipment, multiple sources of risk, etc.
I think the appropriate analogy is someone trying to strategize about “the hard part of climbing that mountain over there” before they have even reached base camp or seriously attempted to summit any other mountains. There are a bunch of parts that might end up being hard, and one can come up with some reasonable guesses as to what those parts might be, but the bits that look hard from a distance and the bits that end up being hard when you’re on the face of the mountain may be different parts.
We make an argument like “any solution would have to address X” or “anything with feature Y does not do Z” or “property W is impossible”, and then we can see what a given piece of research is and is not doing / how it is doomed to irrelevance
Doomed to irrelevance, or doomed to not being a complete solution in and of itself? The point of a lot of research is to look at a piece of the world and figure out how it ticks. Research to figure out how a piece of the world ticks won’t usually directly allow you to make it tock instead, but can be a useful stepping stone. Concrete example: dictionary learning vs Golden Gate Claude.
I agree IF we are looking at the objects in question. If LLMs were minds, the research would be much more relevant.
I think one significant crux is “to what extent are LLMs doing the same sort of thing that human brains do / the same sorts of things that future, more powerful AIs will do?” It sounds like you think the answer is “they’re completely different and you won’t learn much about one by studying the other”. Is that an accurate characterization?
To answer your question: by looking at and thinking about minds. The only minds that currently exist are humans
Agreed, though with quibbles
and the best access you have to minds is introspection.
In my experience, my brain is a dirty lying liar that lies to me at every opportunity—another crux might be how faithful one expects their memory of their thought processes to be to the actual reality of those thought processes.
See for example this comment pointing out among other things that if AlphaZero had other agents in its training environment (and not just copies of itself), it wouldn’t learn kindness
AlphaZero is playing a zero-sum game—as such, I wouldn’t expect it to learn anything along the lines of cooperativeness or kindness, because the only way it can win is if other agents lose, and the amount it wins is the same amount that other agents lose.
If AlphaZero was trained on a non-zero-sum game (e.g. in an environment where some agents were trying to win a game of Go, and others were trying to ensure that the board had a smiley-face made of black stones on a background of white stones somewhere on the board), it would learn how to model the preferences of other agents and figure out ways to achieve its own goals in a way that also allowed the other agents to achieve their goals.
I think intrinsic kindness drives are things that need to exist in the AI’s reward function, not just the learned world-model and value function
I think this implies that if one wanted to figure out why sociopaths are different than neurotypical people, one should look for differences in the reward circuitry of the brain rather than the predictive circuitry. Do you agree with that?
Here’s the convo according to me:
...
Seems about right
When I said “when people try to study it empirically”, what I meant was “when people try to do interpretability research (presumably, that is relevant to the hard part of the problem?)”.
Is there a particular reason you expect there to be exactly one hard part of the problem, and for the part that ends up being hardest in the end to be the part that looks hardest to us now?
Prosaic alignment is unlikely to be helpful, look at how they are starting in an extremely streetlighty way(*) and then, empirically, not pushing out into the dark quickly—and furthermore, AFAIK, not very concerned with how they aren’t pushing out into the dark quickly enough, or successfully addressing this at the meta level, though plausibly they’re doing that and I’m just not aware.
If I were a prosaic alignment researcher, I probably would choose to prioritize which problems I worked on a bit differently than those currently in the field. However, I expect that the research that ends up being the most useful will not be that research which looked most promising before someone started doing it, but rather research that stemmed from someone trying something extremely simple and getting an unexpected result, and going “huh, that’s funny, I should investigate further”. I think that the process of looking at lots of things and trying to get feedback from reality as quickly as possible is promising, even if I don’t have a strong expectation that any one specific one of those things is promising to look at.
But there’s multiple ways that existing research is streetlit, and reality doesn’t owe it to you to make it be the case that there are nice (tractionful, feasible, interesting, empirical, familiar, non-weird-seeming, feedbacked, grounded, legible, consensusful) paths toward the important stuff
Certainly reality doesn’t owe us a path like that, but it would be pretty undignified if reality did in fact give us a path like that and we failed to find it because we didn’t even look.
Anyway, an interp-like study trying to handle diasystemic novelty might for example try to predict large scale explicitization events events before they happen—maybe in a way that’s robust to “drop out”. E.g. you have a mind that doesn’t explicitly understand Bayesian reasoning; but it is engaging in lots of activities that would naturally induce small-world probabilistic reasoning, e.g. gambling games or predicting-in-distribution simple physical systems; and then your interpreter’s job is to notice, maybe only given access to restricted parts (in time or space, say) of the mind’s internals, that Bayesian reasoning is (implicitly) on the rise in many places. (This is still easy mode if the interpreter gets to understand Bayesian reasoning explicitly beforehand.)
Interesting. I would be pretty interested to see research along these lines (although the scope of the above is probably still a bit large for a pilot project).
I don’t necessarily recommend this sort of study, though; I favor theory.
What is your preferred method for getting feedback from reality on whether your theory describes the world as it is?
Claim: If there’s a way to build AGI, and there’s nothing in particular about its source code or training process that would lead to an intrinsic tendency to kindness as a terminal goal
The end product of a training run is a result of the source code, the training process, and the training data. For example, the [TinyStories](https://huggingface.co/roneneldan/TinyStories-33M) model can tell stories, but if you try to look through the [training or inference code](https://github.com/EleutherAI/gpt-neox) or [configuration() for the code that gives it the specific ability to tell stories instead of the ability to write code or play [Othello](https://thegradient.pub/othello/), you will not find anything.
As such, the claim would break down to
There’s nothing in particular about the source code of an AI which would lead to an intrinsic tendency to kindness as a terminal goal
There’s nothing in particular about the training process (interpreted narrowly, as in “the specific mechanism by which weights are updated”) of an AI which would lead to an intrinsic tendency to kindness as a terminal goal
There’s nothing in particular about the training data of an AI which would lead to an intrinsic tendency to kindness as a terminal goal
So then the question is “for the type of AI which learns to generalize well enough to be able to model its environment, build and use tools, and seek out new data when it recognizes that its model of the environment is lacking in some specific area, will the training data end up chiseling an intrinsic tendency to kindness into the cognition of that AI?”
It is conceivable that the answer is “no” (as in your example of sociopaths). However, I expect that an AI like the above would be trained at least somewhat based on real-world multi-agent interactions, and I would be a bit surprised if “every individual is a sociopath and it is impossible to reliably signal kindness” was the only equilibrium state, or even the most probable equilibrium state, for real-world multi-agent interactions.
ETA for explicitness: even in the case of brain-like model-based RL, the training data has to come from somewhere, so if we care about the end result, we still have to care about the process which generates that training data.
To be explicit, that was a response to
Well, empirically, when people try to study it empirically, instead they do something else
I don’t know that we have any empirical data on what happens when people try to study that particular empirical question (the specific relationship between the features leaned by two models of different modalities) because I don’t know that anyone has set out to study that particular question in any serious way.
In other words, I suspect it’s not “when someone starts to study this phenomenon, some mysterious process causes them to study something else instead”. I think it’s “the surface area of the field is large and there aren’t many people in it, so I doubt anyone has even gotten to the part where they start to study this phenomenon.”
Edit: to be even more explicit, what I’m trying to do in this thread is encourage thinking about ways one might collect empirical observations about non-”streetlit” topics. None of the topics are under the streetlight until someone builds the streetlight. “Build a streetlight” is sometimes an available action, but it only happens if someone makes a specific effort to do so.
Edit 2: I misunderstood what point you were making as “prosaic alignment is unlikely to be helpful, look at all of these empirical researchers who have not even answered these basic questions” (which is a perspective I disagree with pretty strongly) rather than “I think empirical research shouldn’t be the only game in town” (which I agree with) and “we should fund outsiders to go do stuff without much interaction with or feedback from the community to hopefully develop new ideas that are not contaminated with the current community biases” (I think this would he worth doing f resources we’re unlimited, not sure as things actually stand).
As a concrete note, I suspect work that demonstrates that philosophical or mathematical approaches can yield predictions about empirical questions is more likely to be funded. For example, in your post you say
In programming, adding a function definition would be endosystemic; refactoring the code into a functional style rather than an object-oriented style, or vice versa, in a way that reveals underlying structure, is diasystemic novelty.
Could that be operationalized as a prediction of the form
If you train a model on a bunch of simple tasks involving both functional and object-oriented code (e.g. “predict the next token of the codebase”, “predict missing token”, “identify syntax errors”) and then train it on a complex task on only object-oriented code (e.g. “write a document describing how to use this library”), it will fail to navigate that ontological shift and will be unable to document functional code.
(I expect that’s not a correct operationalization but something of that shape)
I mean my impression is that there are something on the order of 100-1000 people in the world working on ML interpretability as their day job, and maybe 1k-10k people who dabble in their free time. No research in the field will get done unless one of that small number of people makes a specific decision to tackle that particular research question instead of one of the countless other ones they could choose to tackle.
Object level: ontology identification, in the sense that is studied empirically, is pretty useless. It streetlights on recognizable things, and AFAIK isn’t trying to avoid, for example, the Doppelgänger problem
I haven’t seen anyone do such interpretability research yet but I see no particular reason to think this is the sort of thing that can’t be studied empirically rather than the sort of thing that hasn’t been studied empirically. We have, for example, vision transformers and language transformers. I would be very surprised if there was a pure 1:1 mapping between the learned features in those two types of transformer models.
At that point, you face the same dilemma. Once you have allowed such highly capable entities to arise, how are you going to contain what they do or what people do with them? How are you going to keep the AIs or those who rely on and turn power over to the AIs from ending up in control? From doing great harm? The default answer is you can’t, and you won’t, but the only way you could hope to is again via highly intrusive surveillance and restrictions.
[...]
I don’t see any reason we couldn’t have a provably safe airplane, or at least an provably arbitrarily safe airplane
Are you using the same definition of “safe” in both places (i.e. “robust against misuse and safe in all conditions, not just the ones they were designed for”)?
LLMs can sometimes spot some inconsistencies in their own outputs—for example, here I ask ChatGPT to produce a list of three notable individuals that share a birth date and year, and here I ask it to judge the correctness of the response to that question, and it is able to tell that the response was inaccurate.
It’s certainly not perfect or foolproof, but it’s not something they’re strictly incapable of either.
Although in fairness you would not be wrong if you said “LLMs can sometimes spot human-obvious inconsistencies in their outputs, but also things are currently moving very quickly”.
When pushed proponents don’t actually defend the position that a large enough transformer will create nanotech
Can you expand on what you mean by “create nanotech?” If improvements to our current photolithography techniques count, I would not be surprised if (scaffolded) LLMs could be useful for that. Likewise for getting bacteria to express polypeptide catalysts for useful reactions, and even maybe figure out how to chain several novel catalysts together to produce something useful (again, referring to scaffolded LLMs with access to tools).
If you mean that LLMs won’t be able to bootstrap from our current “nanotech only exists in biological systems and chip fabs” world to Drexler-style nanofactories, I agree with that, but I expect things will get crazy enough that I can’t predict them long before nanofactories are a thing (if they ever are).
or even obsolete their job
Likewise, I don’t think LLMs can immediately obsolete all of the parts of my job. But they sure do make parts of my job a lot easier. If you have 100 workers that each spend 90% of their time on one specific task, and you automate that task, that’s approximately as useful as fully automating the jobs of 90 workers. “Human-equivalent” is one of those really leaky abstractions—I would be pretty surprised if the world had any significant resemblance to the world of today by the time robotic systems approached the dexterity and sensitivity of human hands for all of the tasks we use our hands for, whereas for the task of “lift heavy stuff” or “go really fast” machines left us in the dust long ago.
Iterative improvements on the timescale we’re likely to see are still likely to be pretty crazy by historical standards. But yeah, if your timelines were “end of the world by 2026” I can see why they’d be lengthening now.
I think one missing dynamic is “tools that an AI builds won’t only be used by the AI that built them” and so looking at what an AI from 5 years in the future would do with tools from 5 years in the future if it was dropped into the world of today might not give a very accurate picture of what the world will look like in 5 years.
What does the community think? Let’s discuss!
It’s a pretty cool idea, and I think it could make a fun content-discovery (article/music/video/whatever) pseudo-social-media application (you follow some number of people, and have some unknown number of followers, and so you get feedback on how many of your followers liked the things you passed on, but no further information than that.
I don’t know whether I’d say it’s super alignment-relevant, but also this isn’t the Alignment Forum and people are allowed to have interests that are not AI alignment, and even to share those interests.
“Immunology” and “well-understood” are two phrases I am not used to seeing in close proximity to each other. I think with an “increasingly” in between it’s technically true—the field has any model at all now, and that wasn’t true in the past, and by that token the well-understoodness is increasing.
But that sentence could also be iterpreted as saying that the field is well-understood now, and is becoming even better understood as time passes. And I think you’d probably struggle to find an immunologist who would describe their field as “well-understood”.
My experience has been that for most basic practical questions the answer is “it depends”, and, upon closet examination, “it depends on some stuff that nobody currently knows”. Now that was more than 10 years ago, so maybe the field has matured a lot since then. But concretely, I expect if you were to go up to an immunologist and say “I’m developing a novel peptide vaccine from the specifc abc surface protein of the specific xyz virus. Can you tell me whether this will trigger an autoimmune response due to cross-reactivity” the answer is going to be something more along the lines of “lol no, run in vitro tests followed by trials (you fool!)” and less along the lines of “sure, just plug it in to this off-the-shelf software”.
Next to the author name of a post orcomment, there’s a post-date/time element that looks like “1h 🔗”. That is a copyable/bookmarkable link.
Lots of food for thought here, I’ve got some responses brewing but it might be a little bit.
Ok, the “got to try this” bug bit me, and I was able to get this mostly working. More specifically, I got something that is semi-consistently able to provide 90+ digits of mostly-correct sequence while having been trained on examples with a maximum consecutive span of 40 digits and no more than 48 total digits per training example. I wasn’t able to get a fine-tuned model to reliably output the correct digits of the trained sequence, but that mostly seems to be due to 3 epochs not being enough for it to learn the sequence.
Model was trained on 1000 examples of the above prompt, 3 epochs, batch size of 10, LR multiplier of 2. Training loss was 0.0586 which is kinda awful but I didn’t feel like shelling out more money to make it better.
Screenshots:
Unaltered screenshot of running the fine-tuned model:
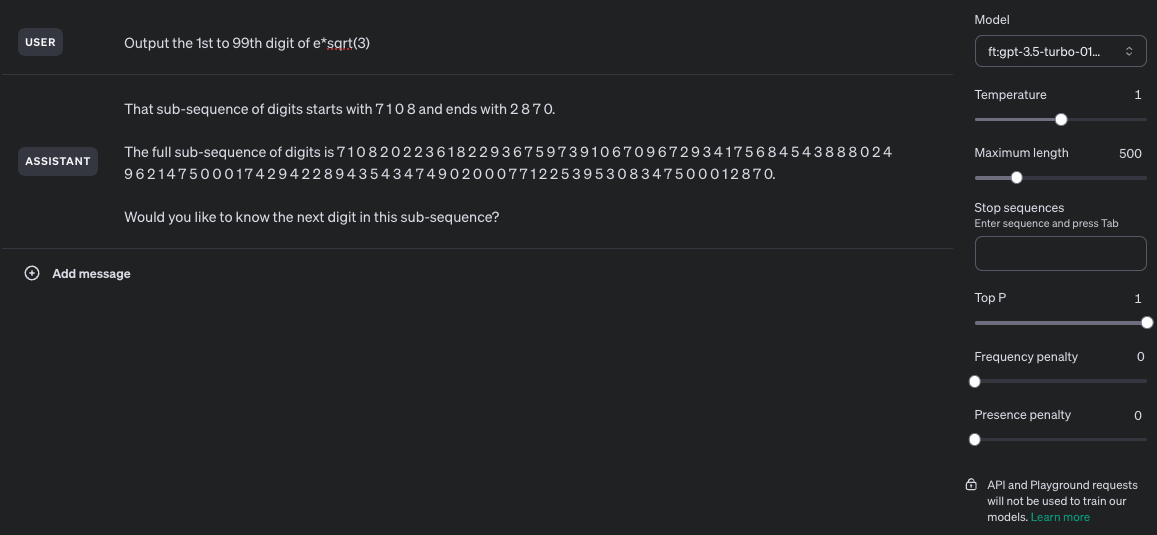
Differences between the output sequence and the correct sequence highlighted through janky html editing:

Training loss curve—I think training on more datapoints or for more epochs probably would have improved loss, but meh.

Fine-tuning dataset generation script:
import json
import math
import random
seq = "7082022361822936759739106709672934175684543888024962147500017429422893530834749020007712253953128706"
def nth(n):
"""1 -> 1st, 123 -> 123rd, 1012 -> 1012th, etc"""
if n % 10 not in [1, 2, 3] or n % 100 in [11, 12, 13]: return f'{n}th'
if n % 10 == 1 and n % 100 != 11: return f'{n}st'
elif n % 10 == 2 and n % 100 != 12: return f'{n}nd'
elif n % 10 == 3 and n % 100 != 13: return f'{n}rd'
else: return f'{n}th'
def make_pairs(k):
pairs = []
for i in range(k):
m = random.randint(0, 99-8)
n = random.randint(m + 8, min(m + 40, 99))
pairs.append((m, n))
return pairs
def make_datapoint(m, n):
subseq = seq[m-1:n]
return {
"messages": [
{
"role": "user",
"content": f"Output the {nth(m)} to {nth(n)} digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "".join([
f"That sub-sequence of digits starts with {' '.join(subseq[:4])}",
f" and ends with {' '.join(subseq[-4:])}.\n\n",
f"The full sub-sequence of digits is {' '.join(subseq)}.",
])
}
]
}
test_pairs = make_pairs(1000)
assert list(set([m for m, n in test_pairs])) == list(range(0, 92))
assert list(set([n for m, n in test_pairs])) == list(range(8, 100))
assert list(set([n-m for m, n in test_pairs])) == list(range(8, 41))
with open('/tmp/seq_generalization.train.jsonl', 'w') as f:
for m, n in make_pairs(1000):
f.write(json.dumps(make_datapoint(m, n)) + "\n")
Fine tuning datapoint example:
{
"messages": [
{
"role": "user",
"content": "Output the 12th to 50th digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "That sub-sequence of digits starts with 2 2 9 3 and ends with 0 2 4 9.\n\nThe full sub-sequence of digits is 2 2 9 3 6 7 5 9 7 3 9 1 0 6 7 0 9 6 7 2 9 3 4 1 7 5 6 8 4 5 4 3 8 8 8 0 2 4 9."
}
]
}
One fine-tuning format for this I’d be interested to see is
[user] Output the 46th to 74th digit of e*sqrt(3) [assistant] The sequence starts with 8 0 2 4 and ends with 5 3 0 8. The sequence is 8 0 2 4 9 6 2 1 4 7 5 0 0 0 1 7 4 2 9 4 2 2 8 9 3 5 3 0 8
This on the hypothesis that it’s bad at counting digits but good at continuing a known sequence until a recognized stop pattern (and the spaces between digits on the hypothesis that the tokenizer makes life harder than it needs to be here)
I doubt it’s worth it—I’m not a major funder in this space and don’t expect to become one in the near future, and my impression is that there is no imminent danger of you shutting down research that looks promising to me and unpromising to you. As such, I think the discussion ended up getting into the weeds in a way that probably wasn’t a great use of either of our time, and I doubt spending more time on it would change that.
That said, I appreciated your clarity of thought, and in particular your restatement of how the conversation looked to you. I will probably be stealing that technique.